�������ʵ�鱨��
������������ʵ�鱨��
һ��ʵ������
�����������LL(1)������������������붨��õ��ķ���д�ļ�(���õ��ķ�������LL(1)����)���������������ķ���ÿ�����ս���Ƿ����Ƴ��գ��ٷֱ������ս���ŵ�FIRST���ϣ�ÿ�����ս���ŵ�FOLLOW���ϣ��Լ�ÿ�������SELECT���ϣ����ж�����һ�����ս���ŵ��������������SELECT���Ľ����Dz��Ƕ�Ϊ�գ�����ǣ��������ķ�����LL(1)�ķ������Խ��з�����
�����ķ���
G[E]:
E->E+T|T
T->T*F|F
F->i|(E)
��������i+i*i�Ƿ�����ķ���
��������˼��
1���������ʵ��
������DZ�����̵ĺ��IJ��֣�������Ҫ�����ǰ��ճ����������ɴʷ����������Դ������Ŵ���ʶ���������ɷ֣�ͬʱ���дʷ���飬Ϊ��������ʹ���������������������Զ����µ�LL(1)����������
��������������ͼ��ͼ5-4��ʾ��
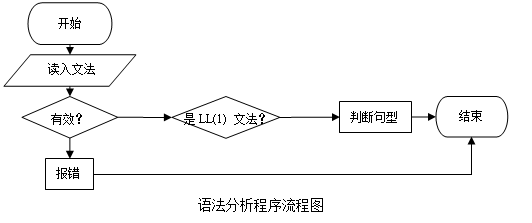
�ó���ɷ�Ϊ���¼�����
��1�������ķ�
��2�������
��3���������ж��Ƿ�ΪLL(1)�ķ�
��4�����ǣ������������
��5���ɾ����б��㷨�ж�������Ŵ���Ϊ���ķ��ľ��͡�
��������˼��
�÷���������15������ɣ�
��1�����ȶ��������Ҫ�õ��ij����ͱ�����
��2���ж�һ���ַ��Ƿ���ָ���ַ����У�
��3������һ���ķ���
��4�����������Ż���Ŵ�������һ���Ŵ���
��5����������ֱ���Ƴ�&�ķ��ţ�
��6����ijһ�����ܷ��Ƴ��� & ����
��7���ж϶�����ķ��Ƿ���ȷ��
��8�������ŵ�FIRST��
��9���������ʽ�Ҳ���FIRST��
��10���������ʽ��FOLLOW��
��11���ж϶����ķ��Ƿ�Ϊһ��LL(1)�ķ���
��12�����������M��
��13�������б��㷨��
��14��һ���û����ú�����
��15����������
���������м����ֳ���ε��㷨˼�룺
1�������Ƴ��յķ��ս����
��ʵ������ֱ���Ƴ��յ�empty�����㷨�������£�
void emp(char c){ ����cΪ�շ���
char temp[10];������ʱ����
int i;
for(i=0;i<=count-1;i++)���ķ��ĵ�һ������ʽ��ʼ����
{
if ����ʽ�Ҳ���һ�������ǿշ��Ų����Ҳ�����Ϊ1,
then����������ʽ���ű�������ʱ����temp��
����ʱ�����е�Ԫ�غϲ�����¼���Ƴ�&���ŵ�����empty�С�
}
����ijһ�����ܷ��Ƴ�'&'
int _emp(char c)
{ //�����Ƴ�&������1��������0
int i,j,k,result=1,mark=0;
char temp[20];
temp[0]=c;
temp[1]='\0';
��ŵ�һ����ʱ����empt��,��ʶ���ַ��Ѳ������Ƿ���Ƴ�����
���c�ڿ�ֱ���Ƴ����ֵ�empty[]��,����1
for(i=0;;i++)
{
if(i==count)
return(0);
��һ����Ϊc�IJ���ʽ
j=strlen(right[i]); //jΪc���ڲ���ʽ�Ҳ��ij���
if �Ҳ�����Ϊ1���Ҳ���һ���ַ���empty[]��. then����1(A->B,B���Ƴ���)
if �Ҳ�����Ϊ1����һ���ַ�Ϊ�ս��,then ����0(A->a,aΪ�ս��)
else
{
for(k=0;k<=j-1;k++)
{
������ʱ����empt[].�����mark-=1(A->AB)
if �ҵ����ַ��뵱ǰ�ַ���ͬ(A->AB)
��������ѭ��
else(mark����0)
�����Ҳ������Ƿ���Ƴ�����,�ѷ���ֵ����result
�ѵ�ǰ���ż��뵽��ʱ����empt[]��.
