读书报告论文
传递函数模型研究
张柏发
摘要:本文对时间序列理论模型进行了研究。从ARMA模型的结构与建模方法出发,重点介绍了传递函数模型的定义、原理、识别、拟合、诊断。传递函数模型是时间序列分析中一种典型动态响应模型,其传递函数部分能体现一个输出序列与输入序列的关系,噪声部分又能反映了输出序列自身的时序关系。并进一步介绍了传递函数模型在土壤溶质运移模拟中的应用和传递函数模型的构建方法之一——概率神经网络模型。
本章主要介绍了理论模型和理论知识,包括时间序列平稳性检验,ARMA 模型识别、拟合、预测,再重点介绍了传递函数模型的原理、传递函数的性质、互相关函数、互相关函数与传递函数的关系,以及模型的建立过程等内容。
传递函数模型是时间序列分析中一种基于一个时间序列当前观测值不仅与本身过去观察值有关,还受到其它时间序列的影响,而提出的动态响应模型,在经济、工业生产、生物、医学等领域均有广泛的应用。传递函数模型是时间序列分析中一种典型动态响应模型,其传递函数部分能体现一个输出序列与输入序列的关系,噪声部分又能反映了输出序列自身的时序关系。向阳等(2006)通过分析降水和地下水埋深之间的关系,利用传递函数理论和回归分析方法建立降水估计地下水埋深统计模型,提高了拟合精度。Li Chunyan 和 Chen Jun (2009)分析了交通事故的宏观影响因素建立了传递函数模型,Xu Yajing 和 Li Xianglu(2009)应用传递函数模型进行经济预测,Kinley、Pratop(2010)也应用传递函数模型在生物方面做研究。
传递函数模型可以看成是带有输入序列的ARIMA模型,它是ARIMA模型与普通回归模型的结合。如果多个动态数据所成的时间序列都是平稳的,或经过适当差分后平稳,即可建立传递函数模型.传递函数模型的建模过程非常复杂,必须借助于计算机才能完成。当前最为流行的统计分析软件—SAS在进行多元时间序列分析中时,具有其他统计软件无可比拟的优势。
1时间序列理论模型介绍
1.1 时间序列基本概念
时间序列分析可以从数量上揭示某种系统或现象的发展变化规律,或者从动态的角度刻画某现象与其它现象的依存关系以及发展的变化规律,运用时间序列模型可以预测系统的未来情况。时间序列模型已经成为现代各个领域的重要研究工具,广泛应用于各个领域的分析与预测,包括经济、金融、工业、商业等方面。
1.1.1时间序列的平稳性
⑴平稳序列
如果时间序列{y t,t= 1,2, …}满足下面
①均值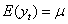 为常数, (t= 1,2, …);
为常数, (t= 1,2, …);
②方差 (t= 1,2, …);
(t= 1,2, …);
③协方差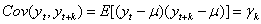 不依赖于t ,(t= 1,2, …);
不依赖于t ,(t= 1,2, …);
则称时间序列{y t,t= 1,2, …}为宽平稳时间序列,也叫广义平稳时间序列,简称平稳序列。
对于平稳的时间序列at,如果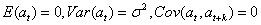 对于所有的t和k≠0成立,则称时间序列at为白噪声序列。
对于所有的t和k≠0成立,则称时间序列at为白噪声序列。
⑵非平稳序列
所谓一个时间序列是非平稳的,是指时间序列的统计规律会随着时间的平移而发生变化,也就是说生成变量时间序列数据的随机过程的统计特征随时间的变化而变化。只要弱平稳的三个条件不全满足,就称该时间序列是非平稳的。
通常我们所说的平稳性就是弱平稳性。因为平稳的时间序列有稳定的发展趋势(均值)、波动性(方差)和横向联系(协方差),因此可以用时间序列的样本均值和方差推断各时点随机变量的分布特征。对于平稳序列,任何震荡的影响都是暂时的。随着时间的推移,这些影响将会逐渐消失,时间序列将回复到长期的平均水平。因此,用平稳的时间序列数据的回归才是有效的。因此,在分析之前,判断我们所采用的时间序列的平稳性是非常必要的。
1.2 时间序列平稳性检验
时间序列的平稳性是时间序列计量分析有效性的基础,因此,时间序列的平稳性检验具有重要的实际意义。下面主要介绍单位根检验方法。
在式子
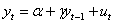 (1)
(1)
中,若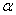 =0,则有
=0,则有
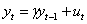 (2)
(2)
其中,ut为白噪声序列,上式称为一阶自回归过程,记为AR(1)。
 (3)
(3)
当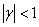 时,有
时,有
①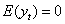 ;
