我的教育教学随笔
我的教育教学随笔
梓里中学 阮凤书
人人都说教学苦,在古代有“家有五斗米,不做孩子王”的说法。确实,做一个老师挺苦挺累的,做一个好教师就更苦更累了,但这是 我们选择的职业,所以我们要做的只有默默工作。
自成为一名教师以来,己走过十年的风风雨雨,在这十年的教学生涯中,有苦也有甜,有累也有乐,有困也有豁。这些年的工作经验告诉我,教师真挚的爱是启迪学生心灵的钥匙。没有爱就没有教育,只有热爱,才能奉献。我的教学宗旨是:爱而不溺,严而有格,耐心细致,一视同仁。对“好学生”不“一俊遮百丑”;对后进生关心备至,增加感情投入,想法树立他们的自信心,维护他们的自尊心,加之因势利导,使之逐步完善自我。
对学生的要求严格:一是严而有格,就是说对学生的要求有标准,教育方法不出格;二是严中有爱,和学生相处从不借口严格要求,而对学生摆出一副冷面孔,一派咄咄逼人的气派。要知道,一份严格之水,要渗上九份感情之蜜,才能酿成教育的甘露!
“后进生”也有闪光点,关键在于是否发现。学生的一个进步,一次好事,一次较好的作业······都是星星之火,教师及时的肯定、表扬、鼓励,让他们体会到成功的喜悦,这对他们树立自信心是有极大作用的。在课堂上,我总是多给他们表现的机会,如果对了,我会高兴地说:“你聪明”。即使回答不上,我也会给他一个激励的目光。
俗话说:“说破嗓子,不如做出样子”。凡是要求学生做到的教师首先做到。教师要用美好的心灵去教育每一个学生。教师要求学生仪表端正,服装整洁,教师就应该坚持上课前整理穿着;要求学生语言文明,教师在学生面前就不要讲粗话;要求学生说普通话,教师课堂上尽量用生动、优美、简洁、精练的语言去引导学生进入作者的“意境”。这样,不仅陶冶其情操,提高其觉悟,而且也能有效地培养其表达能力。
有人说过这样的一句话:“老师不经意的一句话,可能会创造一个奇迹;老师不经意的一个眼神,也许会扼杀一个人才。”老师习以为平常的行为,对学生终身的发展也许产生不可估量的影响,做一名老师应该经常回顾自己以往的教育历程,反思一下:我造就了多少个遗憾,刺伤了多少颗童心,遗忘了多少个不该遗忘的角落!
对于一个优秀的教师而言,教育不是牺牲,而是享受;教育不是重复,而是创造;教育不仅仅是谋生的手段,而是丰富精彩的生活本身!教师的一生也许终不成什么惊天动地的伟业,但他应像山间的小溪,以乐观的心态一路欢歌,奔向海洋;
第二篇:我的教育统计学笔记
教材:《教育统计学》(王孝玲编著,修订版)华东师范大学出版社 1993年6月第一版
第一章 绪论
第一节 什么是统计学和心理统计学
一、什么是统计学
统计学是研究统计原理和方法的科学。具体地说,它是研究如何搜集、整理、分析反映事物总体信息的数字资料,并以此为依据,对总体特征进行推断的原理和方法。
统计学分为两大类。一类是数理统计学。它主要是以概率论为基础,对统计数据数量关系的模式加以解释,对统计原理和方法给予数学的证明。它是数学的一个分支。另一类是应用统计学。它是数理统计原理和方法在各个领域中的应用,如数理统计的原理和方法应用到工业领域,称为工业统计学;应用到医学领域,称为医学统计学;应用到心理学领域,称为心理统计学,等等。应用统计学是与研究对象密切结合的各科专门统计学。
二、统计学和心理统计学的内容
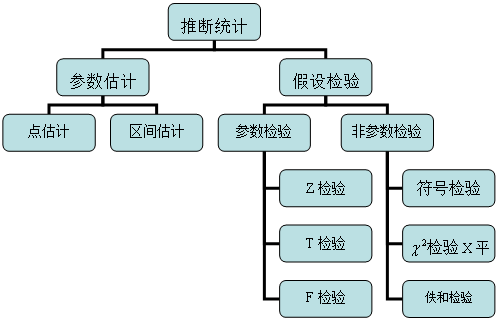
统计学和心理统计学的研究内容,从不同角度来分,可以分为不同的类型。从具体应用的角度来分,可以分成描述统计,推断统计和实验设计三部分。
1.描述统计
对已获得的数据进行整理、概括,显示其分布特征的统计方法,称为描述统计。
2.推断统计
根据样本所提供的信息,运用概率的理论进行分析、论证,在一定可靠程度上,对总体分布特征进行估计、推测,这种统计方法称为推断统计。推断统计的内容包括总体参数估计和假设检验两部分。
3.实验设计
实验者为了揭示试验中自变量和因变量的关系,在实验之前所制定的实验计划,称为实验设计。其中包括选择怎样的抽样方式;如何计算样本容量;确定怎样的实验对照形式;如何实现实验组和对照组的等组化;如何安排实验因素和如何控制无关因素;用什么统计方法处理及分析实验结果,等等。
以上三部分内容,不是截然分开,而是相互联系的。
第二节 统计学中的几个基本概念
一、随机变量
具有以下三个特性的现象,成为随机变量。第一,一次试验有多中可能结果,其所有可能结果是已知的;第二,试验之前不能预料哪一种结果会出现;第三,在相同的条件下可以重复试验。随机现象的每一种结果叫做一个随机事件。我们把能表示随机现象各种结果的变量称为随机变量。统计处理的变量都是随机变量。
二、总体和样本
总体是我们所研究的具有共同特性的个体的总和。总体中的每个单位成为个体。样本是从总体中抽取的作为观察对象的一部分个体。当总体所包含的个数有限时,这一总体称为有限总体。而总体所包含的个数无限时,则称为无限总体。样本中包含的个体数目称为样本的容量,一般用n来表示。一般来说,样本中个体数目大于30称为大样本,等于或小于30称为小样本。在对数据进行处理时,大样本和小样本所用的统计方法不一定相同。
三、统计量和参数
样本上的数据特征是统计量。总体上的各种数字特征是参数。在进行统计推断时,就是根据样本统计量来推断总体相应的参数。
第二章 数据的初步整理
第一节 数据的来源、种类及其分类
一、统计资料的来源
统计资料的来源有两个方面:
1、经常性资料
2、专题性资料:(1)调查资料(2)实验资料
二、数据的种类
数据是随机变量的观察值。它是用来描述对客观事物观察测量的数值。数据的种类不同,统计处理的方法也不同。
根据统计数据来源可分为点计数据和度量数据;按随机变量取值情况,可分为间断性随机变量的数据和连续性随机变量的数据。
1、点计数据和度量数据
点计数据是指计算个数所获得的数据。度量数据是指用一定的工具或一定的标准测量所获得的数据。
2、间断性随机变量的数据和连续性随机变量的数据