}
if ��ǰ�ַ������Ƴ������һ�û������ȫ���IJ���ʽ
then ��������ѭ������������һ������ʽ
else if //��ǰ�ַ����Ƴ�����,����1
}
}
}
2������ÿ�����ŵ�first����
ʵ���������ŵ�FIRST�����㷨�������£�
void first2 (int i) {
����iΪ������������������е����
c����ָʾ��i��ָ��ķ���
�ڱ����ս��Ԫ�ص�termin[]�������c
if cΪ�ս��(c��VT )��then
FIRST(c)={c}
�ڱ����ս��Ԫ�ص�non_ter[]�������c
if c�Ƿ��ս��(c��VN )
�����в���ʽ�в���c���ڵIJ���ʽ
if ����ʽ�Ҳ���һ���ַ�Ϊ�ս�����(��c��a (a��VT)��c��&) then
��a��&�ӽ�FIRST(c)
if ����ʽ�Ҳ���һ���ַ�Ϊ���ս�� then
if ����ʽ�Ҳ��ĵ�һ�����ŵ��ڵ�ǰ�ַ� then
������һ������ʽ���в���
��ǰ���ս���������ַ����е�λ��
if ��ǰ���ս����û����FIRST�� then
��������FIRST������ʶ�˷���������FIRST��
��ý�����뵽c��FIRST��.
if ��ǰ����ʽ�Ҳ����ſ��Ƴ������ҵ�ǰ�ַ������Ҳ������һ���ַ� then
��ȡ�Ҳ�������һ���ַ��������ַ����е�λ��
if ���ַ���FIRST����δ���� then
����FIRST��,���������״̬Ϊ1
����õ�FIRST�����뵽c��FIRST��.
if��ǰ�Ҳ����Ŵ����Ƴ��������Ҳ����Ŵ������һ���ַ�(������ʽΪc��Y1Y2��Yk,����һ��1<=i<=k������&��FIRST(Yi)����&�ʷ��żӽ�FIRST(c) ) then
�ѿ��ּ��뵽��ǰ�ַ�c��FIRST��.
else
�����Ƴ����������ѭ��
��ʶ��ǰ�ַ�c�Ѳ�����FIRST��. }
3. ����FOLLOW��
FOLLOW���Ĺ���������·�������
�����ķ��еķ���X ÎVN ����FOLLOW(A)���Ͽɷ���Ӧ�����й�����㣬ֱ��FOLLOW(A)���ϲ�������Ϊֹ��
(1)�����ķ���ʼ����S����ΪS��S����#ÎFOLLOW(S)��
(2)��A��a Bb������BÎVN��aÎ(VT UVN)*��bÎ(VT UVN)+����
FIRST(b)-{e}ÎFOLLOW(B)��
(3)��A��a B��A��a Bb (b 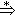 e)����
e)����
FOLLOW(A) ÎFOLLOW(B)��
FOLLOW�����㷨�������£�
void FOLLOW(int i)
XΪ����ķ��ս��
�ѵ�ǰ�ַ��ŵ�һ��ʱ����foll[]��,��ʶ��������FOLLOW��.����ѭ���ݹ�
if XΪ��ʼ���� then #��FOLLOW(X)
��ȫ���IJ���ʽ��һ���Ҳ����е�ǰ�ַ�X�IJ���ʽ
ע��������FOLLOW(B)����A����X��A��aXb(b��)�IJ���ʽ
if X�ڲ���ʽ�Ҳ������(�������ʽA��aX) then
���ҷ��ս��A�Ƿ��Ѿ������FOLLOW��.����ѭ���ݹ�
if ���ս��A�������FOLLOW�� then
FOLLOW(A)��FOLLOW(X)
��������һ������ʽ�Ƿ���X
else
��A֮FOLLOW��������ʶΪA������FOLLOW��
else if X���ڲ���ʽ�Ҳ������(����A��aBb) then
if�Ҳ�X����ķ��Ŵ�b���Ƴ�����e then
����b�Ƿ��Ѿ������FOLLOW��.����ѭ���ݹ�
if �����b��FOLLOW�� then
FOLLOW(A)��FOLLOW(B)
��������ѭ��
else if b�����Ƴ����� then
��FIRST(b)
��FIRST(b)�����зǿ�Ԫ�ؼ��뵽FOLLOW(B)��
��ʶ��ǰҪ��ķ��ս��X��FOLLOW�������
4.����SELECT��
SELECT���Ĺ����㷨���£�
�����еĹ������ʽA��x��
(1)��x�����Ƴ�����e����SELECT(A��x) = FIRST(x)��
(2)��x���Ƴ�����e����SELECT(A��x)=FIRST(x)�C{e} U FOLLOW(A)��
�㷨�������£�
for(i=0;i<=����ʽ����-1;i++)
�Ȱѵ�ǰ����ʽ�Ҳ���FIRST��(һ�зǿ�Ԫ��,��������)���뵽��ǰ����ʽ��SELECT(i);
if ����ʽ�Ҳ����Ŵ����Ƴ�����e then
��iָ��ĵ�ǰ����ʽ�ķ��ս���ŵ�FOLLOW�����뵽SELECT(i)��
5.�ж��Ƿ�LL(1)�ķ�
Ҫ�ж��Ƿ�ΪLL(1)�ķ�����Ҫ������ķ�G������Ҫ��
������ͬ�Ĺ����SELECT���������ཻ������
SELECT(A��a)�� SELECT(A��b)= Æ
���������ķ����������ϵ�Ҫ������ķ�������LL(1)����������
�㷨�������£�
�ѵ�һ������ʽ��SELECT(0)���ŵ�һ����ʱ����temp[]��
for(i=1;i<=����ʽ����-1;i++)
��temp�ij���length
if iָ��ĵ�ǰ����ʽ��������һ������ʽ���� then
��SELECT(i)���뵽temp������
