译码器实验报告
深 圳 大 学 实 验 报 告
课程名称: 数字逻辑与数字系统
实验项目名称: 译码器
学院: 计算机与软件学院
专业:
指导教师:
报告人: 学号: 班级:
实验时间:
实验报告提交时间:
教务部制

深圳大学学生实验报告用纸

注:1、报告内的项目或内容设置,可根据实际情况加以调整和补充。
2、教师批改学生实验报告时间应在学生提交实验报告时间后10日内。
第二篇:哈夫曼编码译码器实验报告
问题解析与解题方法
问题分析:
设计一个哈夫曼编码、译码系统。对一个ASCII编码的文本文件中的字符进行哈夫曼编码,生成编码文件;反过来,可将编码文件译码还原为一个文本文件。
(1) 从文件中读入任意一篇英文短文(文件为ASCII编码,扩展名为txt);
(2) 统计并输出不同字符在文章中出现的频率(空格、换行、标点等也按字符处理);
(3) 根据字符频率构造哈夫曼树,并给出每个字符的哈夫曼编码;
(4) 将文本文件利用哈夫曼树进行编码,存储成压缩文件(编码文件后缀名.huf)
(5) 用哈夫曼编码来存储文件,并和输入文本文件大小进行比较,计算文件压缩率;
(6) 进行译码,将huf文件译码为ASCII编码的txt文件,与原txt文件进行比较。
根据上述过程可以知道该编码译码器的关键在于字符统计和哈夫曼树的创建以及解码。
哈夫曼树的理论创建过程如下:
一、构成初始集合
对给定的n个权值{W1,W2,W3,...,Wi,...,Wn}构成n棵二叉树的初始集合F={T1,T2,T3,...,Ti,...,Tn},其中每棵二叉树Ti中只有一个权值为Wi的根结点,它的左右子树均为空。
二、选取左右子树
在F中选取两棵根结点权值最小的树作为新构造的二叉树的左右子树,新二叉树的根结点的权值为其左右子树的根结点的权值之和。
三、删除左右子树
从F中删除这两棵树,并把这棵新的二叉树同样以升序排列加入到集合F中。
四、重复二和三两步,
重复二和三两步,直到集合F中只有一棵二叉树为止。
因此,有如下分析:
1. 我们需要一个功能函数对ASCII码的初始化并需要一个数组来保存它们;
2. 定义代表森林的数组,在创建哈夫曼树的过程当中保存被选中的字符,即给定报文中出现的字符,模拟哈夫曼树选取和删除左右子树的过程;
3. 自底而上地创建哈夫曼树,保存根的地址和每个叶节点的地址,即字符的地址,然后自底而上检索,首尾对换调整为哈夫曼树实现哈弗曼编码;
4. 从哈弗曼编码文件当中读入字符,根据当前字符为0或者1的状况访问左子树或者右孩子,实现解码;
5. 使用文件读写操作哈夫曼编码和解码结果的写入;
解题方法:
结构体、数组、类的定义:
1. 定义结构体类型的signode 作为哈夫曼树的节点,定义结构体类型的hufnode 作为哈夫曼编码对照表的节点,定义HFM类实现对哈夫曼树的创建,利用其成员函数完成哈夫曼编码译码的工作。
2. 定义signode 类型的全局数组SN[256](为方便调用,之后的forest[256],hufNode[256]均为全局数组), 保存ASCII编码的字符,是否在文章中出现(bool类型)以及出现次数(int类型,权重),左右孩子节点位置,父节点位置信息;
3. 为节省存储空间,定义signode * 类型的全局数组forest[256], 模拟森林,在创建哈夫曼树的过程中保存出现字符的指针,模拟哈夫曼树选取和删除左右子树的过程;
4. 定义hufnode 类型的全局数组hufNode[256],在编码时最为哈夫曼编码对照表的节点,char 型c保存字符,int code[100]保存其哈夫曼编码;
5. 定义HFM类,主要保存哈夫曼树的根节点指针,但其丰富的功能函数将实现哈夫曼编码译码的工作及其他功能;
函数介绍:
1. void init(signode * sig){……} 初始化数组SN[];
2. void compress(){……}输出压缩对比情况的信息;
3. void exchange(){……}用两层for循环实现hufNode[i]节点的成员哈夫曼编码数组code[]前后元素的对换,因为在之前的编码过程中由于是从叶节点追溯至根节点,存入code数组的哈夫曼编码与哈夫曼编码的概念反向,故而要调整;
4. signode * getroot(){……}返回哈夫曼树的根节点指针;
5. signode * HFM::creat(){……}创建哈夫曼树,首先用三个for循环查看forest数组,找到权值最小的两个字符,以int型的min1,min2记录其下标,定义signode * 类型指针pp指向新生成signode节点,用指针操作使pp指向的节点的权值为min1,min2权值之和,pp做孩子指向forest[min1],右孩子指向forest[min2],min1,min2的父指针指向pp,然后将pp存入min1的位置,min2之后的每一个节点依次往前移一个位置,实现从forest数组中清除min1,min2并加入pp的操作;