取值个数有限的数据,称为间断性随机变量的数据。这种数据的单位是独立的,两个单位之间不能划分成细小的单位,一般用整数表示。取值个数无限的(不可数的)数据,称为连续性随机变量的数据。它们可能的取值范围能连续充满某一个区间。数据的单位之间可以再划分成无限多个细小的单位。数据可以用小数表示。
三、数据的统计分类
数据的统计分类,是指按照研究对象的本质特征,根据分析研究的目的、任务,以及统计分析时所用统计方法的可能性,将所获得的数据进行分组归类。它是对数据进行归纳、整理、简化、概括的第一步,为进一步分析研究打下基础。
分类的标志按形式划分,可分为性质类别和数量类别。性质类别是按事物的不同性质进行分类。这种分类不表明事物之间的差异。性质类别还可以进一步分成不同的层次。数量类别是按数值大小进行分类,并排成顺序。在排列顺序时,可以直接按数值大小进行排列,也可以用等级顺序进行排列。
第二节 统计表
一、统计表的结构及其编制的原则和要求。
统计表一般由标题、表号、标目、线条、数字、表注等项构成。
标题 标题是表的名称,应确切地、简明扼要地说明表的内容。
表号 表号是表的序号。
标目 标目是表格中对统计数据分类的项目。
线条 线条不宜过多。
数字 表内数字必须准确,一律用阿拉伯数字表示,位次对齐,小数的位数一致。
表注 它不是表的必要组成部分。
二、统计表的总类
1、简单表
只列出观察对象的名称、地点、时序或统计指标名称的统计表为简单表。
2、分组表
只按一个标志分组的统计表为分组表。
3、复合表
按两个或两个以上标志分组的统计表为复合表。
三、频数分布表列法
1、简单频数分布表
(1)间断变量的频数分布表
(2)连续变量的频数分布表
步骤:①求全距 ②决定组数和组距 ③决定组限决定组限 ④登记频数
2、累积频数和累积百分比分布表
(1)累积频数分布表
用累积频数表示的频数分布表称为累积频数分布表。
(2)累积百分比分布表
累积百分比分布表是累积频数分布表的变型。它是用累积百分比表示的频数分布表。
第三节 统计图
一、统计图的结构及其绘制规则
统计图由标题、图号、标目、图形、图注等项构成。下面按其构成部分说明绘图的基本规则。
标题 图的名称应简明扼要,切合图的内容,必要时可注明时间、地点。
图号 文章中若有几幅画,则需按其出现的先后次序编上序号,写在图题的作前方。
标目 对于有纵横轴的统计图,应在纵横轴上分别标明统计项目及其尺度。
图形 图形线在图中为最粗,而且要清晰。
图注 图注不是图中必要组成部分。
二、表示间断变量的统计图
1、直条图
直条图是用直条的长短表示统计事项数量的图形。它主要是用来比较性质相似的间断性资料。
2、圆形图
圆形图是用来表示间断性资料构成比的图形。
三、表示连续变量的统计图
1、线形图
线形图用来表示连续性资料。它能表示两个变量之间的函数关系;一种事物随另一种事物变化的情况;某种事物随时间推移的发展趋势等。
2、频数分布图
常用的频数分布图有直方图、多边图和累积多边图。
(1)直方图
直方图用面积表示频数分布。用各组上下限上的矩形面积表示各组频数。
(2)多边图
多边图以纵轴上的高度表示频数的多少。
(3)累积频数和累积百分比多边图
第三章 集中量
集中量是代表一组数据典型水平或几种趋势的量。它能反映频数分布中大量数据向某一点集中的情况。
第一节 算术平均数
一、算术平均数的概念
算术平均数是所有观察值得总和除以总频数所得之商,简称为平均数或均数。计算公式为(3.1)。
算术平均数的特征:
(1)观察值的总和等于算术平均数的N倍;
(2)各观察值与其算术平均数之差的总和等于零;
(3)若一组观察值是由两部分(或几部分)组成,这组观察值的算术平均数可以由组成部分算术平均数而求得;
二、算术平均数的应用及其优缺点
算术平均数具备一个良好的集中量所应具备的一些条件:
(1)反应灵敏。
(2)严密确定。简明易懂,计算方便。
(3)适合代数运算。
(4)受抽样变动的影响较小。
除此之外,算数平均数还有几个特殊的优点:
(1)只知一组观察值的总和及总频数就可以求出算术平均数。
(2)用加权法可以求出几个平均数的总平均数。
(3)用样本数据推断总体集中量时,算术平均数最接近于总体集中量的真值,它是总体平均数的最好估计值。
(4)在计算方差、标准差、相关系数以及进行统计推断时,都要用到它。
算术平均数的缺点:
(1)易受两极端数值(极大或极小)的影响。
(2)一组数据中某个数值的大小不够确切时就无法计算其算术平均数。
第二节 中位数
一、中位数的概念
中位数是位于依一定顺序排列的一组数据中央位置的数值,在这一数值上、下各有一半频数分布着。
二、中位数的计算方法
1、原始数值计算方法
将一组原始数据依大小顺序排列后,若总频数为奇数,就以位于中央的数据作为中位数;若总频数为偶数,则以最中间的两个数据的算术平均数作为中位数。
2、频数分布表计算法
若一组原始数据已经编成了频数分布表,可用内插法,通过频数分布表计算中位数。
三、百分位数的概念及其计算方法
百分位数是位于依一定顺序排列的一组数据中某一百分位置的数值。在心理测量中,常通过计算百分位数来说明、解释和评价分数在团体中所处的位置。计算公式为(3.5)。
四、中位数的应用及其优缺点
中位数虽然也具备一个良好的集中量所应具备的某些条件,例如比较严格确定、简明易懂,计算简便,受抽样变动影响较小,但是它不适合进一步的代数运算。它适用于以下几种情况:(1)一组数据中有特大或特小两极端数值时;(2)一组数据中有个别数据不确切时;(3)资料属于等级性质时。
第三节 众数
一、众数的概念
众数是集中量的一种指标。对众数有理论众数及粗略众数两种定义方法。理论众数是指与频数分布曲线最高点相对应的横坐标上的一点。粗略众数是指一组数据中频数出现最多的那个数。
二、众数的计算方法
1、用观察法直接寻找粗略众数
粗略众数不需要计算,可通过观察直接寻得。
2、用公式求理论众数的近似值
(1)皮尔逊(K.Person)的经验法
利用皮尔逊发现的算术平均数、中位数、众数三者关系来求理论众数近似值的经验公式为(3.6)。
(2)金氏(W.I.King)插补法