If temp�ij�����length����SELECT (i)�ij���
����0
else
��temp���
��SELECT (i)��ŵ�temp��
�������1��
�ġ��㷨
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
/*******************************************/
int count=0; //����ʽ�ĸ���
int number; //�����ս���ͷ��ս��������
char start; //��ʼ����
char termin[50]; //�ս����
char non_ter[50]; //���ս����
char v[50]; //�����
char left[50]; //��
char right[50][50]; //�Ҳ�
char first[50][50],follow[50][50]; //������ʽ�Ҳ���FIRST����FOLLOW����
char first1[50][50]; //���е������ŵ�FIRST����
char select[50][50]; //��������ʽ��SELECT����
char firstflag[50],followflag[50]; //��¼�����ŵ�FIRST��FOLLOW�Ƿ������
char empty[20]; //��¼���Ƴ�&�ķ���
char nonempty[20]; //��¼�����Ƴ�&�ķ���
char empt[20]; //��_emp()ʱʹ��
char TEMP[50]; //��FOLLOWʱ���ijһ���Ŵ���FIRST����
int validity=1; //��ʾ�����ķ��Ƿ���Ч
int ll=1; //��ʾ�����ķ��Ƿ�ΪLL(1)�ķ�
int M[20][20]; //������
char choose; //�û�����ʱʹ��
char foll[20]; //��FOLLOW����ʱʹ��
/*******************************************
�ж�һ���ַ�c�Ƿ���ָ���ַ���p��
********************************************/
int in(char c,char *p)
{
int i;
if(strlen(p)==0)
return(0);
for(i=0;;i++)
{
if(p[i]==c)
return(1); //���ڣ�����1
if(i==(int)strlen(p))
return(0); //�����ڣ�����0
}
}
/*******************************************
���������Ż���Ŵ�������һ���Ŵ�
********************************************/
void merge(char *d,char *s,int type)
{ //��Ŀ����Ŵ���s��Դ����type��1��Դ���е�'&'һ������Ŀ����
//type��2��Դ���е�'&'������Ŀ��
int i,j;
for(i=0;i<=(int)strlen(s)-1;i++)
{
if(type==2&&s[i]=='&');
else
{
for(j=0;;j++)
{
if(j<(int)strlen(d)&&s[i]==d[j])
break; //���Ѵ��ڣ����˳�����������һ��Դ���ַ�
if(j==(int)strlen(d)) //�������ڣ�����
{
d[j]=s[i];
d[j+1]='\0';
break;
}
}
}
}
}
/*******************************************
����һ���ķ�
********************************************/
char grammer(char *t,char *n,char *left,char right[50][50])
{
char vn[50],vt[50];
char s;
char p[50][50];
int i,j;
printf("�������ķ��ķ��ս���Ŵ���");
scanf("%s",vn);
getchar();
i=strlen(vn);
memcpy(n,vn,i);
n[i]='\0';
printf("�������ķ����ս���Ŵ���");
scanf("%s",vt);
getchar();
i=strlen(vt);
memcpy(t,vt,i);
t[i]='\0';
printf("�������ķ��Ŀ�ʼ���ţ�");
scanf("%c",&s);
getchar();
printf("�������ķ�����ʽ��������");
scanf("%d",&i);
getchar();
count=i;
for(j=1;j<=i;j++)
{
printf("�������ķ��ĵ�%d������%d��������ʽ��",j,i);
scanf("%s",p[j-1]);
getchar();
}
for(j=0;j<=i-1;j++)
{
if(p[j][1]!='-'||p[j][2]!='>') //����������
{
printf("\n�������!");
validity=0;
return('\0');
}
}
return(s);
}
/*******************************************
�ж϶�����ķ��Ƿ���ȷ
********************************************/
int judge()
{
int i,j;
for(i=0;i<=count-1;i++)
{
if(in(left[i],non_ter)==0)
{ //�����ڷ��ս���У�����
printf("\n�ķ�����!");
validity=0;
return(0);
}
for(j=0;j<=(int)strlen(right[i])-1;j++)
{