6. void HFM::hufcode(){……}哈夫曼编码,用for循环控制查看hufNode 数组,其初始化已在creat()的开始完成,对每一个字符实现编码,用while循环从叶节点开始,如果该节点是其父节点的左孩子就将code[hufNode[i].size++]赋值0,否则赋为1,直至当前节点的父节点为空,while循环结束;
7. void HFM::savewithhufcode(FILE * inf,FILE * outf){……}将读入的文章以哈夫曼编码的形式存储,其中inf为读入文件的指针,outf为写入文件的指针,首先调用rewind(inf)函数将光标放置在文章开头,防止文件未关闭导致的错误,每读一个字符就用for循环在hufNode 数组中查找,因为hufNode 数组就是保存出现的字符的,故一定可以找到,然后再用fputc函数将code[]数组的内容写入文件,直至读入文件结束;
8. void HFM::inorder(signode * sig){……}迭代法遍历树,遍历到叶节点时执行hufNode[count++].sig=sig语句实现hufNode 数组指向文章中出现的字符;
9. int HFM::maxc(){……} 计数变量,记录哈夫曼编码最大位数;
10. void HFM::hufdecode(FILE* ipf,FILE* opf){……}解码,从哈夫曼编码到字符,输出到屏幕和指定的文件中;
11. void input(FILE * f){……}初始读入文章,保存出现的字符记录修改其权重;
数据结构选择与算法设计
数据结构选择:
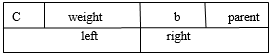
signode:
struct signode{ //signode节点,哈夫曼树节点//
char c; //字符//
int weight; //权重//
bool b; //文章中是否出现//
signode * parent;
signode * left;
signode * right;
signode(){ //初始化//
c=NULL;
b=false;
weight=0;
parent=left=right=NULL;
}
};
hufnode:
struct hufnode{ //哈夫曼编码对照表节点//
signode * sig;
int code[100]; //保存哈夫曼编码//
int size;
bool b;
hufnode(){sig=NULL;size=0;b=true;}
};
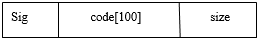
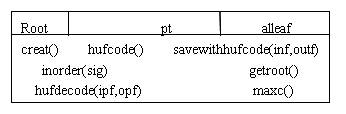
HFM:
class HFM{ //哈夫曼类//
private:
signode * root; //哈夫曼树根//
signode * pt; //编码时做哨兵指针//
int alleaf;
public:
HFM(int all){root=pt=NULL;alleaf=all;} //all是森林中树的个数//
~HFM(){}
signode * getroot(){return root;}
signode * creat(); //创建哈夫曼树//
void hufcode(); //编码//
void savewithhufcode(FILE * inf,FILE * outf); //用哈弗曼编码存储文件//
void hufdecode(FILE* ipf,FILE* opf); //解码//
void inorder(signode * sig);
int maxc(); //求取哈弗曼编码最大长度//
};
算法设计:
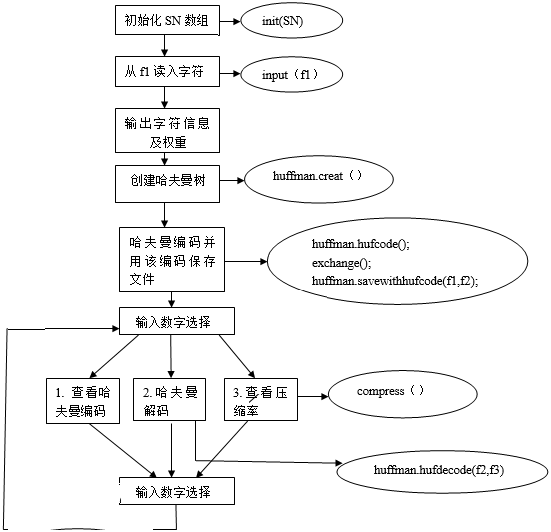
测试结果
Doc窗口:
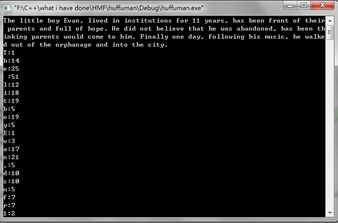
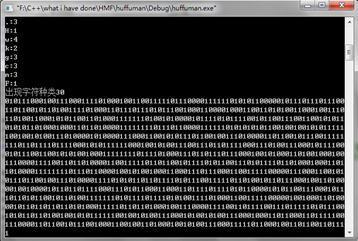
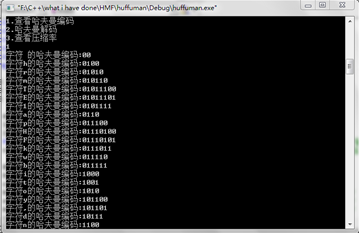
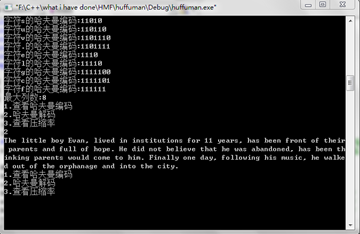
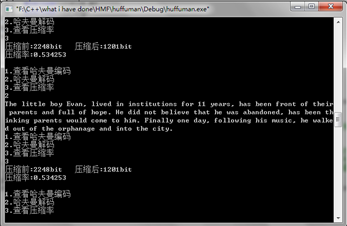
