Stata学习笔记和国贸理论总结
Stata学习笔记
一、认识数据
(一)向stata中导入txt、csv格式的数据
1.这两种数据可以用文本文档打开,新建记事本,然后将相应文档拖入记事本即可打开数据,复制
2.按下stata中的edit按钮,右键选择paste special
3.*.xls/*.xlsx数据仅能用Excel打开,不可用记事本打开,打开后会出现乱码,也不要保存,否则就恢复不了。逗号分隔的数据常为csv数据。
(二)网页数据
网页上的表格只要能选中的,都能复制到excel中;网页数据的下载可以通过百度“国家数据”进行搜索、下载
二、Do-file 和 log文件
打开stata后,第一步就要do-file,记录步骤和历史记录,方便日后查看。Stata处理中保留的三种文件:原始数据 (*.dta),记录处理步骤 (*.do),以及处理的历史记录 (*.smcl)。
三、导入Stata
Stata不识别带有中文的变量,如果导入的数据第一行有中文就没法导入。但是对于列来说不会出现这个问题,不分析即可(Stata不分析字符串,红色文本显示;被分析的数据,黑色显示);第一行是英文变量名,选择“Treat first row as variable names”
在导入新数据的时候,需要清空原有数据,clear命令。
导入空格分隔数据:复制——Stata中选择edit按钮或输入相应命令——右键选择paste special——并选择,确定;导入Excel中数据,复制粘贴即可 ;逗号分隔数据,选择paste special后点击comma,然后确定。 Stata数据格式为 *.dta,导入后统一使用此格式。
四、基本操作(几个命令)
(一)use auto,clear 。在清空原有数据的同时,导入新的auto数据。
(二)browse 。浏览数据。
(三)describe 和 list。查看数据,describe 和 list 使用list命令能使我们根据自己的需要选择数据(例如其与in/if语句的结合使用)。
(四)Scatter。作图命令,scatter 散点图 (scatter price mpg )
(五)Summarize。描述统计,常写作sum/su,求变量的个数、平均值、标准差、最小值和最大值。
(六)generate。生成数据,简写为gen。
(七)replace。修改数据,命令 replace 该命令不推荐使用,一般不会改变原始数据的。剔除缺失值、异常值, 或者批量修改数据均可以通过 replace 命令加上条件语句实现.
(八)Tabstat 。描述性统计,tabstat 变量列表,statistics(统计量列表)
(九)Rename 。对变量更名,rename 旧变量名 新变量名。一次只能对一个变量名重命名。
(十)Order 。对变量排序,order变量列表[,选项]
(十一)Sort/gsort 。对观测值排序,sort 变量列表;gsort [+/-]变量,注意,方括号可有可无。Sort是升序排序,当第一个变量出现相同时,才会对第二个变量排序,否则是不会管后面的变量的排序的;gsort(general sort)即可升也可降,视+和-而定。为了保证数据的原始性,为了最后恢复数据排序,一般在排序前,生成新的变量num,最后对num排序就可以恢复。
(十二)Keep/drop 。保留/删除变量或数据,keep/drop 变量列表;keep/drop 条件。注意:请不要随意删除变量或数据,因为可以使用if条件句!(对行改变)每一次只能使用keep 和drop 中的一个命令。
(十三)Count 。按条件对观测值计数,count [条件],方括号可有可无,直接输入条件。
(十四)Recode 。批量修改观测值,recode 变量列表(规则),括号必须有。规则如下:#=#,比如3=1,值为3的全改为1;#/#=#,比如min/3000=0,3000以下全为0。如果加generate,则会生成新的变量。规则为:recode 变量列表 (规则)(规则), gen (新变量)。
(十五)Encode/decode。字符串与数值转换,encode变量,generate(新变量)。将stata不能识别的红色字符串改为数值,而且必须生成新变量,即