if(in(right[i][j],non_ter)==0&&in(right[i][j],termin)==0&&right[i][j]!='&')
{ //���Ҳ�ijһ���Ų��ڷ��ս�����ս�����Ҳ�Ϊ'&'������
printf("\n�ķ��Ҳ�����!");
validity=0;
return(0);
}
}
}
return(1);
}
/*******************************************
��������ֱ���Ƴ�&�ķ���
********************************************/
void emp(char c)
{
char temp[10];
int i;
for(i=0;i<=count-1;i++)
{
if(right[i][0]==c&&strlen(right[i])==1)
{
temp[0]=left[i];
temp[1]='\0';
merge(empty,temp,1);//��������ֱ���Ƴ�'&"�ķ���,������浽empty[]��
emp(left[i]);
}
}
}
/*******************************************
��ijһ�����ܷ��Ƴ�'&'
********************************************/
int _emp(char c)
{ //�����Ƴ�&������1��������0
int i,j,k,result=1,mark=0;
char temp[20];
temp[0]=c;
temp[1]='\0';
merge(empt,temp,1);//��ŵ�һ����ʱ����empt��,��ʶ���ַ��Ѳ������Ƿ���Ƴ�����
if(in(c,empty)==1)//���c�ڿ�ֱ���Ƴ����ֵ�empty[]��,����1
return(1);
for(i=0;;i++)
{
if(i==count)
return(0);
if(left[i]==c) //��һ����Ϊc�IJ���ʽ
{
j=strlen(right[i]); //jΪc���ڲ���ʽ�Ҳ��ij���
if(j==1&&in(right[i][0],empty)==1)//�Ҳ�����Ϊ1���Ҳ���һ���ַ���empty[]��.����1(A->B,B���Ƴ���)
return(1);
else if(j==1&&in(right[i][0],termin)==1)//�Ҳ�����Ϊ1����һ���ַ�Ϊ�ս��,����0(A->a,aΪ�ս��)
continue;
else
{
for(k=0;k<=j-1;k++)
{
if(in(right[i][k],empt)==1)//������ʱ����empt[].(A->AB)
mark=1;
}
if(mark==1) //�ҵ����ַ��뵱ǰ�ַ���ͬ(A->AB)
continue; //��������ѭ��
else //(mark����0)
{
for(k=0;k<=j-1;k++)
{
result*=_emp(right[i][k]);//�ݹ���ã������Ҳ������Ƿ���Ƴ�����,�ѷ���ֵ����result
temp[0]=right[i][k];
temp[1]='\0';
merge(empt,temp,1);//�ѵ�ǰ���ż��뵽��ʱ����empt[]�����Ѳ���
}
}
}
if(result==0&&i<count)//�����ǰ�ַ������Ƴ������һ�û������ȫ���IJ���ʽ,����������ѭ������������һ������ʽ
continue;
else if(result==1&&i<count)//��ǰ�ַ����Ƴ�����,����1
return(1);
}
}
}
/*******************************************
�����ŵ�FIRST
********************************************/
void first2(int i)
{ //iΪ������������������е����
char c,temp[20];
int j,k,m;
char ch='&';
c=v[i];
emp(ch);//��������ֱ���Ƴ����ֵķ���,������浽empty[]��
if(in(c,termin)==1) //��Ϊ�ս��--c��VT����FIRST(c)={c}
{
first1[i][0]=c;
first1[i][1]='\0';
}
else if(in(c,non_ter)==1) //��Ϊ���ս��
{
for(j=0;j<=count-1;j++) //jΪ���в���ʽ�е�����
{
if(left[j]==c) //��һ����Ϊc�IJ���ʽ
{
if(in(right[j][0],termin)==1||right[j][0]=='&')
{//������ʽ�Ҳ���һ���ַ�Ϊ�ս�����.---����ʽX��a (a��VT)��X��&,���a��&�ӽ�FIRST(X)
temp[0]=right[j][0];
temp[1]='\0';
merge(first1[i],temp,1);
}
//------X��Y1Y2��Yk�IJ���ʽ����Y1��VN�����FIRST(Y1)�е�һ�зǿշ��żӽ�FIRST(X)
else if(in(right[j][0],non_ter)==1)//����ʽ�Ҳ���һ���ַ�Ϊ���ս��
{
if(right[j][0]==c)//����ʽ�Ҳ��ĵ�һ�����ŵ��ڵ�ǰ�ַ�,��������һ������ʽ���в���
continue;
for(k=0;;k++)
{
if(v[k]==right[j][0])//���Ҳ���һ���ַ��������ַ����е�λ��k
break;
}
if(firstflag[k]=='0')
{
first2(k);//����FIRST��
firstflag[k]='1';//��ʶ��Ϊ����״̬
}
merge(first1[i],first1[k],2);//��ý�����뵽X��FIRST��.
