数学建模心得总结二:使用word编辑论文时需要注意什么
数学建模心得总结二
(阅读心得:
1、 纠正对word的错误认识,它不仅仅是一个编辑器,更是一个排版软件,不
要只拿它当记事本或写字板用;
2、 不要说word不能,而是你不会!记住这句话!
3、 样式、文档结构图、公式编辑器、绘图、页眉和页脚、编号、目录等等,好
好学,一定熟练运用;
4、 让“内容与格式”产生“和谐”,从而获得最终效果。)
使用word编辑论文时需要注意什么?! 相信现在大家都主要还是用微软公司的Microsoft Word (以下简称Word)编
辑论文。 虽然 word在排版方面,远远不如编辑界的pagemaker,但是因为其在文字处理方面却拥有相对杰出的功能! 当然,Word 在写科技论文方面有一些先天不足。如果不能充分利用这些功能,可能经常要为不断地调整格式而烦恼。下面我们就来介绍这些技巧:
原则: 内容与表现分离
一篇论文应该包括两个层次的含义:内容与表现,前者是指文章作者用来表达自己思想的文字、图片、表格、公式及整个文章的章节段落结构等,而后者则是指论文页面大小、边距、各种字体、字号等。
本文所强调的"内容与表现分离"的原则就是说文章作者只要关心文章的内
容,所有与内容无关的排版工作都交给 Word 去完成,作者只需将自己的排版意图以适当的方式告诉 Word。因为Word不仅仅是一个编辑器,还是一个排版软件,不要只拿它当记事本或写字板用。主要建议如下:
1. 一定要使用样式。(这个是一定要会的)除了Word原先所提供的标题、正文等样式外,还可以自定义样式。如果你发现自己是用选中文字然后用格式栏来设定格式的,一定要注意,想想其他地方是否需要相同的格式,如果是的话,最好就定义一个样式。对于相同排版表现的内容一定要坚持使用统一的样式。这样做能大大减少工作量和出错机会,如果要对排版格式(文档表现)做调整,只需一次性修改相关样式即可。使用样式的另一个好处是可以由Word 自动生成各种目录和索引。
2. 一定不要自己敲编号。(这个应该要学会)一定要使用交叉引用。如果你发现自己打了编号,一定要小心,这极可能给你文章的修改带来无穷的后患。标题的编号可以通过设置标题样式来实现,表格和图形的编号通过设置题注的编号来完成。在写"参见第x章、如图x所示"等字样时,不要自己敲编号,应使用交叉引用。这样做以后,当插入或删除新的内容时,所有的编号和引用都将自动更新,无需人力维护。并且可以自动生成图、表目录。公式的编号虽然也可以通过题注来完成。
3. 插入的图片、和公式最好单独保存到文件里另做备份。(这个要真的需要留意,
千万别大意)否则,哪天打文档时发现自己辛辛苦苦的编辑的图片和公式都变成了大红叉,哭都来不及了。
4. 多做备份。(听他的,多备份,以防万一)不但Word不可靠,windows也不可靠,每天的工作都要有备份才好。注意分清版本,不要搞混了。Word提供了版本管理的功能,将一个文档的各个版本保存到一个文件里,并提供比较合并等功能。不过保存几个版本后文件就大得不得了,而且一个文件损坏后所有的版本都没了,个人感觉不实用。还是多处备份吧。 5. 编辑数学公式建议使用 MathType5.0。(我们组也非常推荐,在比赛前,把能用到的软件都提前装好,节省时间)其实Word集成的公式编辑器是它的3.0版。安装MathType后,Word会增加一个菜单项,其功能一目了然。一定要使用 MathType的自动编号和引用功能。这样首先可以有一个良好的对齐,还可以自动更新编号。Word 正文中插入公式的一个常见问题是把上下行距都撑大了,很不美观,这部分可以通过固定行距来修正。