generate(新变量)不能省。Decode是将label 的数值转换为字符串变量,也必须生成新变量,即generate(新变量)不能省。
(十六)Display。 显示字符串/变量值,display 字符串或变量或表达式。 By/bysort 分组地重复执行某一命令:by 变量列表;bysort变量列表。By后面一般是一个类别的变量。一般在命令前加by 变量列表:就可以,冒号后的命令碧血是完整的。此命令实际是先按变量列表分组,然后再执行后面的命令。 Egen 生成新变量:egen 新变量= 函数表达式。Generate 新变量= sum(变量)是逐个加总,egen 新变量= sum(变量)是求和。
(十七)Forvalues/ Forrach。循环命令,Forvalues 有规律的循环,Forrach 任意循环。
(十八)Reshape。 面板数据的变换,reshape long 变量列表, i(样本变量名) j(时间变量名); reshape wide 变量列表, i(样本变量名) j(时间变量名) (十九)merge。横向拼接,merge 拼接形式 变量列表using 被拼接数据集。merge 命令是用于横向拼接, 即为了增加变量。拼接形式有1:1、1:m、m:1 和m:m 四种。“1” 方是需要复制多份, 并与“m”方拼接的; 而“m” 方的记录数是不会增加的。变量列表是在拼接时, 用于识别拼接记录的; 一般是两数据集的共同变量. 可以是一个, 也可以是多个. 比如要把学生的考试成绩(变量为姓名、考试科目、成绩) 和学生学号(变量为姓名、学号) , 那么姓名就是这里用于识别的变量。被拼接数据集只支持*.dta 格式数据。若被拼接数据集的名称中包含空格, 请将其置于英文状态下的引号内。若被拼接数据集不在Stata 当前路径下, 请在数据集名称前加上路径, 支持放在英文状态下的引号内。
(二十)append 。纵向拼接,append using 一个或多个数据集。append 命令是用于纵向拼接, 即为了增加样本或观测值。此命令支持多个*.dta 文件拼接, 多个数据集需用空格隔开。
(二十一)Duplicates。删除重复数据,duplicates report 变量列表,报告是否有重复。duplicates list 变量列表,列出重复的;duplicates tag 变量列表,generate(新变量),报告重复的,并生成新变量;duplicates drop 变量列表,删除重复的;duplicates drop 变量列表, force,强制删除重复的
五、模型选择
建模应首先考虑数据类型(截面数据、时间序列数据和面板数据以及各种数据类型的特点)。在Stata 中,时间序列数据必须含有一个时间指标用于刻画有序的时期。用到的命令有:
date
日期转换函数,将日期字符串(红色) 转换成数值(黑色)
命令中的日期字符串和格式字符串默认是要放在英文状态下的引号中,但若日期字符串是一个变量,而且他本身就是字符串格式的变量,那么在写命令时直接用变量名替代日期字符串即可。
反向提取:如要从数值型的日期中提取年、月、日,使用year(), month(), day()函数。
format,数据显示格式命令
1.若是时间数据(黑色的数值),则会以时间格式(%fmt)的具体形式来显示; 若是数值数据,可以用%fmt 来设置其显示格式;
3.若是字符串数据,可以用%fmt 来限定其长度。
tsset:,通过指定时间指标
在Stata 中,必须先指定时间指标,才能进行接下来一系列的时间序列分析(面板数据也是同样道理),否则Stata 会将其当做截面数据。
在Stata 中,用距离1960 年1 月1 日有多少天(即一个整数)来表示日期,故其实是数值。
(一)定义时间序列
命令格式:gen 新时间变量= date(日期字符串, 格式字符串); format 变量列表%fmt;
tsset 时间指标。
前两个命令是将字符串的时间格式改成Stata 能识别的时间格式,第三个命令是去识别这个时间序列。
(二)定义面板数据
命令格式:xtset 个体指标时间指标。需要两个指标,需要注意顺序。如果被解释变量y 取离散值,那么就不能使用普通的线性模型进行建模。 根据模型的特性和缺陷,可以建立如下模型:
1.稳健性回归模型: rreg
2.工具变量模型: ivregress
3.选择模型: logit/probit