for(k=0;k<(int)strlen(right[j]);k++)
{
empt[0]='\0';//��ŵ�һ����ʱ������,��ʶ���ַ��Ѳ������Ƿ���Ƴ�����
if(_emp(right[j][k])==1&&k<(int)strlen(right[j])-1)
{//��ǰ����ʽ�Ҳ����ſ��Ƴ�����,�ҵ�ǰ�ַ������Ҳ������һ���ַ�
for(m=0;;m++)
{
if(v[m]==right[j][k+1])//��ȡ�Ҳ�������һ���ַ��������ַ����е�λ��
break;
}
if(firstflag[m]=='0')//������ַ���FIRST����δ����,������FIRST��,���������״̬Ϊ1
{
first2(m);
firstflag[m]='1';
}
merge(first1[i],first1[m],2);//����ý�����뵽X��FIRST��.
}
//----����ʽΪX��Y1Y2��Yk,����һ��1<=i<=k������&��FIRST(Yi)����&�ʷ��żӽ�FIRST(X)
else if(_emp(right[j][k])==1&&k==(int)strlen(right[j])-1)
{//��ǰ�Ҳ����Ŵ����Ƴ��������Ҳ����Ŵ������һ���ַ�
temp[0]='&';
temp[1]='\0';
merge(first1[i],temp,1);//�ѿ��ּ��뵽��ǰ�ַ�X��FIRST��.
}
else
break;//�����Ƴ����������ѭ��
}
}
}
}
}
firstflag[i]='1';//��ʶ��ǰ�ַ�c�Ѳ�����FIRST��
}
/*******************************************
�������ʽ�Ҳ���FIRST
********************************************/
void FIRST(int i,char *p)
{ //ָ��pָ���Ҳ����Ŵ�
int length;//��ʶ�Ҳ����Ŵ��ij���
int j,k,m;
char temp[20];
length=strlen(p);
if(length==1) //����Ҳ�Ϊ��������
{
if(p[0]=='&')//�Ҳ����Ŵ��ַ�Ϊ"&"����
{
if(i>=0)//i��Ϊ-1ʱ�Dz���ʽ�����
{
first[i][0]='&'; //��"&"���뵽��ǰ���Ŵ���FIRST��
first[i][1]='\0';
}
else//iΪ-1ʱ,��ʾ��FOLLOWʱ�õ��IJ���ʽ�Ҳ���FIRST��,������TEMP[]��
{
TEMP[0]='&';
TEMP[1]='\0';
}
}
else//�Ҳ����Ŵ��ַ���Ϊ"&"����
{
for(j=0;;j++)
{
if(v[j]==p[0])//���Ҳ����ŵĵ�һ���ַ�p[0]�������ַ����е�λ��j
break;
}
if(i>=0)
{
memcpy(first[i],first1[j],strlen(first1[j]));//��j��ָ��ĵ������ŵ�FIRST�����������Ҳ����Ŵ���FIRST��
first[i][strlen(first1[j])]='\0';
}
else
{
memcpy(TEMP,first1[j],strlen(first1[j]));
TEMP[strlen(first1[j])]='\0';
}
}
}
else //����Ҳ�Ϊ���Ŵ�
{
for(j=0;;j++)
{
if(v[j]==p[0])//���Ҳ����ŵĵ�һ���ַ�p[0]�������ַ����е�λ��j
break;
}
if(i>=0)
merge(first[i],first1[j],2);
else
merge(TEMP,first1[j],2);
for(k=0;k<=length-1;k++)
{
empt[0]='\0';
if(_emp(p[k])==1&&k<length-1)
{ //��ǰ����ʽ�Ҳ����ſ��Ƴ�����,�ҵ�ǰ�ַ������Ҳ������һ���ַ�
for(m=0;;m++)
{
if(v[m]==right[i][k+1])
break;
}
if(i>=0)
merge(first[i],first1[m],2);
else
merge(TEMP,first1[m],2);
}
else if(_emp(p[k])==1&&k==length-1)
{//��ǰ�Ҳ����Ŵ����Ƴ��������Ҳ����Ŵ������һ���ַ�
temp[0]='&';
temp[1]='\0';
if(i>=0)
merge(first[i],temp,1);
else
merge(TEMP,temp,1);
}
else if(_emp(p[k])==0)
break;
}
}
}
/*******************************************
�������ʽ��FOLLOW
********************************************/
void FOLLOW(int i)
{ //����iΪ�÷����ڷ��ս���е�λ��
int j,k,m,n,result=1;
char c,temp[20];
c=non_ter[i]; //cΪ����ķ��ս��
temp[0]=c;
temp[1]='\0';
merge(foll,temp,1);//�ѵ�ǰ�ַ��ŵ�һ��ʱ����foll[]��,��ʶ��������FOLLOW��.����ѭ���ݹ�
if(c==start)