6. 参考文献的编辑和管理。(我们比赛时未用,个人感觉稍微有点儿麻烦了。)如果你在写论文时才想到要整理参考文献,已经太迟了,但总比论文写到参考文献那一页时才去整理要好。应该养成看文章的同时就整理参考文献的习惯。手工整理参考文献是很痛苦的,而且很容易出错。Word没有提供管理参考文献的功能,用插入尾注的方法也很不地道。我建议使用 Reference Manager,它与Word集成得非常好,提供即写即引用(Cite while you write,简称Cwyw)的功能。你所做的只是像填表格一样地输入相关信息,如篇名、作者、年份等在文章中需要引用文献的的方插入标记,它会为你生成非常美观和专业的参考文献列表,并且对参考文献的引用编号也是自动生成和更新的。
这除了可以保持格式上的一致、规范,减少出错机会外,更可以避免正文中对参考文献的引用和参考文献列表之间的不匹配。并且从长远来说,本次输入的参考文献信息可以在今后重复利用,从而一劳永逸。
类似软件还有Endnote和Biblioscape。Endnote优点在于可以将文献列表导出到BibTeX格式,但功能没有Reference Manager强大。
可惜这两个软件都不支持中文,据说Biblioscape对中文支持的很好,我没有用过,就不加评论了。
7. 使用节。(这个比赛的时候排版肯定能用到的,经历过你就会知道了)如果希望在一片文档里得到不同的页眉、页脚、页码格式,可以插入分节符,并设置当前节的格式与上一节不同。
上述7点都是关于排版的建议,还是要强调一遍,作者关心的重点是文章的内容,文章的表现就交给Word去处理。
如果你发现自己正在做与文章内容无关的繁琐的排版工作,一定要停下来学一下Word的帮助,因为Word 早已提供了足够强大的功能。我不怀疑Word的功能,但不相信其可靠性和稳定性,经常遇到"所想非所见"、"所见非所得"的情况让人非常郁闷。如果养成良好的习惯,这些情况也可以尽量避免,即使遇上,也可以将损失降低到最低限度。
建议如下:
8. 使用子文档。(如果篇幅没有超过25页,可以选择不用。)学位论文至少要几十页,且包括大量的图片、公式、表格,比较庞大。如果所有的内容都保存在一个文件里,打开、保存、关闭都需要很长的时间,且不保险。建议论文的每一章保存到一个子文档,而在主控文档中设置样式。这样每个文件小了,编辑速度快,而且就算文档损坏,也只有一章的损失,不至于全军覆灭。建议先建主控文档,从主控文档中创建子文档,个人感觉比先写子文档再插入到主控文档要好。
9. 及时保存,设置自动保存,还有一有空就ctrl+s。(最好养成这个习惯。) 10. 绘图。统计图建议使用Execel生成,框图和流程图建议使用Visio画(同意,所以提前学学这个软件吧)。如果不能忍受Visio对象复制到Word的速度,还可以试试SmardDraw,功能不比Visio弱,使用不比Visio难,速度却快多了。如果使用Word的绘图工具绘图,最好以插入Word图片的方式,并适当使用组合。
11. 一定不要自己敲空格来达到对齐的目的。(如果你敲空格来对齐,说明你现在根本就不会用word)只有英文单词间才会有空格,中文文档没有空格。所有的对齐都应该利用标尺、制表位、对齐方式和段落的缩进等来进行。如果发现自己打了空格,一定要谨慎,想想是否可以通过其他方法来避免。同理,一定不要敲回车来调整段落的间距。
其他建议:
12. 使用大纲视图写文章的提纲,调整章节顺序比较方便
13. 使用文档结构图定位章节 (文档结构图不仅方便,更要学会熟练应用)
14. 使用文档保护,方便文章的审阅和修改
15. Word表格的排序、公式和转换的功能也是很值得学习的
最后一句,尽量利用word来减少自己的工作量,只要是机械作业,那么word应该会有相应的功能进行处理,要不然,word也不会成为文字处理界的大佬!