4.分位数回归模型: qreg
5.时间序列模型: arch/arima/var
6.面板数据模型: xtreg/xtivreg/xtlogit/xtprobit
上述模型可以综合使用,比如面板-logit 模型,面板-2SLS 模型等。
六、操作及导出输出结果
(一)求变量间协方差/相关矩阵
correlate 变量列表[, 选项]。若要求协方差矩阵,则选项中需要加covariance 选项。协方差/相关矩阵是对称矩阵,所以为了简化此命令生成的矩阵下三角部分。此命令计算的是Pearson 相关系数/协方差矩阵。
(二)求变量间的相关矩阵
pwcorr 变量列表[, 选项]。与correlate 命令类似,即求多个变量之间的相关矩阵,这里具体指的是成对相关系数(Pairwise Correlation);与correlate 不同的是,它能尽可能使用两两变量中所有没有缺失的数据。此命令计算的是Pearson 相关系数矩阵。
(三)绘制矩阵散点图
graph matrix 变量列表
(四)绘制直方图
histogram 变量[, 选项]。直方图不连续,若想连续请参看核密度图
常用选项:bin(#),以组数#来绘制直方图;width(#),以组距#来绘制直方图; frequency ,纵坐标显示频数(默认情况下显示频率)
(五)绘制核密度图
kdensity 变量[, 选项]
(六)绘制散点图
scatter 两变量, twoway (scatter 两变量) (lfit 两变量)。scatter 命令用于绘制两变量的散点图,用于观察变量间的相关关系;lfit 命令可以大致绘制拟合散点的直线;通过scatter 和lfit 两个绘图命令,可在一幅图中实现这两个功
能。只能绘制二维散点图,且只能知道两变量的大致相关关系(正/负相关),不能知道拟合直线的具体数值。
七、回归及结果导出
(一)命令汇总
1. 普通线性模型: regress
2. 稳健性回归: rreg
3. 工具变量模型: ivregress
4.离散选择模型: logit/probit
5. 分位数回归模型: qreg
6.时间序列模型: arch/arima/var
7.面板数据模型: xtreg/xtivreg/xtlogit/xtprobit
8.结果导出: esttab/outreg2
(二)regress, 回归分析
regress 被解释变量解释变量列表[条件] [权重] [, 选项]。regress 是最小线性二乘回归(OLS, Ordinary Least Squares) 的命令,可简写为reg;regress 命令后直接跟变量,其中解释变量若有多个则用空格分隔开;变量允许使用交叉项,命令c.x1#c.x2 表示将x1 · x2 作为解释变量加入到模型中;条件是筛选用于回归的样本;权重这个选项是用于建立加权回归模型(WLS);选项是很强大的,如:
1.vce(类别) 在回归使用稳健的方差(常用于避免异方差的出现),如robust, cluster;
level(#) 用于指定置信度。如level(99);beta 针对数据变化大,需要将变量先标准化后再回归;
3.noconstant 用于建立无常数项的回归方程;回归后得到的估计值/统计值被保留在e() 内,供用户提取;
若要计算模型拟合值和残差,运行regress 命令后使用predict命令进行
5.回归结果输出
esttab [回归名列表] using 文件名. 扩展名[, 选项]。回归名列表指的是将多个回归结果一同导出(如果不指定,则默认将最近的一次回归结果导出),可以每
做完一次回归将结果用下列命令保存下来。. est store 回归名,导出到Word 文件中,扩展名rtf。
常用选项: r2, ar2 分别输出R 和R的值;用se 表明括号中的值为标准误,否则会默认输出t 检验值;replace 覆盖同名文件;nogap 忽略表格中的空行。
outreg2 命令的使用方法类似,在使用之前,需要从网上下载此命令,步骤如下:
确保电脑已经联网;
打开Stata,在命令窗口按照如下格式输入命令:
ssc install 命令名(或者命令组)
当输入完毕敲击回车后,一般等待半分钟即可下载并安装完毕。在Stata 结果显示窗口会显示installation complete.