{ //��Ϊ��ʼ����-----��ʼ����S����#��FOLLOW(S)
temp[0]='#';
temp[1]='\0';
merge(follow[i],temp,1);
}
for(j=0;j<=count-1;j++)
{
if(in(c,right[j])==1) //��һ���Ҳ����е�ǰ�ַ�c�IJ���ʽ
{//������FOLLOW(B)����A����B��A����B��(��=>*&)�IJ���ʽ
for(k=0;;k++)
{
if(right[j][k]==c)
break; //kΪc�ڸò���ʽ�Ҳ������,��B�ڲ���ʽA����B�е�λ��
}
for(m=0;;m++)
{
if(v[m]==left[j])
break; //mΪ����ʽ���ս�������з����е����
}
//���c�ڲ���ʽ�Ҳ������,�������ʽA����B,��FOLLOW(A)��FOLLOW(B)
if(k==(int)strlen(right[j])-1)
{
if(in(v[m],foll)==1)//���Ҹ÷��ս���Ƿ��Ѿ������FOLLOW��.����ѭ���ݹ�
{//����FOLLOW(A)��FOLLOW(B)
merge(follow[i],follow[m],1);//��c���ڲ���ʽ�����ս����FOLLOW�����뵽FOLLOW(c)��
continue;//��������ѭ��,����j++ѭ��
}
if(followflag[m]=='0')
{//����÷��ս����FOLLOWδ���
FOLLOW(m);//��֮FOLLOW��
followflag[m]='1';//��ʶΪ1
}
merge(follow[i],follow[m],1);//FOLLOW(A)��FOLLOW(B)
}
else
{ //���c���ڲ���ʽ�Ҳ������,����A����B��
for(n=k+1;n<=(int)strlen(right[j])-1;n++)
{
empt[0]='\0';//��empt[]�ÿ�,��Ϊ����ַ��Ƿ���Ƴ�����_emp(c)ʱ�õ�
result*=_emp(right[j][n]);
}
if(result==1)
{ //����Ҳ�c����ķ��Ŵ����Ƴ���,A����B��(��=>*&)��FOLLOW(A)��FOLLOW(B)
if(in(v[m],foll)==1)
{ //���Ҹ÷��ս���Ƿ��Ѿ������FOLLOW��.����ѭ���ݹ�
merge(follow[i],follow[m],1);//FOLLOW(A)��FOLLOW(B)
continue;
}
if(followflag[m]=='0')
{
FOLLOW(m);
followflag[m]='1';
}
merge(follow[i],follow[m],1);
}
//��A����B�£�����B��VN������(VT U VN)*���¡�(VT U VN)+����FIRST(��)-{��}��FOLLOW(B)��
for(n=k+1;n<=(int)strlen(right[j])-1;n++)
{
temp[n-k-1]=right[j][n];
}
temp[strlen(right[j])-k-1]='\0';
FIRST(-1,temp);//��FIRST(��)
merge(follow[i],TEMP,2);//��FIRST(��)�����зǿ�Ԫ�ؼ��뵽FOLLOW(B)��
}
}
}
followflag[i]='1';//��ʶ��ǰҪ��ķ��ս����FOLLOW�������
}
/*******************************************
�ж϶����ķ��Ƿ�Ϊһ��LL(1)�ķ�
********************************************/
int LL1()
{
int i,j,length,result=1;
char temp[50];
for(j=0;j<=49;j++)
{ //��ʼ��
first[j][0]='\0';
follow[j][0]='\0';
first1[j][0]='\0';
select[j][0]='\0';
TEMP[j]='\0';
temp[j]='\0';
firstflag[j]='0';//������¼���ַ���FIRST���Ƿ������.1��ʾ����,0��ʾδ��
followflag[j]='0';//������¼���ַ���FOLLOW���Ƿ������.1��ʾ����,0��ʾδ��
}
for(j=0;j<=(int)strlen(v)-1;j++)
{
first2(j); //�����ŵ�FIRST����,���������first1[]��
}
printf("\n�����ս���Ƴ���first��:\n");
for(j=0;j<=(int)strlen(v)-1;j++)
{
printf("%c:%s ",v[j],first1[j]);
}
printf("\n�ܵ��յķ��ս������:%s",empty);
printf("\n_emp:");
for(j=0;j<=(int)strlen(v)-1;j++)
printf("%d ",_emp(v[j]));
for(i=0;i<=count-1;i++)
FIRST(i,right[i]); //��FIRST
for(j=0;j<=(int)strlen(non_ter)-1;j++)
{ //��FOLLOW
if(foll[j]==0)
{
foll[0]='\0';
FOLLOW(j);
}
}
printf("\nfirst��:");
for(i=0;i<=count-1;i++)