;
②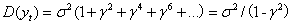 ;
;
③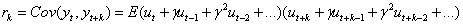
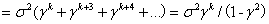
当时,yt满足平稳性的三个条件。所以,接受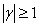 表明yt是非平稳序列,而拒绝原假设则就表明序列yt是平稳的。
表明yt是非平稳序列,而拒绝原假设则就表明序列yt是平稳的。
式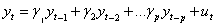 称为p阶自回归过程,记为AR(p)。
称为p阶自回归过程,记为AR(p)。
1.3 ARMA模型
1.3.1ARMA模型形式
对于平稳序列{y t},{a t}为零均值白噪声,满足:
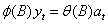 (4)
(4)
其中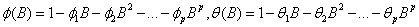 ,B为向后推移算子,
,B为向后推移算子,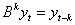 称模型为自回归移动平均模型(Auto-Regressive-Moving-Average Model),简记为ARMA(p,q)。?当q=0时,称为p阶自回归模型,记为AR(p);当p=0时,称为q阶滑动平均过程,记为MA(q)。
称模型为自回归移动平均模型(Auto-Regressive-Moving-Average Model),简记为ARMA(p,q)。?当q=0时,称为p阶自回归模型,记为AR(p);当p=0时,称为q阶滑动平均过程,记为MA(q)。
1.3.2模型定阶
模型定阶的方法主要有残差方差图定阶法、F检验定阶法和准则函数定阶法。常用的方法是准则函数定阶法,下面介绍几种准则函数定阶法。
准则定阶法,即确定一个准则函数,建模时按照该准则函数的取值大小确定模型的优劣,使准则函数达到极小的是最佳模型阶数。
⑴AIC准则
AIC准则 (A-Information Criterion最小信息准则)最先是日本学者Akaike提出,也称为赤池信息准则。它适用于AR、MA、ARMA三类模型的定阶。
设{y t:1≤t≤n}为一随机时间序列,对其拟合ARMA ( p ,q)模型,采用极大似然方法对模型估计参数, L为模型的极大似然值,AIC准则函数定义如下:
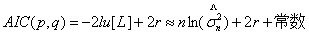 (5)
(5)
其中,r =p+?q为模型中独立参数的个数;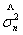 是残差方差的极大似然估计。在实际中,常用以下定义的AIC准则函数(用样本大小n标准化)
是残差方差的极大似然估计。在实际中,常用以下定义的AIC准则函数(用样本大小n标准化)
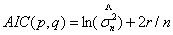 (6)
(6)
对于事先给定的最高阶数M(n),如果
 (7)
(7)
就认为p0和q0是最佳模型阶数。
⑵BIC准则
BIC信息准则与AIC类似,是由Schwarz提出来的,也称为Schwarz信息准则(记为SIC),对于ARMA模型定阶,BIC准则函数定义如下;
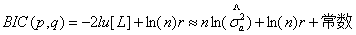 (8)
(8)
对于事先给定的最高阶数M(n),若某一阶数
 (9)
(9)
就认为p0和q0是最佳模型阶数。
⑶CAT准则
parzen在1977年建议采用如下模型选择准则,称为CAT:
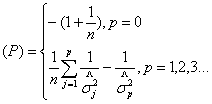 (10)
(10)
其中,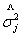 是当用AR ( j )模型对序列拟合时
是当用AR ( j )模型对序列拟合时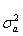 的无偏估计,n是观测个数。当CAT (p )达到极小时,称p为最优阶数。
的无偏估计,n是观测个数。当CAT (p )达到极小时,称p为最优阶数。
1.3.3模型参数估计
模型识别结束后,需要进行参数的估计,得出模型才是我们要的目的。参数估计方法主要有矩估计法、最小二乘估计法和极大似然估计法等。这里主要介绍矩估计法。矩估计法的基本思想是:ARMA模型的自相关函数(矩函数)可以表示为未知的模型参数的函数,反过来,模型参数原则上也可由自相关函数(矩函数)来表示。理论自相关函数由计算出的样本自相关函数代替,就得到了参数的估计值。
如AR ( p )过程:
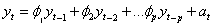 (11)