一般地,我们会用到estout, outreg2, logout 这几个用于输出结果的扩展包
estout 是命令组的名称,而esttab 只是这个命令组中用于输出结果的命令,即下载时应输入 ssc install estout 22
八、常用概率分布函数
命令格式及含义说明:
normal(x): 输入x值返回对应值的标准正态CDF值;
normalden(x): 输入x值返回对应值的标准正态PDF值;
3.invnormal(p): 已知概率p(即PDF 曲线下面积),反推x值。
对于CDF,若从+1 向?1 反向进行累计,则称为tail,函数名为ttail/Ftail/chi2tail,对应的inv函数为invttail/invFtail/invchi2tail。
(二)使用方法:
1.和generate 命令合用,生成服从这样分布的新变量(若在做Monte Carlo 模拟时需要生成服从某一分布的随机数, 请使用runiform()/rbeta(a, b)/rchi2(df)/rnormal()/rt(df) 等命令, 详细请help random_number_functions); 和display 命令合用,直接算出值,也叫做查表(统计表);
3.和twoway function 命令合用,画出函数图。
(三)函数图(twoway function)
1.命令格式:twoway function [[y]=] f(x) [if] [in] [, 可选参数]。
2.含义说明:用于绘制函数图。
y 是一个标注符号,即绘制图线后用y这个记号来标注,如有多条直线可以标注成y1, y2,??
f(x) 是这个命令的主体,可以是一般数学函数式,也可以是Stata内已有的函数1;
可选参数中一般会用到range(# #),即坐标横轴的取值范围,如range(-5 5) 表示x∈(?5, 5);
如果要绘制多个函数图,可在语句后继续写function 后面的部分,并用||符号连接。
3.注意事项
自变量必须是x;
方括号内的部分均可省略,即可省略“y =” 这个部分;
这里的y 和x 都仅针对这个命令的,故不会影响Stata 内存中已存在的数据。
4. 三σ原则:
在正态分布中σ代表标准差, μ代表均值,x = μ即为图像的对称轴,有: 数值分布在[μ?σ,μ+σ] 中的概率为0.6827;
数值分布在[μ?2σ,μ+2σ]中的概率为0.9544;
数值分布在[μ?3σ,μ+3σ]中的概率为0.9974。
(四)假设检验:根据一定假设条件由样本推断总体的一种方法
步骤:
1.根据问题的需要对所研究的总体作某种假设,记作H0;
2.选取合适的统计量,这个统计量的选取要使得在假设H0成立时,其分布为已知;
3.由实测的样本,计算出统计量的值f,并根据预先给定的显著性水平α进行检验,查对应统计分布表的临界值fα;
4.比较f 与fα 的大小,最终作出拒绝或接受假设H0的判断。
5.注意事项
一般为了方便,H0为等式,此时的H0可以作为已知条件代入第3步的计算中;在众多假设检验中,万变不离其宗看H0,如果拒绝H0,说明其对立面在给定的显著性水α下是在成立的;由于查统计表时,临界值fα的选取还与显著性水平α有关,所以在计量经济学中经常用反查表的方法,即不找fα,而是找f值所对应显著性水平α,记为p 值,并作出判断:
p 值越小,即接近于0,说明在(1 ? p) 的置信度水平上拒绝H0都是可信的, p 值越大,说明在置信度水平(1 ? p) 越小,拒绝H0越没有把握。