第二篇:数学建模论文学习总结
数学建模论文学习总结
论文对应试题:
一、20##年国赛B题 碎纸片的拼接复原 3篇
二、20##年国赛A题 车道流量 3篇
三、20##年国赛B题 葡萄酒
*以上论文按序分别记为 ① —— ⑩ ,具体顺序请看附录
接下来将针对不同题目的论文进行学习总结
一、碎纸片的拼接复原
1.1建模思路
三篇文章的基础都是以matlAB中的图像处理函数为基础,将图片信息转为矩阵的数值信息,接下来对不同图片的数值信息进行运算、操作从而达到拼接的目的。
imread函数可直接获得图片的灰度矩阵信息
收获:matlAB中的图像处理函数可以有效地让图像问题转化为数值问题
相关系数法的应用也可以用在距离关联上
图论算法在解决非数值问题上的优势
分类讨论的重要性(先拼层,在层间拼接)
1.1.1论文①
·建模框架:
以MATLAB中的图像处理函数imread为基础,利用纸片边缘对应的矩阵信息,采用穷举法进行判断,即确定第一张后,每一张都与其匹配,从而得到拼接顺序
问题一,此部分是该论文的基础,在确定了imread函数处理和穷举法匹配后,该文章列出了几种不同的碎片比较方法,即最短距离法,欧式距离法,相关系数法。把碎片拼接问题转化为两组数是否吻合的问题。这里三种方法的应用比较厉害。用很简单的公式,解决了比较复杂的问题,比起其他文章大量的复杂公式,应该是占据上风。在确认拼接的部分,文章采用了求相对平均偏差的做法,使得拼接结果更可靠,文章也更有说服力。并在对附件一进行拼接时分别采用了二值法和不采用二值法。
问题二,文章非常精彩的采用了“分层”和“涂黑”的作为基础,周全的考虑到了中文字体高度相同,英文字母高度不一、碎片空白等问题,采用了聚类分析等办法。并且由于数据改变(从“竖条”变成“小块”),采用了不同的比较方法。
问题三,文章不分正反面,相当于拼接2张,但是由于难度增加,人工干预明显增加,是本文的一个弱点。
·特征优势及创新
写作部分非常好!内容有序,没有赘述,语言精练。在各个模型下都有一张思路清晰,又非常美观的流程图。在一些重点部分也有流程配图。让读者非常清晰地了解其模型的运行情况。文字叙述部分,段落、分级要点都非常的清晰,整篇论文也是循序渐进,由浅入深,从思路到模型到利用模型拼接井井有条,不过在一些计算数据的表示上却有些凌乱
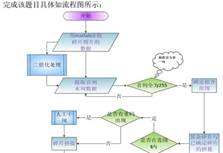

流程图 计算数据
在文章的模型方面,该文章循序渐进,很好的捕捉了题目的要求,对碎片复原问题由简到繁,从纵切的基础上一点点的改变切割条件,解出余下问题。在碎片的拼接部分,文章在一开始就列出了三种方法,而后在每一个问题中都对三种方法进行了比较。
1.1.2论文②
·建模框架
将碎片拼接问题转化为有限个碎片的排序问题(注意到这里是排序而上一篇是穷举匹配),利用图论算法,旅行者问题对排序问题进行求解。再借助灰度图像中聚类方法的最小色差法,得到匹配距离,以此表示碎片间的差异大小。
问题一,先以旅行商问题为基础,图片的匹配顺序就可以由图论得出结果
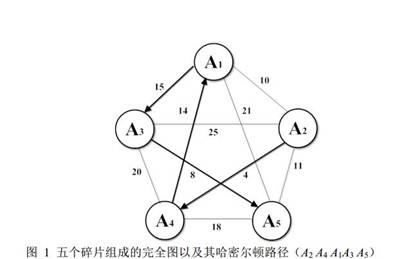
利用哈密尔顿路径,这样所得到的顺序一定是全局最优的,即是最终结果。
但是在不同图片之间,仍需要判断它们的与前一张碎片的匹配程度,文章用到了计算匹配距离的方法。借鉴灰度图像的聚类方法中的最小色差法,在这里,采用两两图像边缘像素
点的差异大小作为衡量标准,以此判别两张碎纸片图像匹配的可能性。所以在这里的匹配距离等价于差异大小。