当频数分布呈偏态,即众数所在组以上各组频数总和与以下各组频数总和相差较多时,可以用金氏公式计算众数,以进行比率调整。其公式为(3.7)。
三、众数的应用及其优缺点
众数虽然简明易懂,但是它并不具备一个良好的集中量的基本条件。它主要在以下情况下使用:(1)当需要快速而粗略地找出一组数据的代表值时;(2)当需要利用算术平均数、中位数和众数三者关系来粗略判断频数分布的形态时;(3)利用众数帮助分析解释一组频数分布是否确实具有两个频数最多的集中点时。
第四节 加权平均数、几何平均数
一、加权平均数
加权平均数是不同比重数据(或平均数)的平均数。计算公式为(3.8)或(3.9)。
二、几何平均数
几何平均数是N个数值连乘积的N次方根。计算公式为(3.10)。
当一个数列的后一个数据是以前一个数据为基础成比例增长时,要用几何平均数求其平均增长率。
第四章 差异量
第一节 全距、四分位距、百分位距(略)
第二节 平均差
一、平均差的概念
所谓平均差,就是每一个数据与该组数据的中位数(或算术平均数)离差的绝对值的算术平均数。
二、平均差的计算方法
用原始数据计算平均差的公式为(4.3)
三、平均差的优缺点
平均差意义明确,计算容易,每个数据都参加了运算,考虑到全部的离差,反应灵敏。但计算要用绝对值,不适合代数运算。
第三节 方差和标准差
一、方差和标准差的概念
方差是指离差平方的算术平均数。其定义公式为(4.5),计算公式是(4.7)。
标准差是指离差平方和平均后的方根。即方差的平方根。其定义公式为(4.6),计算公式是(4.8)。
二、方差和标准差的应用及其优缺点
方差和标准差的优点:反应灵敏,随任何一个数据的变化而表示;一组数据的方差和标准差有确定的值;计算简单;适合代数计算,不仅求方差和标准差的过程中可以进行代数运算,而且可以将几个方差和标准差综合成一个总的方差和标准差;用样本数据推断总体差异量时,方差和标准差是最好的估计量。
第三节 相对差异量
一、相对差异量的概念
上述全距、四分位距、平均差及标准差都是带有与原观察值相同单位的名数,称为绝对差异量。这种差异量对两种单位不同,或单位相同而两个平均数相差较大的资料,都无法比较差异的大小,必须用相对差异量(即差异系数)进行比较。
所谓差异系数是指标准差与其算术平均数的百分比。它是没有单位的相对数。其计算公式是(4.11)
二、差异系数的用途
1、比较不同单位资料的差异程度
2、比较单位相同而平均数相差数较大的两组资料的差异量程度
3、可判断特殊差异情况
三、差异系数的应用条件
从测验的理论来说,只有等比量表才使平均数等于零成为不可能。也就是说,用来测量的量尺,既具有等距的单位,又具有绝对零点,这时所测量出的数据其平均数才不可能等于零,这时才能计算差异系数。
第五节 偏态量及峰态量
偏态量及峰态量是用以描述数据分布特征的统计量。
一、偏态量
1、利用算术平均数与众数或中位数的距离来计算。2、根据动差来计算。二、峰态量
1、用两个百分位距来计算。2、根据动差来计算。
第五章 概率及概率分布
第一节 概率的一般概念
一、概率的定义
概率因寻求的方法不同有两种定义,即后验概率和先验概率。
1、后验概率的定义
以随机事件A在大量重复试验中出现的稳定频率制作为随机事件A概率的估计值,这样寻得的概率称为后验概率。计算公式是(5.2)。
2.先验概率的定义
先验概率是通过古典概率模型加以定义的,故又称为古典概率。古典概率模型要求满足两个条件:(1)试验的所有可能结果是有限的;(2)每一种可能结果出现的可能性(概率)相等。若所有可能结果的总数为n,随机事件A包括m个可能结果,则事件A的概率计算公式为(5.3)。
二、概率的性质
1、任何随机事件A的概率都是介于0与1之间的正数;
2、不可能事件的概率等于0;
3、必然事件的概率等于1。
三、概率的加法和乘法
1、概率的加法
在一次试验中不可能同时出现的事件称为互不相容的事件。
两个互不相容事件和的概率,等于这两个事件概率之和。
2.概率的乘法
A事件出现的概率不影响B事件出现的概率,这两个事件为独立事件。
两个独立事件的概率,等于这两个事件概率的乘积。
二项分布
一、满足以下条件的试验称为二项试验:
(1)一次试验只有两种可能结果,即成功和失败;(2)各次试验相互独立,互不影响;
(3)各次试验中成功的概率相等。
二、二项分布函数
二项分布是一种离散型随机变量的概率分布。
用n次方的二项展开式来表达在n次二项试验中成功事件出现不同次数(X=0,1,…,n)的概念分布叫做二项分布。
二项展开式的通式就是二项分布函数,运用这一函数式可以直接求出成功事件恰好出现X次的概率。
三、二项分布图
从二项分布图可以看出,当p=q,不管n多大,二项分布呈对称形。当n很大时,二项分布接近于正态分布。当n趋近于无限大时,正态分布是二项分布的极限。
四、二项分布的平均数和标准差
当二项分布接近于正态分布时,在n次二项实验中成功事件出现次数的平均数和标准差分别可以由公式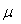 =np和
=np和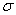 =
=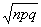 计算而得。
计算而得。
五、二项分布的应用
1.求成功事件恰好出现X次的概率 2.在教育学中主要用来判断实验结果的机遇性与真实性的界限。
若实验次数n较大,一般都用正态分布近似处理。
六、正态分布
1.正态分布是一种连续型随机变量的概率分布。
2.正态曲线的特点
(1)曲线在Z=0处为最高点。
(2)曲线以Z=0处为中心,双侧对称。
(3)曲线从最高点向左右缓慢下降,并无限延伸,但永远不与基线相交。
(4)标准正态分布上的平均数为0,标准差为1。
(5)曲线从最高点向左右延伸时,在正负1个标准差是拐点。
正态分布中的μ、σ、N都是常量,在每个正态分布中,它们的变化会导致正态曲线不同,如下图,尽管平均数相同,但由于σ不同而正态分布的形态差异较大。