(p 值的大小判断是比较主观的. 一般来说, p > 0.1 算大, p < 0.05 算小,但是这并不绝对。)
九、五个经典假设
对于模型:y=β0+β1x1+β2x2+?+βnxn+μ,在满足下列5 个假设的前提下,OLS的估计是最佳线性无偏估计(Best Linear Unbiased Estimator),即:
1. 线性模型,即系数之间要是线性的;
2. 随机抽样/无序列相关,即样本之间无相关性;
3. 无多重共线性,即解释变量间不构成高度线性相关;
4. 无内生性,即误差项与解释变量不相关,也即cov(μ,X)=0
5. 误差项均值为零,方差为常数,即E(μ)=0,,Var(μ)=σ2
(一)违背五个经典假设:
1.线性模型
? 一般不存在这个问题;
? 这里的线性模型指的是待估参数之间的关系是线性的,是广义的线性关系;
? 线性模型是对现实的抽象,虽然有诸多不足的地方,但是是最通用的方法;
? 除非是我们预先知道/从散点图中明显观察到非线性的关系,否则请从线性模型开始尝试。
常用命令:
? gen x2 = x^2 // 生成平方项
? gen lnx = ln(x) // 生成对数项
? gen x1x2 = x1 * x2 // 生成交叉项
一般在回归之前会对数据进行整理,用平方项来描绘二次关系,用对数项降低数据波动,用交叉项来探寻交叉关系(一般用于虚拟变量)。
注意:生成ln(x)函数需使用gen命令,而非egen命令。
2.序列相关问题
? 横截面数据很少会遇到序列相关问题,因为随机抽样的假定很容易满足; ? 时间序列数据则非常容易产生序列相关的问题,因为时间数据不能打乱顺序,且有连续性。
3.多重共线性问题
? 多重共线性一般发生在加入过多变量,且这些变量相关度很高时; ? 多重共线性会导致模型无法估计;
? 多重共线性的问题提示我们:加入模型中的变量要是来源不同的变量;我们在搜寻解释变量时,也要找多个方面的因素;
? 解决方案:去掉(多个共线性变量中的)某一个;
? 在加入下列变量时请注意:
○1虚拟变量;○2某一变量及其高次项;○3同一类但单位不同的变量。 常用命令:estat vif
说明:
? 在计量上我们用VIF统计量来反映多重共线性的大小:一般来说,若同时满足(1)最大的VIF > 10,(2)平均的VIF > 1,则说明存在多重共线性的问题;
? 此命令会输出每个变量的VIF、1/VIF,及平均VIF。
注意:此命令为reg的后续命令,即需要先运行一个回归,然后才能使用此命令。
4.内生性问题
? 内生性问题是指误差项与解释变量相关,即模型中的解释变量与无法观测到的因素有相关
? 内生性问题是最重要的问题,因为它会导致估计量是有偏的/不一致的。 ? 导致内生性的原因:
? 遗漏变量:如果遗漏的变量与其他解释变量不相关,一般不会造成问题。否则,就会造成解释变量与残差项相关,从而引起内生性问题;
? 解释变量与被解释变量相互影响;
? 度量误差(Measurement Error):由于关键变量的度量上存在误差,使其与真实值之间存在偏差,这种偏差可能会成为回归误差(Regression Error)的一部分,从而导致内生性问题。
? 解决内生性问题的方法主要有:
? 工具变量法(IV),即找到一个变量和内生化变量相关,但是和残差项不相关。在OLS的框架下同时有多个IV,这些工具变量被称为Two Stage Least Squares (2SLS) Estimator。具体的说,这种方法是找到影响内生变量的外生变量,连同其他已有的外生变量一起回归,得到内生变量的估计值,以此作为IV,放到原来的回归方程中进行回归;