(11)
均值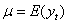 用
用 估计。为了估计
估计。为了估计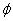 ,通过
,通过
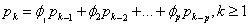 (12)
(12)
得到如下的Yule-Walder方程组
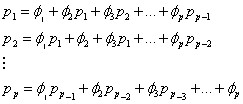 (13)
(13)
接着,用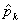 代替
代替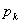 ,通过计算前面的线性方程组得到矩估计
,通过计算前面的线性方程组得到矩估计 ,
, …,
…, 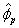 ,即
,即
 (14)
(14)
该估计量我们通常称为Yule-Walder估计。
在计算出,…, 后,利用下面结果
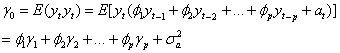 (15)
(15)
就可以得到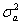 的矩估计为
的矩估计为
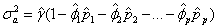 (16)
(16)
1.3.4模型适应性检验
模型的适应性是指一个时间序列模型解释系统动态性(即数据序列的相关性)的程度。一个适合的时间序列模型应该是完全或者基本上解释了系统的动态性。因此,模型中残差序列{at}应该是白噪声序列。故{at}序列的独立性检验就是模型的适应性检验。
相关函数法是先通过计算残序差列{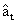 }的自相关函数,然后进行判断残差序列的独立性。设表示{}序列的自相关函数,即
}的自相关函数,然后进行判断残差序列的独立性。设表示{}序列的自相关函数,即
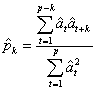 (17)
(17)
如果残差序列{at}是白噪声序列,那么是互不相关的,且~N(0,1/n)。
1.4ARIMA模型
在实际中,许多时间序列过程是非平稳的,这些非平稳时间序列可能有随时间变化的均值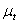 ,和随时间变化的二阶矩(如方差
,和随时间变化的二阶矩(如方差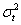 )。此时就需要对时间序列做适当的变换使其成为平稳序列。
)。此时就需要对时间序列做适当的变换使其成为平稳序列。
对于线性趋势的时间序列,可以对时间序列进行差分,即可消去线性趋势,差分后的时间序列就是平稳的。然后在对差分后得到的平稳时间序列进行建模建立ARMA模型。利用差分来建立的时间序列模型,全称为差分自回归移动平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA)。其中ARIMA(p,d,q)称为差分自回归移动平均模型,AR是自回归, p为自回归项;MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。即ARIMA模型为
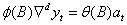 (18)
(18)
对于随着时间推移,方差不断增加的时间序列,可以通过其它适当的变换消除方差的不平稳性对时间序列的影响。常用的变量替换有:对数变换、平方根变换等等,具体方法视实际情况而定。
ARIMA模型的基本思想是:将预测对象随时间推移而形成的数据序列视为一个随机序列,用数学模型来描述,模型被识别后可以从时间序列的过去值及现在值来预测未来值。
ARIMA模型预测的基本程序如下:
1.根据时间序列的散点图、自相关函数和偏自相关函数图以ADF单位根检验其方差、趋势及其季节性变化规律,对序列的平稳性进行识别。
2.对非平稳序列进行平稳化处理。如果数据序列是非平稳的,并存在一定的增长或下降趋势,则需要对数据进行差分处理,如果数据存在异方差,则需对数据进行技术处理,直到处理后的数据的自相关函数值和偏相关函数值无显著地异于零。
3.根据时间序列模型的识别规则,建立相应的模型。若平稳序列的偏相关函数是截尾的,而自相关函数是拖尾的,可断定序列适合AR模型;若平稳序列的偏相关函数是拖尾的,而自相关函数是截尾的,则可断定序列适合MA模型;若平稳序列的偏相关函数和自相关函数均是拖尾的,则序列适合ARMA模型。
4.进行参数估计,检验是否具有统计意义。
5.进行假设检验,诊断残差序列是否为白噪声。