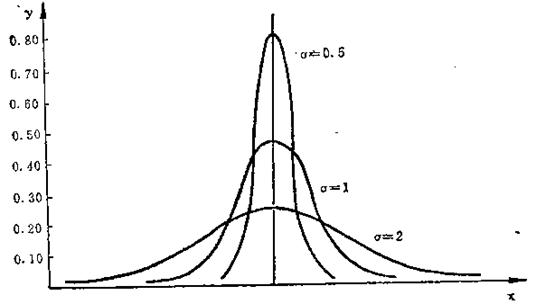
N个平均数相同的正态分布,标准差小的,正态曲线高狭,标准差大的,正态曲线就低阔。(如上图)
3.标准正态分布:平均数为0,标准差为1的正态分布叫做标准正态分布
4.正态分布在测验计分方面的应用
(1)将原始分数转换成标准分数
标准分数的意义:第一,各科标准分数的单位是绝对等价的;第二、标准分数的正负和大小可以反映出考生在全体考分中所处的地位。
(2)确定录用分数线
(3)确定等级评定的人数
(4)品质评定数量化
5.基本随机变量中有不服从正态分布的,对他们进行检验的方法有:偏态描述法
(偏态量数SK)当SK >0时,分布为正偏态;SK<0时,分布是负偏态;SK=0时,分布是正态。
抽样分布及总体平均数的推断
随机抽样的方法有:
1. 简单随机抽样:如抽签、利用随机数字抽样
2. 机械随机抽样(等距抽样):将总体的每个个体编号,然后按确定的间隔抽取个体。
3. 分层抽样(分层抽样):将总体按已知的某特征分为几部分,然后从每个层中再随机抽样。
4. 政群随机抽样:以整体中的自然群体为对象,随机抽取若干群体作为样本的方法。
自由度(df):指变量在特定条件下能自由变化数据的数目,自由度的取值是由样本容量的n减去由资料算出的各统计值受到限制的数目。一般自由度=n‐1,但是也不一定,有时候=n-2或者n-3等。
第一节 抽样分布
一、抽样分布的概念
要区分以下三种不同性质的分布:
1、总体分布:总体内个体数值的频数分布。
2、样本分布:样本内个体数值的频数分布。
3、抽样分布:某一种统计量的概率分布。
把统计量抽样分布的标准差为标准误差简称标准误。,它描述了样本统计量分布的离散程度,根据标准误可以对总体参数进行估计。
平均数抽样分布的标准差叫做平均数的标准误;标准差抽样分布的标准差叫做标准长的标准误。样本平均数抽样分布的标准差反映了抽样误差的大小。
二、平均数抽样分布的几个定理
1、从总体中随机抽出容量为n的一切可能样本的平均数之平均数等于总体的平均数。
2、容量为n的平均数在抽样分布上的标准差,等于总体标准差除以样本容量n的方根。
3.从正态总体中,随机抽取的容量为n的一切可能样本平均数的分布也呈正态分布。
4.虽然总体不呈正态分布,如果样本容量较大,反映总体μ和σ的样本平均数的抽样分布,也接近于正态分布。
三、样本平均数与总体平均数离差统计量的形态
从正态总体中随机抽取的容量为n的一切可能样本平均数为中心呈正态分布。当总体标准差已知时,一切可能样本平均数与总体平均数的离差统计量呈标准正态分布。
总体标准差σ的无偏估计量S等于样本统计量σx乘以贝赛耳氏校正数。
从正态总体中随机抽取容量为n的一切可能样本平均数的抽样分布呈正态分布。当总体标准差σ未知,需用估计值S来代替,于是平均数标准误也被平均数标准误的估计值所代替,这时一切可能样本平均数与总体平均数的离差统计量呈t分布。
t分布与正态分布的相似之处:t分布基线上的t值从-∞-+∞;从平均数等于0处,左侧t值为负,右侧t值为正;曲线以平均数处为最高点向两侧逐渐下降,尾部无限延伸,永不与基线相接,呈单峰对称形。区别之处在于:t分布的形态随自由度(df=n-1)的变化呈一簇分布形态(即自由度不同的t分布形态也不同)。自由度逐渐增大时,t分布逐渐接近正态分布。
自由度是指总体参数估计量中变量值独立自由变化的个数。
F分布:从两个方差相同的正态总体中,随机抽取两个独立的样本,根据两个样本方差可求出相应总体方差的无偏估计量,这两个总体方差估计值的比值,以F表示。F称为F统计量,F统计量的抽样分布称为F分布。F分布在进行两个独立样本的方差齐性检验、方差分析等处理都要用来。
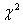 分布,读作“卡方分布”:是从总体中抽出一样本时,实测次数与理论次数(期望次数)之间的差异程度的指标。应用于:计数数据的假设检验以及样本方差与总体方差差异是否显著的检验。
分布,读作“卡方分布”:是从总体中抽出一样本时,实测次数与理论次数(期望次数)之间的差异程度的指标。应用于:计数数据的假设检验以及样本方差与总体方差差异是否显著的检验。
总体平均数的参数估计
一、总体参数估计的基本原理
点估计:用某一样本统计量的值来估计相应总体参数的值叫总体参数的点估计。(如:用样本平均数估计总体平均数;用样本方差估计总体方差等)
区间估计:以样本统计量的抽样分布(概率分布)为理论依据,按一定概率要求,由样本统计量的值估计总体参数值的所在范围,称为总体参数的区间估计。
区间估计涉及置信水平和置信区间:
置信区间:区间评估时,某一概率下,总体参数所在的区间称为置信区间。
置信度(显著性水平):区间的端点值称为临界值,这个概率称为置信度,以概率1-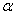 表示,又称为显著性水平。表示该区间的不可靠程度,即估计位于该区间时,可能犯错误的概率。
表示,又称为显著性水平。表示该区间的不可靠程度,即估计位于该区间时,可能犯错误的概率。
进行区间估计的关键是找一个合适的统计量以及这个统计量抽样分布的状态、标准误。因为区间估计的精度依赖于标准误的大小,对于相同的置信度,标准误越大,置信区间就越长,估计的精度就越低;标准误越大,置信区间越短,击鼓精度越高。
二、 (总体方差)已知条件下总体平均数的区间估计
当总体已知,总体呈正态分布,样本容量无论大小时,或者当总体已知,总体虽不呈正态分布,但样本容量较大(n >30)时,样本平均数与总体平均数离差统计量均呈正态分布。
三、未知条件下总体平均数的区间估计
1、未知条件下总体平均数的区间估计的基本原理
当总体未知,总体呈正态分布,样本容量无论大小时,或者当总体未知,总体虽不呈正态分布,但样本容量较大(n >30)时,样本平均数与总体平均数离差统计量均呈t分布。区间估计的计算公式为(6.10)和(6.11)。
2、小样本的情况
3、大样本的情况
可以用正态分布近似处理。
假设检验的基本原理