问题二,考虑纸张被纵切会有一些碎片行,所以先根据文本行特征得到碎片行分组。
接着,利用问题一基于旅行商问题的拼接策略得到每个碎片行分组的拼接排列,得到被
还原的碎片行。再根据问题一基于旅行商问题的拼接策略将碎片行纵向拼接。但由于横纵切割的复杂性,文章先进行边界碎片查找,找到边界部分白色纸张碎片;接下来进行分行拼接。
在样本总体选取各行的碎片这一部分,文章根据中英文字体的不同,建立了中英文不同的行距特征向量进而分行拼接。
问题三,在这部分拼接思路与问题二相同,但是由于双面拼接的特点,文章将文本行距匹配距离替换为正反文本行距匹配距离,并且模型改进为多旅行商问题。
·特征优势及创新
采用图论算法,旅行商问题来解决拼接顺序问题,这样在距离匹配后可以更好的得到结果,大大减少了人工干预。
程序运用比较出色。
但是在文章叙述方面有些赘余,并且写作部分有待加强,很多地方公式凌乱,看起来不美观。
1.1.3论文③
·建模框架
建立信息矩阵,获得碎片矩阵信息后,在计算匹配度后采用TSP模型求解整体最优匹配度得到匹配序列。在横纵切问题中同样采取对中英文碎片分别取特征向量,进行分行聚类的办法。
本文与②的思路基本一致,但是从各方面来说,都是②的升级版,所以在特征优势部分进行主要总结
·特征优势及创新
相比于②来说,基本算法和思路都是一样的,但是由于本文写作方面比较优秀,思路清晰,深入浅出,在关键步骤有流程图,较之前者有较大优势
在本文最后还有对模型的进一步改进,并不只局限于本题。
而在问题二中的人机交互软件的问题,我的水平有限,不知道算是画蛇添足还是锦上添花。
二、车道被占用对城市道路通行能力的影响
2.1建模思路
第一二问观察视频材料
第三四问建立交通波模型和排队论模型,把车道通行能力用交通流的数值表达,再通过计算机仿真计算排队长度
2.1.1论文④
·建模框架
文章建立了排队模型,将车辆车道问题抽象标准排队论的服务台问题。即车道为服务台,车辆为顾客。并将车辆到达近似为泊松分布 ,由于红绿灯的影响,车辆到达会有明显的周期性。在简化问题与实际情况的原因下,文章将实际通行能力抽象成为车道横截面车流量。
文章也建立了交通波模型,利用格林希尔治模型,以及交通流量模型,推导出了排队时长与通行能力的关系。
问题一,观察材料,人工计数得到材料中车流量的情况,再进行整理,并表格化,图像化,最后进行结合实际的阐释
问题二,同上
问题三,建立交通波模型
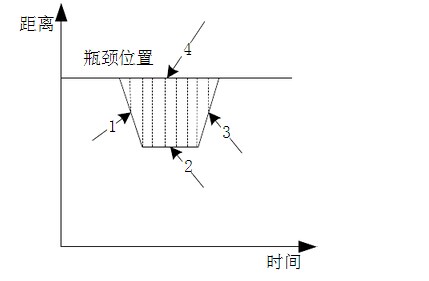


而在这里可以由交通运输方面的知识推导出最终的公式,接下来要做的就是确认所得公式是不是能反映实际情况。通过比对前两问所得数据,再进行计算机仿真,最终结果发现模型符合实际。
问题四,在这里相当于一个预测问题,但是由于三四问的相似性,修改一部分问题三的模型和仿真代码即可在问题四应用,得到预测结果。
·特征优势及创新
在计算机仿真部分有清晰明了的流程图
建立模型不繁琐,两个模型都很好的应用到了问题中,没有赘余的部分
在模型评价的部分,文章在说明优点后,用了大量篇幅非常详细具体的进行了对自己模型的改进,个人认为是一个闪光点
在最后有一个模型推广部分,这使得这篇文章又提高了一个层次
2.1.2论文⑤
·建模框架
问题一,文章不仅仅是单一的采集视频中的数据,还采用了插值拟合的方法对材料所给交通情况进行了补充,并利用多个软件做出了多个图表来反映通行情况
问题二,与问题一类似,文章也是 得到了多个图表