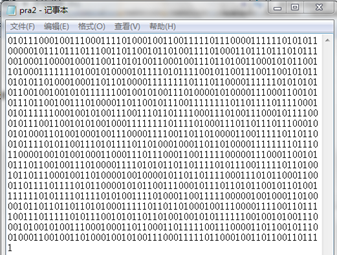
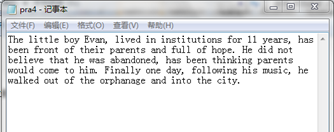
文件读写(部分):

总结
程序分析:
本次哈夫曼编码译码器的课程实验做得还算成功,不仅仅在于程序能够正常运行,实现应有的功能,关键在于过程,在于小组成员的分工合作和一起纠错排错的过程,在完成程序的过程中才能真正理解面向对象和模块化设计的思想,我们不仅仅是说要每人分几个函数,关键在于这些函数代表的是一个个功能模块,任何一个模块出现问题或者模块之间的衔接出现问题都将导致程序运行的失败。
哈夫曼编码译码器课程实验我主要负责完成编码译码器数据结构和功能模块框架的设计,结构体和类的定义,以及creat函数,hufcode函数,savewithhufcode函数的实现。在初始设计的时候,我体会到书写流程图的重要性,只有又一个清晰的设计思路才能事半功倍,分工明确,避免无效劳动或者在错误的编程方向上走弯路,也让大家明白自己在程序设计中的位置和职责。
初始的创建是哈夫曼编码译码系统成功的关键,我在创建的过程当中多次使用树的先根,配合中根遍历操作,输出接点字符或者权重信息,作为检验,对验证和纠错起到了非常大的作用。在适当的地方调用它们,运行时可以看到验证编写程序的正确性;
通过本次实验,提高了自已调试程序的能力。充分体会到了在程序执行时的提示性输出的重要性。编写大一点的程序,应先写出算法,再写程序,一段一段调试;对于没有实现的操作用空操作代替,这样容易找出错误所在。最忌讳将所有代码写完后再调试,这样若程序有错误,太难找 。
需要特别强调的是:
1. 感觉文件操作自己并不是很熟练,尽管在向显示器输出的时候并没有什么错误但是读写文件的时候就没那么顺利了,比如说当编写savewithhufcode函数时读文件,却总不执行,后来通过断点测试发现每次fgetc()返回值总为-1,于是我考虑是否是文件没有打开或者文件结束的缘故,后来想通了是之前打开的文件光标读操作结束后仍在结尾故每次总返回-1,故调用rewind函数将光标位置移动到文章开始。
2. 用哈夫曼编码存储文件的时候还应注意数字0,1与字符0,1的不同,不应直接在fputc()函数中直接写入0,1那么将会是写入的文章中什么都没有,因为0在ASCII码中代表NULL。
3.该程序函数清晰功能明确,程序具有通用性,对于不同的输入文章都可进行处理,由于采用哈夫曼编码对照表,使得查看哈夫曼编码是效率较高无需每次遍历哈夫曼树。
程序清单
.cpp
#include
#include
#include
#include
#include"Hh1.h"
using namespace std;
FILE * f1=fopen("d:\\pra1.txt","r");
FILE * f2=fopen("d:\\pra2.txt","w");
FILE * f3=fopen("d:\\pra4.huf","w");
int main(){
init(SN); //初始化字符数据库//
input(f1); //读入初始文件的字符//
for(int i=0;forest[i]!=NULL;i++)
cout<c<<":"<weight<
HFM huffman(count); //创建哈夫曼树实例// huffman.creat(); //创建哈夫曼树// count=0;
huffman.hufcode(); //哈夫曼编码,此时为逆向//
exchange(); //调整首尾对调哈夫曼编码// huffman.savewithhufcode(f1,f2); //用哈夫曼编码存储原文件//
cout<
cout<<"1.查看哈夫曼编码"<
cout<<"2.哈夫曼解码"<
cout<<"3.查看压缩率"<
int choice;
cin>>choice;
while(choice>=1&&choice<=3){
switch(choice){
case 1:{
for(i=0;hufNode[i].sig!=NULL;i++){
cout<<"字符"<c<<"的哈夫曼编码:"; //输出哈夫曼编码//
for(int j=0;j
cout<
}
cout<<"最大列数:"<
break;
}
case 2:{
fclose(f2);
f2=fopen("d:\\pra2.txt","r");
huffman.hufdecode(f2,f3); //哈夫曼解码//
cout<
break;
}
case 3:{
compress(); //查看压缩情况//
cout<
}
}
cout<<"1.查看哈夫曼编码"<
cout<<"2.哈夫曼解码"<
cout<<"3.查看压缩率"<