假设检验:通过对两个统计值的比较、分析,判断两者之间的差异是抽样误差所致还是由于总体参数间真正存在差异的过程叫做假设检验。(统计值之间的差异一般有:两个平均数、两个方差、两个比率、两个相关系数的差异。对于这些差异一般分两种情况讨论:样本统计量与相应的总体参数的差异;两个样本统计量之间的差异。)
(利用样本信息,根据一定概率,对总体参数或分布的某一假设作出拒绝或保留的决断,称为假设检验。)统计假设检验就是利用两个统计值之间的差异来检验其总体参数是否有差异。
显著差异:通过检验,如果所得差异超过了统计学所规定的某一误差界限,则表明这个差异已不属于抽样误差,而是样本来自的总体本身确有差异,这种情况称之为差异显著。表明两者之间有本质的差别。
差异不显著:若所得差异未达到规定的界限,则表明该差异主要来自抽样误差,此时称之为差异不显著。表明两者之间无本质差别。
一、假设
假设检验一般有两个相互对立的假设。即零假设(或称原假设、虚无假设、解消假设)和备择假设(或称研究假设、对立假设)。假设检验是从零假设出发,视其被拒绝的机会,从而得出决断。
二、小概率事件
把出现小概率的随机事件称为小概率事件。小概率事件是否出现,这是对假设作出决断的依据。
两种判断小概率出现的水平:(1)以P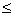 0.05作为小概率事件的标准(2)P0.01为标准。这个标准称为显著性水平,用=0.05,=0.01表示,当取定0.05(0.01)时,只要统计量的值在抽样分布中出现的概率等于或者小于0.05(0.01)就可以认为小概率发生,则拒绝零假设。
0.05作为小概率事件的标准(2)P0.01为标准。这个标准称为显著性水平,用=0.05,=0.01表示,当取定0.05(0.01)时,只要统计量的值在抽样分布中出现的概率等于或者小于0.05(0.01)就可以认为小概率发生,则拒绝零假设。
三、显著性水平
拒绝零假设的概率称为显著性水平。显著性水平和可靠性程度之间的关系是:两者之和为1。
四、统计决断的两类错误及其控制
如果拒绝了属于真实的零假设,即如果样本统计量的总体参数正是假设的总体参数,但是由于样本统计量的值落入了拒绝区域。而零假设遭到拒绝,这时就会犯第一类型的错误。这种错误的可能性大小正是显著性水平的大小,故又称这类错误为α错误。如果保留了属于不真实的零假设,就会犯第二类型的错误。犯这种“假设属伪而被保留”的第二类错误的概率,等于β值,故又称这类错误为β错误。
要使第一类错误的概率保持在需要的水平上,而控制第二类错误的概率,有以下方法:(1)利用已知的实际总体参数与假设参数值之间的大小关系,合理安排拒绝领域的位置,选择双侧检验还是单侧检验,左侧检验还是右侧检验;(2)加大样本容量。
平均数差异的显著性检验
第一、相关样本平均数差异的显著性检验
相关样本:两个样本内个体之间存在着一一对应的关系,这两个样本称为相关样本。
相关样本有以下两种情况:(1)用同一测验对同一组被试在试验前后进行两次测验,所获得的两组测验结果是相关样本。(2)根据某些条件基本相同的原则,把被试一一匹配成对,然后将每对被试随机地分入实验组和对照组,对两组被试施行不同的实验处理之后,用同一测验所获得的测验结果,也是相关样本。
相关样本平均数差异的显著性检验方法和步骤:
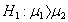
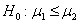 (1)提出假设(2)选择检验统计量并计算其值。(3)确定检验形式(4)统计决断
(1)提出假设(2)选择检验统计量并计算其值。(3)确定检验形式(4)统计决断
如:1.提出假设:
2.选择检验统计量并计算其值:
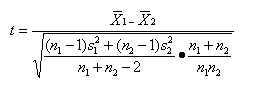
3.确定显著性水平α,查表求出临界值。df=?,t(n)0.05=?,t(n)0.01=?
4.统计决算 : ∵ t(17)0.01=2.567<t**=2.835 P<0.01 ∴接受H1
第二、 独立样本平均数差异的显著性检验
两个样本内的个体是随机抽取的,它们之间不存在一一的对应关系,这样的两个样本称为独立样本。
一、独立大样本平均数差异的显著性检验
两个样本容量n1和n1都大于30的独立样本称为独立大样本。
二、独立小样本平均数差异的显著性检验
两个样本容量n1和n1均小于30,或其中一个小于30的独立样本称为独立小样本。
独立小样本平均数差异的显著性检验方法:
1、方差齐性时
如果两个独立样本的总体方差未知,经方差齐性检验表明两个总体方差相
2、方差不齐性时
对于方差不齐性的两个独立样本平均数差异显著性检验,需要用校正的t'作为检验统计量。
第三、方差齐性检验
方差的齐性检验:对两个总体方差差异的显著性进行检验,当两个总体方差的差异不显著时,就说两个总体方差齐性或一致或相等。
两种齐性检验方法:
1.t检验:对两个相关样本的方差进行齐性检验。
2.F检验:对两个独立样本方差是否齐性进行检验。
一、F分布
若从方差相同的两个正态总体中,随机抽取两个独立样本,以此为基础,分别求出两个相应总体总体方差的估计值,这两个总体方差估计值的比值称为F比值,F比值的抽样分布称为F分布。F分布的形态随F比值分子和分母中自由度的变化而形成一簇正偏态分布。
一般情况下,经常应用的是右侧F检验,计算F值时,将大的总体方差估计值作为分子,小的作为分母。
第 章 方差分析
方差分析可以一次性综合地检验三个及三个以上样本均值的差异显著性程度。它是通过分析样本数据的各项变量来源,以检验三个或三个以上样本平均值是否具有显著性差异的一种统计方法。
组间差异(组间平方和):指各组平均值与总平均值离均差的平方和,即各组平均数之间的差异。SS
组内差异(组内平方和):指每个被测的观测数据与其组内的平均值离均差的平方和,即各组内部分数之间的差异,记为SS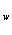