6.利用己通过检验的模型进行预测分析。
可用SPSS统计分析软件来进行ARIMA模型预测,可以省去繁琐的计算环节,简便、快捷,精度高。
ARIMA模型是单变量模型中最为完善的预测模型,但是它要求时间序列自身的变化呈现出某种规律性,而且这种规律还会持续到未来,另外,使用ARIMA模型进行预测时,未来各期的预测往往是单调上升或下降的,除非序列具有明显的季节性变化规律。普通多元回归分析在许多情况下并不适用,原因是自变量对因变量的作用和影响方式并非同步变化,一些自变量可能会领先因变量的变化,一些会对若干期的因变量持续产生影响。因此上述两类模型的应用都有一定的局限性。如果能将上述两种模型的优点结合在一起,会得到更佳的预测效果,模型的应用范围会更加广泛。这种模型就是传递函数模型,也称多变量ARIMA模型或ARIMAX模型。
1.5传递函数模型一般形式
传递函数模型可分为无噪声的传递函数模型和附加噪声的传递函数模型,实际问题中,输出序列往往会受到输入序列之外的各种干扰,因此附加噪声的传递函数模型应用更广。
假设xt ,yt都是可以通过适当变换使之成为平稳的序列。在单输入单输出系统中,输出序列yt与输入序列xt通过一个线性滤波相关联:
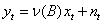 (19)
(19)
其中,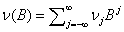 作为滤波的传递函数,xt将输入序列过滤传递到输出序列yt ,B为向后推移算子,nt是与输入序列xt独立的系统噪声序列。Box,Jenkins和 Reinsel称方程(19)为传递函数模型。若xt和nt服从ARMA模型时,式子(19)就是我们所熟知的ARMAX 模型。系数vj称为系统的脉冲响应权重或脉冲响应函数,是j的函数。如果这些脉冲响应权重序列是绝对可和的,即
作为滤波的传递函数,xt将输入序列过滤传递到输出序列yt ,B为向后推移算子,nt是与输入序列xt独立的系统噪声序列。Box,Jenkins和 Reinsel称方程(19)为传递函数模型。若xt和nt服从ARMA模型时,式子(19)就是我们所熟知的ARMAX 模型。系数vj称为系统的脉冲响应权重或脉冲响应函数,是j的函数。如果这些脉冲响应权重序列是绝对可和的,即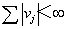 ,则传递函数模型被称为是稳定的。实际应用中,为了降低难度,我们用有理函数形式给出传递函数:
,则传递函数模型被称为是稳定的。实际应用中,为了降低难度,我们用有理函数形式给出传递函数:
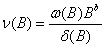 (20)
(20)
因此,实际应用的单变量传递函数模型一般表达式:
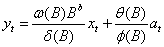 (21)
(21)
其中 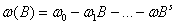
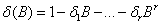


at为白噪声序列,b是一个滞后参数,表示输入变量对输出变量产生影响前需要的实际时间滞后期数。式(21)称为传递函数。
传递函数模型一般要求观测值至少应有30个。建模前要求序列均应为平稳时间序列, 平稳是指该序列的概率结构不随时间而变, 即均数不随时间变化, 方差不随时间变化, 自相关系数只与时间间隔有关而与所处的时间点无关。最简单的平稳序列就是白噪声。通常, 我们可以通过自相关图检验法或单位根检验法等方法来检验序列的平稳性。如果序列不平稳, 可利用对数变换、平方根转换、滤波、差分等手段来使之平稳。
传递函数模型的建模一般分为 3 步:
第 1 步, 利用预白噪化进行识别(确定参数b,s,r), 使用的分析工具是输入和输出之间的互相关函数。具体做法就是用一个 ARIMA 模型拟合输入序列, 该模型把残差降为白噪声, 然后再用此模型过滤输入序列得到白躁声残差序列。随后用同样的模型过滤输出序列, 并计算过滤后输出序列和过滤后输入序列的互相关系数。
第 2 步, 运用极大似然法、最小二乘法或非线性最小二乘法进行模型参数估计(确定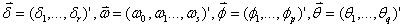 )。
)。
第 3 步, 利用 Q 统计量对残差进行自相关检验, 利用S统计量对残差和白噪化输入进行互相关检验。如果残差无自相关, 同时残差和白噪化输入也无相关, 模型即为所求。
1.5.1传递函数的性质
ARMA 模型定阶通过自相关函数和偏自相关函数初步判定,那么传递函数模型的统计性质也为传递函数的三个参数r,s和b的判定提供了依据。
由传递函数式(20),即
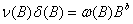