cin>>choice;
}
cout<<"*谢谢使用*"<
return 0;
}
.h
#include
using namespace std;
struct signode{ //signode节点,哈夫曼树节点//
char c; //字符//
int weight; //权重//
bool b; //文章中是否出现//
signode * parent;
signode * left;
signode * right;
signode(){ //初始化//
c=NULL;
b=false;
weight=0;
parent=left=right=NULL;
}
};
signode SN[256];
signode * forest[256]; //森林数组保存出现的字符//
int count=0; //出现字符计数//
float memo1=0,memo2=0; //全局变量记录读入字符数和编码的0 1数//
void init(signode * sig){ //SN[]数组初始化,输入常见字符//
sig[0].c='a';sig[1].c='b';sig[2].c='c'; sig[3].c='d';sig[4].c='e';
sig[5].c='f';sig[6].c='g';sig[7].c='h';sig[8].c='i';sig[9].c='j';
sig[10].c='k';sig[11].c='l';sig[12].c='m';sig[13].c='n';sig[14].c='o';
sig[15].c='p';sig[16].c='q';sig[17].c='r';sig[18].c='s';sig[19].c='t';
sig[20].c='u';sig[21].c='v';sig[22].c='w';sig[23].c='x';sig[24].c='y';
sig[25].c='z';
sig[26].c='A';sig[27].c='B';sig[28].c='C';sig[29].c='D';sig[30].c='E';
sig[31].c='F';sig[32].c='G';sig[33].c='H';sig[34].c='I';sig[35].c='J';
sig[36].c='K';sig[37].c='L';sig[38].c='M';sig[39].c='N';sig[40].c='O';
sig[41].c='P';sig[42].c='Q';sig[43].c='R';sig[44].c='S';sig[45].c='T';
sig[46].c='U';sig[47].c='V';sig[48].c='W';sig[49].c='X';sig[50].c='Y';
sig[51].c='Z';
sig[52].c='0';sig[53].c='1';sig[54].c='2';sig[55].c='3';sig[56].c='4';
sig[57].c='5';sig[58].c='6';sig[59].c='7';sig[60].c='8';sig[61].c='9';
sig[62].c='+';sig[63].c='-';sig[64].c='*';sig[65].c='/';sig[66].c=',';
sig[67].c='.';sig[68].c='\''; sig[69].c='"';sig[70].c=':';sig[71].c=';';
sig[72].c='<';sig[73].c='>';sig[74].c='=';sig[75].c='?';sig[76].c=' ';
sig[77].c='(';sig[78].c=')';sig[79].c='[';sig[80].c=']';sig[81].c='{';
sig[82].c='}';sig[83].c='!';sig[84].c='@';sig[85].c='#';sig[86].c='$';
sig[87].c='%';sig[88].c='^';sig[89].c='&';sig[90].c='\\';sig[91].c=10;
}
void compress(){ //压缩情况对比//
cout<<"压缩前:"<
cout<<"压缩率:"<
}
struct hufnode{ //哈夫曼编码对照表节点//
signode * sig;
int code[100]; //保存哈夫曼编码//
int size;
bool b;
hufnode(){sig=NULL;size=0;b=true;}
};
hufnode hufNode[256];
void exchange(){ //调换首尾交换哈夫曼编码//