方差分析的类别:单因素方差分析、多因素方差分析、协方差分析、多元方差分析、重复测量方差分析、方差成分分析
第一节 方差分析的基本原理
一、方差分析的目的
方差分析的基本功能就在于它对多组平均数差异的显著性进行检验的作用。
二、方差分析的逻辑
组间差异对组内差异的比值越大,则各组平均数的差异就越明显。通过对组间差异与组内差异比值的分析,来推断几个相应平均数差异的显著性,这就是方差分析的逻辑。
三、以F检验来推断几个平均数差异的显著性
四、方差分析中的几个概念
实验中的自变量称为因素。只有一个自变量的实验称为单因素实验。有两个或两个以上自变量的实验称为多因素实验。某一个因素的不同情况称为因素的“水平”。包括量差或质别两类情况,按各个“水平”条件进行的重复实验称为各种处理。
第二节 完全随机设计的方差分析
为了检验某一个因素多种不同水平间的差异的显著性,将从同一个总体中随机抽取的被试,再随机地分入各实验组,施以各种不同的实验处理以后,用方差分析法对这多个独立样本平均数差异的显著性进行检验,称为完全随机设计的方差分析。
一、n 相等的情况
用公式(8.4)-(8.6)。
二、n 不相等的情况
用公式(8.7)-(8.8)。
三、运用样本统计量进行组间与组内方差的F检验
用第181页上的公式。
第三节 随机区组设计的方差分析
用方差分析法对多个相关样本平均数差异所进行的显著性检验,称之为随机区组设计的方差分析
每一区组内被试的人数分配有以下三种方式:
(1)一个被试作为一个区组;
(2)每一区组内被试的人数是实验处理数的整数倍;
(3)区组内以一个团体为一个基本单元。
区组平方和等数据的计算用公式(8.9)-(8.11)。
第四节 各个平均数差异的显著性检验
对多组平均数的逐对差异检验,以Newman-Keul提出的q检验法(或称N-K)最为常用。
一、完全随机设计的q检验
公式(8.14)或(8.15)。
二、随机区组设计的q检验
公式(8.16)。
第五节 多组方差的齐性检验
多组方差的显著性可以用哈特莱(Hartley)所提出的最大F值检验法进行齐性检验。公式(8.17)。
第六节 多因素方差分析简介
一、多因素方差分析的功能
多因素方差分析不仅可以检验各个因素对因变量作用的显著性,而且还可以检验因素与因素间共同结合对因变量发生交互作用的显著性。
二、双因素完全随机设计方差分析的基本方法
计算时使用公式(8.18)-(8.20)和第204-205页上的公式。
第九章 总体比率的推断
第一节 比率的抽样分布
一、数据的特点
对点计数据的统计推断,应采用总体比率的推断方法或卡方检验。当事物仅被划分成两类,可用总体比率的推断进行统计推断;当事物被划分为成两类以上时,则需用卡方检验进行统计推断。当然卡方检验也可以对仅有两种类别的资料进行统计推断。
二、比率的抽样分布
比率的抽样分布是二项分布。当p=q,无论n的大小,二项分布呈对称形;当p <q且np≥5,或p >q且np≥5时,二项分布已经开始接近正态分布。
三、比率的标准误
比率的标准误是由二项分布的标准差除以n而获得。
第二节 总体比率的区间估计
一、正态近似法
公式(9.3)-(9.5)。
二、查表法
用附表6。
第三节 总体比率的假设检验
一、正态近似法
公式(9.6)-(9.5)。
二、查表法
用附表6。
第四节 总体比率差异的显著性检验
一、两个独立样本比率差异的显著性检验
两个独立样本比率差异的标准误:公式(9.8)。
如果两个独立样本的最小频数都等于或大于5,两个样本比率之差的抽样分布也接近于正态,于是可用Z检验两个比率之差的显著性。其检验统计量为公式(9.11)。
二、两个相关样本比率差异的显著性检验
两个相关样本比率之差的检验公式为(9.13)。
第十章 卡方检验
第一节 χ2及其分布
一、卡方检验的特点
卡方检验是对样本的频数分布所来自的总体分布是否服从某种理论分布或某种假设分布所作的假设检验。即根据样本的频数分布来推断总体的分布。它属于自由分布的非参数检验。它可以处理一个因素分为多种类别,或多种因素各有多种类别的资料。所以,凡是可以应用比率进行检验的资料,都可以用卡方检验。
二、卡方检验的统计量
卡方检验统计量的基本形式为公式(10.1)。
χ2值有以下几个特点:
(1)χ2值具有可加性。
(2)χ2值永远是正值。
(3)χ2值的大小随实际频数与理论频数差的大小而变化。
三、χ2的抽样分布
χ2分布有以下几个特点:
(1)χ2分布呈正偏态,右侧无限延伸,但永不与基线相交。
(2)χ2分布随自由度的变化而形成一簇分布形态。
自由度越小,χ2分布偏斜度越大;自由度越大,χ2分布形态越趋于对称。
第二节 单向表的卡方检验
把实得的点计数据按一种分类标准编制成表就是单向表。对于单向表的数据所进行的卡方检验就是单向表的卡方检验,即单因素的卡方检验。
一、按一定比率决定理论频数的卡方检验
二、一个自由度的卡方检验
当df=1,其中只有一个组的ft <5,就要运用亚茨(Yates)连续性校正法(10.2)。
三、频数分布正态性的卡方检验
第三节 双向表的卡方检验
把实得的点计数据按两种分类标准编制成的表就是双向表。对双向表的数据进行的卡方检验,就是双向表的卡方检验,即双因素的卡方检验。
在双向表的卡方检验中,如果要判断两种分类特征,即两个因素之间是否有依从关系,这种检验称为独立性卡方检验。
在双向表卡方检验中,如果是判断几次重复实验的结果是否相同,这种卡方检验称为同质性检验。
双向表的独立性卡方检验和同质性卡方检验,只是检验的意义不同,而方法完全相同,都应用公式(10.3)或(10.4)。对于同一组数据所进行的卡方检验,有时即可以理解为独立性卡方检验,又可以理解为同质性检验,两者无本质区别。
第四节 四格表的卡方检验
一、独立样本四格表的卡方检验
独立样本四格表的卡方检验,就是双向表中2*2表的卡方检验。它即可以用缩减公式由实际频数直接计算χ2值,又可以用上述求理论频数的方法计算χ2值。
1.缩减公式χ2值的计算