printf("%s ",first[i]);
printf("\nfollow����:");
for(i=0;i<=(int)strlen(non_ter)-1;i++)
printf("%s ",follow[i]);
for(i=0;i<=count-1;i++)
{ //��ÿһ����ʽ��SELECT����
memcpy(select[i],first[i],strlen(first[i]));//first[]��ŵ��Ǹ�����ʽ�Ҳ���FIRST��
select[i][strlen(first[i])]='\0';
for(j=0;j<=(int)strlen(right[i])-1;j++)
result*=_emp(right[i][j]);
if(strlen(right[i])==1&&right[i][0]=='&')//�������ʽA->&
result=1;
if(result==1)
{
for(j=0;;j++)
if(v[j]==left[i])//jΪ�����������ַ����е�λ��
break;
merge(select[i],follow[j],1);
}
}
printf("\nselect����˳����:");
for(i=0;i<=count-1;i++)
printf("%s ",select[i]);
memcpy(temp,select[0],strlen(select[0]));
temp[strlen(select[0])]='\0';
for(i=1;i<=count-1;i++)
{ /*�ж������ķ��Ƿ�ΪLL(1)�ķ�*/
length=strlen(temp);
if(left[i]==left[i-1])
{
merge(temp,select[i],1);
if(strlen(temp)<length+strlen(select[i]))//�Ƚ���������ʽ��SELECT����
return(0);
}
else
{
temp[0]='\0';
memcpy(temp,select[i],strlen(select[i]));
temp[strlen(select[i])]='\0';
}
}
return(1);
}
/*******************************************
���������M
********************************************/
void MM()
{
int i,j,k,m;
for(i=0;i<=19;i++)
{
for(j=0;j<=19;j++)//��ʼ��������,ȫ����Ϊ��(-1)
{
M[i][j]=-1;
}
}
i=strlen(termin);
termin[i]='#'; //��#�����ս������
termin[i+1]='\0';
for(i=0;i<=count-1;i++)//�鿴ÿ������ʽ��SELECT��
{
for(m=0;;m++)
{
if(non_ter[m]==left[i])
break; //mΪ����ʽ���ս�������
}
for(j=0;j<=(int)strlen(select[i])-1;j++)//��ÿ��SELECT���е�����Ԫ�ؽ��в���
{
if(in(select[i][j],termin)==1)
{
for(k=0;;k++)
{
if(termin[k]==select[i][j])
break; //kΪ����ʽ�Ҳ��ս�������
}
M[m][k]=i;
}
}
}
}
/*******************************************
�жϷ��Ŵ��Ƿ��Ǹ��ķ��ľ���
********************************************/
void syntax()
{
int i,j,k,m,n,p,q;
char ch;
char S[50],str[50];
printf("��������ķ��ľ��ͣ�");
scanf("%s",str);
getchar();
i=strlen(str);
str[i]='#';
str[i+1]='\0';
S[0]='#';
S[1]=start;
S[2]='\0';
j=0;
ch=str[j];
while(1)
{
if(in(S[strlen(S)-1],termin)==1)
{
if(S[strlen(S)-1]!=ch)
{
printf("�÷��Ŵ������ķ��ľ��ͣ�");
return;
}
else if(S[strlen(S)-1]=='#')
{
printf("�÷��Ŵ����ķ��ľ���.");
return;
}
else
{
S[strlen(S)-1]='\0';
j++;
ch=str[j];
}
}
else
{
for(i=0;;i++)
if(non_ter[i]==S[strlen(S)-1])
break;
for(k=0;;k++)
{
if(termin[k]==ch)
break;
if(k==(int)strlen(termin))
{
printf("�ʷ�����");
return;
}
}
if(M[i][k]==-1)
{
printf("�����");
return;
}
else
{
m=M[i][k];
if(right[m][0]=='@')
S[strlen(S)-1]='\0';
else
{
p=strlen(S)-1;
q=p;
for(n=strlen(right[m])-1;n>=0;n--)
S[p++]=right[m][n];
S[q+strlen(right[m])]='\0';
}
}
}
printf("S:%s str:",S);
for(p=j;p<=(int)strlen(str)-1;p++)
printf("%c",str[p]);