? 自然实验法,即找到一个事件,该事件只影响一部分样本,或者只影响解释变量而不影响被解释变量;
? Difference-in-Difference (DID)法。思想是按照一定的标准,找到与样本match的控制组。在假设外在冲击同时影响两个组别的情况下,做差来剔除掉外界冲击的影响;
? 动态Panel。思想是将解释变量和被解释变量的滞后项作为IV。 常用命令: estat ovtest
说明:
? 遗漏高次项检测(Omitted Variable Test)。此命令只能检测是否遗漏了模型中解释变量的二次、三次、四次项;
? 此命令检测的原假设H0为:模型没有遗漏高次项。若p值小于某一特定值(比如0.05),则说明存在内生性问题,
? 需要考虑加入高次项再次回归,反之则不存在。
此命令为reg的后续命令,即需要先运行一个回归,然后才能使用此命令。 常用命令:ivregress 估计方法 被解释变量 外生解释变量列表
(内生解释变量列表= 工具变量列表)
说明:
? 此命令用于进行工具变量回归;
? 估计方法一般有2sls(两阶段最小二乘法)和gmm(广义矩估计方
法)
寻找工具变量更多是创造性的工作,而非Stata 可以帮解决(此命令的具体使用方法及案例请参考《高级计量经济学及Stata 应用》,陈强,第10章)。
5.异方差问题
? 异方差是违反了同方差的假设;
? 存在异方差会使标准误的估计受影响,继而会影响所有涉及到标准误的检验,如t 检验、F检验;
? 异方差只影响参数的标准误,并不会影响其估计,即满足前4个条件的OLS估计值依旧是无偏的,只是不能保证是否显著异于零。
常用命令:reg ... , robust
说明:
? 这个命令是以选项的形式加在reg 命令之后,使得回归的标准误是稳健的;
? 即使存在异方差的问题,这样估计出的结果也是可以正常进行各类检验的,与同方差情况一样。
此命令无法检测出异方差,不过一般而言已经足够了。
常用命令:estat hettest
说明:
? 异方差检测(Heteroskedasticity Test);
? 此命令检测的原假设H0 为:模型误差项是同方差的。若P值小于某一特定值(比如0.05),则说明存在异方差问题,反之则不存在。
注意:此命令为reg的后续命令,即需要先运行一个回归,然后才能使用此命令。
十、几个重要模型
面板数据:面板数据的优势在于既有界面维度的信息,也有时间维度的信息,可以帮助解决内生性的问题。
? 面板数据固定效应:其利用在时间维度上对异质性进行相减来消除内生性的问题;
? 面板数据随机效应:其认为异质性是与其他解释变量不相关的(即异质性情况不严重),然后按照传统方法进行处理。
命令格式:
? xtset 截面维度变量 时间维度变量// 回归前设置
? xtreg 被解释变量 解释变量, fe [选项] // 固定效应面板回归
? xtreg 被解释变量 解释变量, re [选项] // 随机效应面板回归
说明:
? 在进行面板数据处理时,必须要先进行第一步,即声明面板数据。声明的方法与时间序列的tsset 命令类似;
? xtreg 命令与截面情况下的reg 命令类似。若在逗号后加上fe,即指定进行固定效应(Fix Effect)面板数据回归;若加上re,则进行随机效应(Random Effect)面板数据回归。
在不知道使用固定效应还是随机效应时,可以进行Hausman 检验。在Stata 中需要先分别进行两个效应的回归,再进行Hausman 检验:
? 若p 值较小(比如小于0.05),应该使用固定效应;
? 反之,则应该使用随机效应。
(但是推荐使用FE)
非线性模型:
? nl: 单变量非线性回归
命令格式: nl 非线性形式 被解释变量 解释变量
说明:
? 此命令实现的是非线性回归(Non-linear Regress),第二个字母是“l”不是“1”;
? 非线性形式请参考help nl 中的例子;
? 此命令只能对单变量进行处理;
? 由于诸多限制,以及实际处理过程中我们无法预知其非线性形式,所以我们较少适用此命令。
? 离散被解释变量: 响应模型
解释变量是离散的并不影响我们的回归,但是如果被解释变量y也是离散的,那就不适宜用OLS 进行回归了:
? 扰动项服从两点分布,非正态分布;
? 拟合值会出现超出0~1范围的值,不符合模型实际含义。
? logit/probit: 二值响应模型
命令格式:
? logit 被解释变量 解释变量
? probit 被解释变量 解释变量
? mfx
? mfx, predict(outcome(#))
说明:
? logit/probit 命令与reg 命令类似,但是其估计结果中的系数不是衡量变量的边际效应,因为这是非线性模型;
? 使用mfx 命令可以让Stata 在回归后计算边际效应;
? 若mfx 命令后不加选项默认计算y = 1 时的边际效应;
? 对于多值响应模型,一般要用predict(outcome(#)),选项指定y = # 时的边际效应。
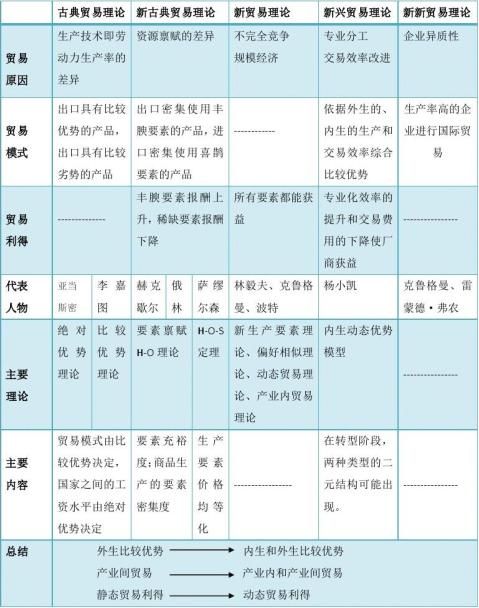
国际贸易理论学习笔记
-
社区20xx年干部理论学习总结
XXXXX社区20xx年干部理论学习总结在即将过去的20xx年中,XXXX社区认真开展干部理论学习工作,在社区党组织建设、社区建设…
-
20xx寒假政治理论学习总结
路孔镇高店小学20xx年寒假政治业务培训工作总结根据《荣昌县教育委员会关于做好20xx年中小学寒假工作的通知》荣教政发[20xx]…
-
教育理论学习总结
宁阳二十中郭修军通过学习现代教育理论,我总结到,课堂教学在学校工作中居于十分重要的地位。学校要想减轻学生负担,卓有成效地实施素质教…
-
公共部门人力资源管理理论学习总结
公共部门人力资源管理理论学习总结我们电大本学期开设了公共部门人力资源管理这门课程,我从事人力资源工作,所以相较于其他课程来说,我对…
-
小学教师业务理论学习总结
教育教学理论是教育教学工作的先导。作为新时期的教师,一个重要的标志,就是要有丰富的教育教学理论知识。如果没有一定的理论底蕴,对教育…
-
科研训练总结 研究矩阵理论
科研训练总结数学科学学院柏慧荣2910102024本学期我参加了学院组织的科研训练讨论课,我参与的方向主要是研究矩阵理论。虽然上课…
-
管理学基础理论总结
第一章管理概述管理从事计划组织控制领导和激励五项基本活动管理的工作有效性是从效率和效力效果来看的即高效做事做正确的事用正确的方法管…
-
矩阵论小结
矩阵论线性空间定义本质是个集合满足一定条件下的集合首先定义了加法运算满足加法的交换结合律在这个集合中能找到零元素与负元素然后定义数…
-
矩阵理论考试总结
1向量矩阵是一个严密的数学概念数组是计算机上的一个名词一组数而已非要赋予数组数学含义则一维数组相当于向量二维数组相当于矩阵矩阵是数…
-
总结求矩阵的逆矩阵的方法
总结求矩阵的逆矩阵的方法课程名称专业班级成员组成联系方式摘要矩阵是线性代数的主要内容很多实际问题用矩阵的思想去解既简单又快捷逆矩阵…