独立样本四格表χ2值的缩减公式为(10.6)。
2.校正χ2值的计算
当df=1,样本容量总和N <30或N <50时(决定于对检验结果要求的严格程度),应对χ2值进行亚茨连续性校正。其校正公式为(10.7)。
二、相关样本四格表的卡方检验
1.缩减公式χ2值的计算
相关样本四格表χ2值的缩减公式为(10.8)。
2.校正χ2值的计算
当df=1,两个相关样本四格表中(b+c) <30或(b+c) <50(决定于对检验结果要求的严格程度),应对χ2值进行亚茨连续性校正。其校正公式(10.9)。
第十一章 相关分析
第一节 相关的意义
一、相关的概念
两个变量之间不精确、不稳定的变化关系称为相关关系。
二、相关系数
用来描述两个变量相互之间变化方向及密切程度的数字特征量称为相关系数。一般用r表示。
相关系数的值,仅仅是一个比值。它不是由相等单位度量而来(即不等距),也不是百分比,因此,不能直接作加、减、乘、除。
相关系数只能描述两个变量之间的变化方向及密切程度,并不能揭示二者之间的内在本质联系。
第二节 积差相关
一、概念及其适用范围
1.积差相关的概念
当两个变量都是正态连续变量,而且两者之间呈线性关系,表示这两个变量之间的相关称为积差相关。
2.积差相关使用的条件
(1)两个变量都
第十二章 回归分析
第一节 一元线性回归
一元线性回归是指只有一个自变量的线性回归。
一、回归线
一条最能代表散点图上分布趋势的直线,这条最优拟合线即称为回归线。常用的拟合这条回归线的原则,就是使各点与该线纵向距离的平方和为最小。
二、回归方程
确定回归线的方程称回归方程。
1.用最小二乘方法求回归系数
公式(12.2a)或(12.2b)。
2.求截距
公式(12.3a)或(12.3b)。
三、用原始数据计算回归系数
公式(12.4a)或(12.4b)。
第二节 一元线性回归方程的检验
一、估计误差的标准差
公式(12.9)。
二、一元线性回归方程检验的方法
一元线性回归方程检验有三种等效的方法:
(1)对回归方程进行方差分析;
(2)对两个变量的相关系数进行与总体零相关的显著性检验;
(3)对回归系数进行显著性检验
三、一元线性回归系数显著性检验方法
在回归线上,当与所有自变量X相对应的各组因变量Y的残值都呈正态分布,并且残值方差为齐性时,由X估计Y回归系数的标准误为公式(12.11)或(12.12)。可以用公式(12.13)或公式(12.14)进行显著性检验。
三、测定系数
测定系数指回归平方和在总平方和中所占比例,这个比例越大,意味着误差平方和所占比例越小,预测效果就越好。测定系数同时等于相关系数的平方。
第三节 一元线性回归方程的应用
一、用样本回归方程推算因变量的回归值
二、对因变量真值的预测
第四节 多元线性回归简介
一、二元线性回归方程
1.二元线性回归方程的意义
二元线性回归方程是指Y对X1与X2的线性回归方程。
2.二元线性回归方程的建立原理
和一元线性回归方程一样,二元线性回归方程也用最小二乘法来确定回归系数。用公式(12.25a)和(12.25b)。
3.二元线性标准回归方程
为了比较两个自变量在估计预测因变量时所起作用的大小,需要将三个变量分别转换成标准分数,然后比较由标准分数所建立的标准回归方程中的两个标准回归系数,以此判断两个自变量作用的大小。
二、二元线性回归的检验
二元线性回归的检验包括两个方面:一是检验回归方程的显著性;另一是检验两个偏回归系数的显著性。
(一)二元线性回归的检验
二元线性回归方程的显著性有两种等效的检验方法:一是方差分析,二是复相关系数显著性检验。
复相关系数表示两个自变量组合起来与因变量之间的相关程度。可通过对二元测定系数开平方根得到,然后通过查表进行显著性检验。
(二)偏回归系数的显著性检验
两个偏回归系数的显著性检验公式为(12.29a)和(12.29b)。
三、多元线性回归方程中自变量的选择
1.从组成回归方程的所有自变量中选择最优的自变量
对所有可能的回归方程逐一检验,选择一个显著性程度最强的方程。
2.逐步回归
逐步回归的原理是按每个自变量对因变量的作用,从大到小逐个地引入回归方程,每引入一个自变量要对回归方程中的每一个自变量都进行显著性检验(即对其偏回归系数进行显著性检验)。这样逐步地引入自变量,并剔除不显著的自变量,直至将所有的自变量都引入,并将不显著的自变量都剔除为止,最后形成的回归方程就是最优方程。
第十三章 非参数检验
假设检验的方法有两种:参数检验和非参数检验。
在实际研究工作中,样本所属的总体分布形态一般是未知的,所获得的资料也不一定是等距变量或比率变量,因此需要采用新的统计方法进行检验。这种检验方法不要求样本所属的总体呈正态分布,一般也不是对总体进行检验,故称之为自由分布的非参数检验方法。非参数检验不仅适用于非正态总体名义变量和次序变量的资料,而且也适用于正态总体等距变量和比率变量的资料。故应用广泛,但灵敏度和精确度不如参数检验。
第一节 符号检验
符号检验是通过多两个相关样本的每对数据之差的符号(正号或负号)进行检验,以比较这两个样本差异的显著性。
一、小样本的情况
当样本容量较小,n <25时,可用查表法进行符号检验。
二、大样本的情况
对差数的正号与负号差异的检验本属于二项分布的问题,当样本容量较大,即n >25时,二项分布接近正态分布,因此可以用正态分布近似处理,公式用(13.2)。
第二节 符号秩序检验
威尔科克逊(F.Wilcoxon)提出了既考虑差数符号,又考虑差数大小的符号秩次检验法。
一、小样本的情况
当样本容量n <25时,可用查表法进行符号秩次检验。
二、大样本的情况
当样本容量n >25时,二项分布接近与正态。于是可用正态分布近似处理。
检验统计量为公式(13.5)。
第三节 秩和检验
当比较两个独立样本的差异时,可以采用曼-惠特尼(Mann-Whitney)两人提出的秩和检验方法。又称曼-惠特尼U检验法。
一、小样本的情况
当两个独立样本的容量n1和n2都小于10,并且n1≤n2时,可以用查表法。
二、大样本的情况