printf(" \n");
}
}
/*******************************************
һ���û����ú���
********************************************/
void menu()
{
syntax();
printf("\n�Ƿ������(y or n):");
scanf("%c",&choose);
getchar();
while(choose=='y')
{
menu();
}
}
/*******************************************
������
********************************************/
void main()
{
int i,j;
start=grammer(termin,non_ter,left,right); //����һ���ķ�
printf("count=%d",count);
printf("\n��ʼ����Ϊ:%c",start);
strcpy(v,non_ter);
strcat(v,termin);
printf("\n���з��ż�Ϊ:%s",v);
printf("\n���ս������:{%s",non_ter);
printf("}");
printf("\n�ս������:{%s",termin);
printf("}");
printf("\n�ķ������ұ߱���ʽ������:");
for(i=0;i<=count-1;i++)
{
printf("%s ",right[i]);
}
printf("\n�ķ�������߿�ʼ��������:");
for(i=0;i<=count-1;i++)
{
printf("%c ",left[i]);
}
if(validity==1)
validity=judge();
printf("\nvalidity=%d",validity);
if(validity==1)
{
ll=LL1();
printf("\nll=%d",ll);
if(ll==0)
printf("\n���ķ�����һ��LL1�ķ���");
else
{
printf("\n���ķ���һ��LL(1)�ķ���");
MM();
printf("\n");
for(i=0;i<=19;i++)
for(j=0;j<=19;j++)
if(M[i][j]>=0)
printf("M[%d][%d]=%d ",i,j,M[i][j]);
menu();
}
}
}

�����㷨���кܶ�������ս��û��ʵ�֣�����ʧ����
�塢ʵ���ĵ�
ͨ������ʵ�飬���ջ��˺ܶණ�������ȶԱ���ԭ�����ſ����˽�һ����������⣬ͬʱ��LL��1���ķ�������ԭ���������˽�һ���Ĺ��̣�Ҳ�������ұ�̵�������������ƽʱ��ѧ��֪ʶ������������ѧ�����á�
����ʵ��Ĺ����У������Լ��ڱ�д��������У����ǻ���Ը���ϸ�ڣ��Ӷ����¾�����һЩ��С�ĵͼ��������ʹ�����������У������˷�ʱ�䣬��Ӱ��������ط����ģ������ںܶಽ�账���ϣ���������ȷ��ʹ������ܷ���Ҫ�������ᵽ���Լ��ڱ�̷�������˵IJ�࣬�ڽ���ѧϰ�У��һ�ע������Լ����ⷽ���ȱ�㣬��ʹ�Լ��ı��ˮƽ���Ͻ�����
����ԭ����һ��רҵѧ�ƣ������ֽε�����˵��ֻ����������һЩ����ԭ���������һЩ������֪ʶ�����кܶ���������ĵط����������ʵ������У��������Լ���˼��������Ҳ�������Լ��Ķ��ֱ�����������ڽ�֪ʶ��ת�����˺ܴ�İ�����
-
�����ʵ�鱨��
����ԭ��ʵ�鱨��ʵ������ʵ������ָ����ʦרҵ�༶����ѧ��ʵ��ص�ʵ��ɼ���д����������ϻ�ʵ�齯������1002��20xx1��6A��
- �������ʵ�鱨��
- �������ʵ�鱨��
-
�ʷ�������_ʵ�鱨��
�ʷ�������ʵ�鱨��ʵ��Ŀ����Ʊ��Ƶ���һ���ʷ������ӳ���ʶ�ʼ���Դʷ�����ԭ��������ʵ��Ҫ��ó���Ҫʵ�ֵ���һ�������ʹ��̴��䡭
-
�ʷ��������������ʵ�鱨��(����ԭ����ʵ��)
ɽ����ѧ���뼼���γ���ư༶����һ��ѧ��20xx008000XX��������һ������ָ����ʦ����ʦ����һһ������һĿ��ltlt���뼼����
-
�����ʵ�鱨��
����ԭ��ʵ�鱨��ʵ������ʵ������ָ����ʦרҵ�༶����ѧ��ʵ��ص�ʵ��ɼ���д����������ϻ�ʵ�齯������1002��20xx1��6A��
- �������ʵ�鱨��
- �����ʵ�鱨��
-
�����ʵ�鱨��
�����ʵ�鱨��һʵ��Ŀ����Ϥ�����һ������ʽ�����������ʵ������1��Ʊ���ʽ����������㷨2��д���벢�ϻ���������ͨ��Ҫ���䡭
-
�������ʵ�鱨��
����ʦ����ѧʵ�鱨����������һ��������ϵ20xx�꼶����20xx1112������ս��ѧ��20xx416596ʵ�����������ʵ��һ��
-
�����ʵ�鱨��
����ԭ��ʵ�鱨����Ŀѧ�������༶ѧ��ָ����ʦ�ɼ������ʵ��ѧ�����ѧԺ20xx��5��28��һʵ��Ŀ������һ��������������ܹ�����