int temp;
for(int i=0;hufNode[i].sig!=NULL;i++){
for(int s=0,b=hufNode[i].size-1;s<=b;s++,b--){
temp=hufNode[i].code[s];
hufNode[i].code[s]=hufNode[i].code[b];
hufNode[i].code[b]=temp
}
}
}
class HFM{ //哈夫曼类//
private:
signode * root; //哈夫曼树根//
signode * pt; //编码时做哨兵指针//
int alleaf;
public:
HFM(int all){root=pt=NULL;alleaf=all;}//all是森林中树的个数//
~HFM(){}
signode * getroot(){return root;}
signode * creat(); //创建哈夫曼树//
void hufcode(); //编码//
void savewithhufcode(FILE * inf,FILE * outf); //用哈弗曼编码存储文件//
void hufdecode(FILE* ipf,FILE* opf); //解码//
void inorder(signode * sig);
int maxc(); //求取哈夫码曼最大长度//
};
signode * HFM::creat(){
signode * pp=NULL;
for(int i=0;ib=false; //为hufcode函数作准备,与此函数无关// while(count>1){
int min=10000;
int min1,min2;
for(int i=0;forest[i]!=NULL;i++){ //以下三个for循环选出当前森林中的最小两个节点// if(forest[i]->weightweight;min1=i;} //
} //
min=10000; //
for(i=0;forest[i]!=NULL&&i!=min1;i++){ //
if(forest[i]->weightweight;min2=i;} //
} for(i=min1+1;forest[i]!=NULL;i++){ //
if(forest[i]->weightweight;min2=i;} //
} //至此找到min1 min2
pp=new signode(); //新生成节点,权值为两最小节点权值之和//
pp->left=forest[min1];
pp->right=forest[min2];
forest[min2]->b=true; //为hufcode函数作准备,与此函数无关//
pp->weight=forest[min1]->weight+forest[min2]->weight;
forest[min1]->parent=pp;
forest[min2]->parent=pp;
forest[min1]=pp; //新生成节点加入森林for(i=min2;forest[i]!=NULL;i++)forest[i]=forest[i+1]; //min2后的节点依次前移//
count--;
}
root=pp;
return pp;
}
void HFM::hufcode(){ //哈夫曼编码,保存在hufNode节点的数组当中//
inorder(root);
for(int i=0;hufNode[i].sig!=NULL;i++){
signode * gud=hufNode[i].sig;
while(gud->parent!=NULL){
if(gud->parent->left==gud)hufNode[i].code[hufNode[i].size++]=0;
else if(gud->parent->right==gud)hufNode[i].code[hufNode[i].size++]=1;
gud=gud->parent;
}
}
}
void HFM::savewithhufcode(FILE * inf,FILE * outf){ //用哈弗曼编码存储文件//
rewind(inf); //回到文件起始防止文件未关闭导致的错误//
char ch=fgetc(inf);
while(!feof(inf)){
for(int i=0;hufNode[i].sig->c!=ch;i++);
if(hufNode[i].sig->c==ch) {
for(int k=0;k
cout<