当两个独立样本的n1和n2都大于10,T分布接近与正态,对于两个样本的差异可以用正态分布的Z比率进行检验。公式(13.8)。
第四节 中位数检验
中位数的检验方法是将各组样本数据合在一起找出共同的中位数,然后分别计算每个样本在共同中位数上、下的频数,再进行r×c表卡方检验。
第五节 单向秩次方差分析
对于几个独立样本差异的显著性,可以用克鲁斯尔(W.H.Kruskal)和沃利斯(W.A.Wallis)所提出的单向秩次方差分析进行检验。这种方法又称为H检验法。它相当于对多组平均数所进行的参数的方差分析。但是它不需要对样本所属的几个总体做正态分布及方差齐性的假定。它处理的是秩次变量的资料,是用秩次进行的非参数的方差分析。
这种检验方法是将所有样本的数据合在一起,按从小到达编秩次,然后计算各样本的秩次和。如果各组有显著性差异,在各组容量相等的情况下,各组秩次和应当相等或趋于相等;如果各组秩次和相差较大,那么各组有显著性差异的可能性较大。
一、样本容量较小或组数较小的情况
当各组容量n≤5时,或者样本组数k≤3,可用公式(13.9)作为检验统计量。
二、样本容量较大或组数较多的情况
当各组容量n >5,或样本组数k >3时,H值的抽样分布接近于自由度df=k-1的卡方分布,因此,可进行卡方检验。
第六节 双向秩次方差分析
双向秩次方差分析,处理的是几个相关样本次序变量的资料。双向秩次方差分析是在同一个对象(或匹配的对象)接受k次实验处理所获得原始数据之间编秩次。如果各次实验导致差异不显著,各次实验产生的秩次和应当相等或趋于相等;如果各次实验秩次和相差较大,那么,实验产生显著性差异的可能性较大。
一、样本容量较小及实验次数较少的情况
当样本容量n≤9;k=3;或n≤4,k=4时,可用公式(13.10)作为检验统计量。
二、样本容量较大或实验次数较多的情况
当k=3,n >9;k=4,n >4;或k >4时,上述检验统计量的抽样分布接近于df=k-1的卡方分布,于是可以用卡方近似处理。
第十四章 抽样设计
第一节 抽样方法
一、单纯随机抽样
如果总体中每个个体被抽到的机会是均等的,并且在抽取一个个体之后总体内成分不变(抽样的独立性),这种抽样方法称为单纯随机抽样。
二、机械抽样
把总体中的所有个体按一定顺序编号,然后依固定的间隔取样,这种抽样方法称为机械抽样。
三、分层抽样
按与研究内容有关的因素或指标先将总体划分成几个部分(层),然后从各部分(层)中进行单纯随机抽样或机械随机抽样,这种抽样方法称为分层抽样。
在确定从各层抽取对象的个数时,即考虑各层的个体数比例,又考虑各层标准差的大小,这种方法称为最优配置法,公式(14.1)。
四、整群抽样
从总体中抽出来的研究对象,不是以个体作为单位,而是以整群为单位的抽样方法,称为整群抽样。
第二节 总体平均数统计推断时样本容量的确定
一、由样本平均数估计总体平均数时样本容量的确定
1.总体标准差已知的情况
用公式(14.2)。
2. 总体标准差未知的情况
用公式(14.3)。
二、样本平均数与总体平均数差异显著性检验时样本容量的确定
1.总体标准差已知的情况
用公式(14.4)或(14.5)。
2.总体标准差未知的情况
用公式(14.6)或(14.7)。
三、两个样本平均数差异显著性检验时样本容量的确定
1.两个独立样本平均数差异显著性检验时样本容量的确定
用公式(14.8)或(14.9)。
2.两个相关样本平均数差异显著性检验时样本容量的确定
用公式(14.10)或(14.11)。
第三节 总体比率统计推断及相关系数显著性检验时样本容量的确定
一、用样本比率估计总体比率时样本容量的确定
当总体比率接近0.5,随n的增大,样本比率的抽样分布趋向正态,这时可以近似用公式(14.12)进行估计。
二、两个样本比率差异显著性检验时样本容量的确定
用公式(14.13)或(14.14)。
三、样本相关系数显著性检验时样本容量的确定
在确定样本容量时,可直接查相关系数显著性检验所需样本的容量表。
-
教学反思随笔
五指山思源实验学校教育日记李珂祯20xx0221星期一晴每天学会一分今天是第一天上班上了初中的第一节课稍微接触了一下学生发现学生并…
-
教学反思随笔
个人教学反思笔记万宁市和乐镇中心学校蔡王玉不知不觉中我在教育教学的路上已走到了13个年头回顾这13年的时光有笑有泪有花有果欣慰的是…
-
我的教育教学随笔
我的教育教学随笔梓里中学阮凤书人人都说教学苦在古代有家有五斗米不做孩子王的说法确实做一个老师挺苦挺累的做一个好教师就更苦更累了但这…
-
教学反思笔记
教学反思笔记20xx20xx学年第二学期第1周反思在教学中主要采用的是创设情境合作交流的方法充分利用学生的生活经验设计生动有趣的教…
-
我的教育教学随笔
我的教育教学随笔不知不觉间我在教育教学的路上已走到了十来个年头这些年来无论是在个人的教育教学经验驾驭课堂的能力还是教育教学的效果都…
-
初中数学教学反思笔记 Microsoft Word 文档
思之不慎行而失当反思意识人类早就有之反求诸己扪心自问吾日三省吾身等至理名言就是佐证而当今社会反思已成为人们的自觉行为何况作为教师在…
-
教学反思随笔
个人教学反思笔记万宁市和乐镇中心学校蔡王玉不知不觉中我在教育教学的路上已走到了13个年头回顾这13年的时光有笑有泪有花有果欣慰的是…
-
小学英语教学反思随笔
小学英语教学反思随笔时光荏苒自从我接过英语在这三尺讲台上摸索着走过了一年渐渐的对小学英语的教学有了初步的感知通过听课堂教学专家讲座…
-
我的教育教学随笔
我的教育教学随笔不知不觉间我在教育教学的路上已走到了十来个年头这些年来无论是在个人的教育教学经验驾驭课堂的能力还是教育教学的效果都…
-
体育教育教学随笔反思
原小学体育教学随笔20xx111195700By雷丽推荐情绪是推动人们进行各种活动的心理动因也是个体发动和维持行动的一种心理状态少…
-
随笔练习的总结与反思
随笔练习的总结与反思章一新随笔是高中生观察社会,积累生活之后形诸笔端的心灵感悟,是高中生习作园地的一块奇葩。是仅次于日记、书信的最…