问题三,文章利用多项式进行模拟,思路很好,用简单的公式解决复杂的问题,但是似乎有些凌乱,不能很好的反映结果,而且有很多模型都没有说明,让人云里雾里,最后所得关系也是复杂凌乱
问题四,沿用多项式进行预测,所得结果在常识方面就是错的
·特征优势及创新
本文应当说是很不成功,可以做一个反面典型。
在写作方面,毫无章法,在分点叙述的部分很乱,不容易让人有一个清晰的认识,在公式和图表方面也是没有统一格式和排版,会给文章大打折扣


在建模方面,没有清晰的建模思路,前两问的优势是图像很多,但是却不能清晰的表达问题的实质。而在后两问,没有具体的模型和方法,有些东拼西凑的感觉,最后导致结果也是相差甚远。
2.1.3论文⑥
·建模框架
以观察材料得来的数据为主进行一二问的解答
通过车流波动理论分析排队模型,在三四问再结合数据进行模拟
问题一,问题二,观察视频得到车流数据,在这里文章并没有将自行车,摩托车等非主要车辆忽略,而是对其进行了初始模糊划分,并由初始聚类中心得到了各种车辆的换算系数。
将得到的数值处理后图像化,第二问中同时也有对比。
问题三,文章通过车流波动理论建立排队模型,
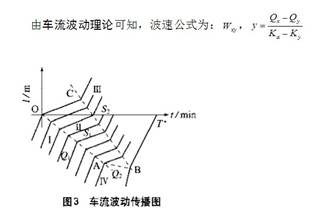

通过公式的推导,最终得到关系式
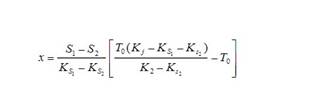
问题四,在第三问的基础上,带入相应数据,便可以得到结果。
·特征优势及创新
在第一问中采取模糊划分
在关键部分有配图
所得公式较为简单,解决了复杂的问题
三、葡萄酒的评价
3.1建模思路
问题一采用显著差异性模型判断没有显著差异,进而用其他检验方法确定更可靠的一组
问题二用适当方法确定权重,进而利用评价方法得到评价
问题三采用相关分析,确定不同因素的关系
问题四采用多元回归分析来确定多个指标对葡萄酒质量的影响
3.1.1论文⑦
·建模框架
问题一,采用排序检验法对总分进行排序,根据不同排序的秩次求样品的秩和,最后通过秩和的wilcoxon符号秩检验,非参数检验方法评价结果是否有显著差异。最终判断结果可靠是通过方差来判断,方差小的那一组更可靠。并且采用两种评价检验使得结果准确。
问题二,对芳香指标和香气评分进行相关性分析,反映了二者的关系密切程度。又进行了基于TOPSIS法的秩次排序,确定理想点并计算各样本与其的接近程度,而后进行秩次排序。在多重比较的基础上,进行了葡萄酒的分级。
问题三,由于指标数目多,所以考虑先对各指标进行降维,减少指标个数。文章采用了主成分分析的方法。接下来对两组主成分进行了回归分析并检验。
问题四,因为前三问已经将葡萄酒的质量和酿酒葡萄的理化指标转化成了秩和,所以文章在此将葡萄酒的理化指标也转化为秩和。方法同上。接下来对三种排序做了相关性检验,得到了结果。
·特征优势及创新
文章写作条理清晰,辅以图片。
建模思路上层层递进,先介绍解决问题的方向,再按此方向进行解题,并且全文一直在应用秩和排序和相关性检验,可见作者功底深厚。
3.1.2论文⑧
·建模框架
问题一,采用Wilcoxon符号秩检验,同时,由于平均评分符合正态分布,采用正态检验对Wilcoxon符号秩检验结果进行验证
问题二,多元线性回归是研究多个自变量与一个因变量间是否存在线性关系(相互依存关系),并用多元线性回归方程来表达这种关系(或用回归方程定量地刻画一个因变量与多个自变量间的线性依存关系)的数学分析方法。问题正是要求出葡萄的多个理化指标和葡萄酒的质量之间的联系,因此本文采用多元线性回归模型。