if(hufNode[i].code[k]==0){fputc(48,outf);memo2++;} //48,49分别是字符0,1的ASCII码//
else if(hufNode[i].code[k]==1){fputc(49,outf);memo2++;}
}
}
ch=fgetc(inf);
}
}
void HFM::inorder(signode * sig){
if(sig->left==NULL&&sig->right==NULL){
hufNode[count++].sig=sig;
return ;
}
else {
inorder(sig->left);
inorder(sig->right);
}
}
int HFM::maxc(){
int ma=0; //计数变量//
for(int i=0;i
if(hufNode[i].size>ma)ma=hufNode[i].size;
}
return ma;
}
void HFM::hufdecode(FILE* ipf,FILE* opf){ //解码,由哈夫曼码到字符//
signode* pt=root;
char ch=fgetc(ipf);
while(!feof(ipf)){ //判断有无到文件尾/
if(ch=='0'){
if(pt->left==NULL){
cout<c;
fputc(pt->c,opf);
pt=root;
}
pt=pt->left;
}
else if(ch=='1'){ //注意字符0,1与数字0,1是不同的//
if(pt->right==NULL){
cout<c;
fputc(pt->c,opf);
pt=root;
}
pt=pt->right;
}
ch=fgetc(ipf);
}
cout<c;
fputc(pt->c,opf);
fclose(ipf);
fclose(opf);
}
void input(FILE * f){
char ch=fgetc(f);
while(!feof(f)){ //feof(f1)判断文件是否结束,结束返回值为真//
putchar(ch); //向屏幕上输出一个字符//
memo1++
for(int i=0;SN[i].c!=NULL;i++){ //查看文件内容修改字符权重//
if(SN[i].c==ch){
if(SN[i].b==false){ //如果第一次出现就加入森林,否则什么也不做//
SN[i].b=true;
forest[count++]=&SN[i];
}
SN[i].weight++; //增加权重//
}
}
ch=fgetc(f);
}
cout<
}
-
译码器实验报告
课程编号深圳大学实验报告课程名称数字电路实验名称译码器学院信息工程学院指导教师刘静报告人李金梁组号03学号20xx130025实验…
-
数字电路译码器实验报告
一实验目的与要求1了解和正确使用MSI组合逻辑部件2掌握一般组合逻辑电路的特点及分析设计方法3学会对所设计的电路进行静态功能测试的…
-
数字电子线路实验报告_译码器及其应用
数电实验报告实验三译码器及其应用一实验目的1掌握译码器的测试方法2了解中规模集成译码器的功能管脚分布掌握其逻辑功能3掌握用译码器构…
-
138译码器实验报告
138译码器实验报告一实验目的与要求1掌握74HC138译码器的工作原理熟悉74HC138译码器的具体运用连接方法了解74HC13…
-
译码器实验报告
实验2译码器及其应用一实验目的1掌握中规模集成译码器的逻辑功能和使用方法2熟悉数码管的使用二实验原理译码器是一个多输入多输出的组合…
-
数字电路实验二--译码器实验报告深圳大学--郭治民
深圳大学实验报告实验课程名称数字电路与逻辑设计实验项目名称学院计算机与软件学院专业计算机科学与技术报告人同组人指导教师实验时间实验…
-
译码器实验报告
课程编号深圳大学实验报告课程名称数字电路实验名称译码器学院信息工程学院指导教师刘静报告人李金梁组号03学号20xx130025实验…
-
译码器实验报告
数字电路逻辑与设计实验报告姓名刘凯班级0401206学号20xx211791实验名称译码器及其应用实验目的123掌握数码管的使用方…
-
译码器实验报告
实验2译码器及其应用一实验目的1掌握中规模集成译码器的逻辑功能和使用方法2熟悉数码管的使用二实验原理译码器是一个多输入多输出的组合…
-
译码器实验报告
数字逻辑实验报告院系数学与计算机学院专业计算机类4班姓名田恒学号1305110089指导教师刘昌华实验题目译码器的EDA设计实验目…
-
数字电路译码器实验报告
一实验目的与要求1了解和正确使用MSI组合逻辑部件2掌握一般组合逻辑电路的特点及分析设计方法3学会对所设计的电路进行静态功能测试的…