问题三,利用统计回归模型,将多元线性回归和协方差阵综合起来,相当于多个自变量与多个因变量之间的线性关系。
问题四,
·特征优势及创新
多元线性回归运用很多,一个模型解了多个问题
在回归方程的表示上非常清晰:

3.1.3论文⑨
·建模框架
问题一,文章分为三部分:
步骤一:葡萄酒样本评分概率分布的确定,其目的是确定显著性差异模型的类型;
步骤二:两组评酒员评价结果的显著性差异模型的建立,主要通过Wilcoxon符号秩检验法进行显著性差异的假设检验;
步骤三:建立秩相关分析评价模型,并通过该模型判断两组品酒员评价结果在可信度方面的优劣。
问题二,
步骤一:酿酒葡萄27种指标之间的关系研究,目的是构建评价模型的指标体系;
步骤二:建立综合评价模型,并通过该模型对步骤一得到的指标进行多指标综合评价,以对酿酒葡萄进行分级。
问题三,
步骤一:建立典型相关分析模型,其目的是分析酿酒葡萄与葡萄酒的理化指标之间的典型相关关系;
步骤二:根据上面的分析给出酿酒葡萄与葡萄酒的理化指标之间的联系
问题四,
步骤一:对样本进行随机筛选,选择??nnN?个进行分析;
步骤二:在问题三分析酿酒葡萄与葡萄酒的理化指标间联系的基础上对样本指标进行初步筛选;
步骤三:利用筛选后的指标与葡萄酒质量评价结果,建立多元线性回归模型;
步骤四:然后根据剩下的??Nn?个样本对的酿酒葡萄和葡萄酒的理化指标,对葡萄酒质量求解得到的多元线性回归方程进行验证
·特征优势及创新
多元线性回归特征清晰
文章整体思路清晰流畅
-
word心得
Word学习心得姓名:张林林学号:20xx01006081班级:10中药2班文字处理是当前社会用处最广泛的东西,因此Word的出现…
-
word使用心得
Word使用心得1双击格式刷可以无限次使用2插入一个表格后如果想将表格上下分开将光标定位在分开点的下方表格某个位置上按下CtrlS…
-
几点word使用心得
几点word使用心得word的恢复最近一直喜欢用界面自定义但是一不小心就被我改的乱七八糟了所以以下方法用于恢复最初默认界面方法1点…
-
word,excel使用心得大全
1问WORD里边怎样设置每页不同的页眉如何使不同的章节显示的页眉不同答分节每节可以设置不同的页眉文件页面设置版式页眉和页脚首页不同…
-
word使用心得
WORD使用技巧适合初学者三招去掉页眉那条横线1在页眉中在格式边框和底纹中设置表格和边框为无应用于段落2同上只是把边框的颜色设置为…
-
word心得
Word学习心得姓名:张林林学号:20xx01006081班级:10中药2班文字处理是当前社会用处最广泛的东西,因此Word的出现…
-
word 382 山香书籍知识学习心得
1.欧·亨利简介。2.“俩狂”的背景。3.李白:字、别号、人称、齐名、派别及作品成就、韩愈称赞。4.诗人别称及其艺术特色:李白、杜…
-
word排版软件的使用总结
Word排版软件的使用1.Word排版软件的发展历史。2.Word20xx基本结构及其窗口各组成部分功能的简介。3.新建文件的方法…
-
word,excel使用心得大全
1问WORD里边怎样设置每页不同的页眉如何使不同的章节显示的页眉不同答分节每节可以设置不同的页眉文件页面设置版式页眉和页脚首页不同…
- word学习心得1
-
20xxB数学建模竞赛优秀论文总结
问题一分为三个子问题。第一个子问题要求对A区20个交巡警平台的管辖路口进行分配。考虑到题目要求在案发时警察要尽量在3分钟内赶到,因…