可以得到r,s和b的阶数以及它们与脉冲响应权重vj的关系
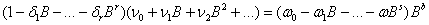
因此,可得
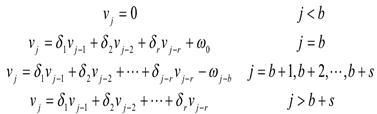 (22)
(22)
r个脉冲响应权重vb?+s??,vb?+s-1??,…,vb?+s-r+1??为差分方程
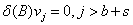 (23)
(23)
提供了初值。因此,传递函数(20)的脉冲响应权重应具有下述性质:
(1)b个零权重,v0 =v1 =…= vb-1 =0;
(2)s-r+1个权重vb,vb+1,…vb+s-r不固定形式;若s < r,不会出现这样的值;
(3)r 个初始脉冲响应权重vb+s-r+1,vb+s-r+2,…vb+s;
(4)对于 j>b+s,v j服从等式(23)给出的模型。
这里b是由j < b时v j=0, v b≠0确定的。
r 的值是由脉冲响应权重的形式来确定的。对于一个给定的b值,若r=0,则s的值可以通过j >b?+s时v j=0计算得出;
若r≠0,则s的值可以通过观测脉冲响应权重模式在何时开始衰减得出。
1.5.2传递函数稳定性
稳定性意味着当一个有界的输入就会产生一个有界的输出。传递函数模型的稳定性要求与 ARMA 模型平稳性要求类似。有所不同的是,除了要求传递函数部分的稳定性,同时也要求噪声部分的平稳性。如果脉冲响应权重是绝对收敛的,即,且特征方程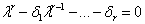 的根在单位圆内,此时系统称为稳定系统。对于噪声部分平稳性的要求与对ARMA模型平稳性要求一样,要求特征方程
的根在单位圆内,此时系统称为稳定系统。对于噪声部分平稳性的要求与对ARMA模型平稳性要求一样,要求特征方程 的根在单位圆内。对于非稳定系统,可以通过适当的差分或其它变换将系统转化为稳定系统。
的根在单位圆内。对于非稳定系统,可以通过适当的差分或其它变换将系统转化为稳定系统。
1.5.3传递函数模型识别
⑴互相关函数(CCF)
①互协方差函数和互相关函数
互相关函数是测度两个随机变量之间相关的强度和方向的常用函数。给定两个随机过程xt和yt,t =0,±1,±2,…当xt和yt都是一唯平稳过程,并且xt和yt的互协方差函数cov(xt, ys)仅与时间差(s-t)有关时,就称序列xt和yt是联合平稳序列。这种情况下,计算xt和yt的互协方差函数:
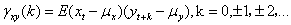 (24)
(24)
其中,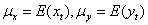 ,通过标准化,可得互相关函数(CCF):
,通过标准化,可得互相关函数(CCF):
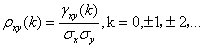 (25)
(25)
其中,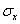 和
和 是xt和yt的标准差。
是xt和yt的标准差。
当且仅当k>0,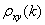 = 0,或者 k<0,=0时,序列xt和yt存在一个因果传递函数模型。若对某些k >0,≠0时,而对所有的k<0,=0时,则称序列xt导致yt。若对某些k<0,≠0时,而对所有的k >0,=0,则称序列序列yt导致xt。若对某些k >0,≠0,且对某些k<0,≠0,则称序列xt和yt存在互相反馈关系。若≠0,则称xt和yt存在同期关系。
= 0,或者 k<0,=0时,序列xt和yt存在一个因果传递函数模型。若对某些k >0,≠0时,而对所有的k<0,=0时,则称序列xt导致yt。若对某些k<0,≠0时,而对所有的k >0,=0,则称序列序列yt导致xt。若对某些k >0,≠0,且对某些k<0,≠0,则称序列xt和yt存在互相反馈关系。若≠0,则称xt和yt存在同期关系。
②样本互相关函数
在实际应用中,因为总体的互相函数是未知的,所以通常用样本互相关函数作为总体的互相函数估计。对于给定平稳时间序列xt和yt(1≤t≤n),互相关函数
可以通过样本互相关函数
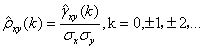 (26)
(26)
估计出来,其中
 (27)
(27)
其中, 、
、 、Sx和Sy分别是两个序列的均值和标准差。
、Sx和Sy分别是两个序列的均值和标准差。
③互相关函数与传递函数关系
互相关函数是识别传递函数的工具,而脉冲响应权重与互相关函数有关,故只要确定脉冲响应权重,传递函数随之确定。
对于时间?t+k,转换函数模型可以写为:
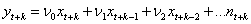 (28)
(28)
不失一般性,假设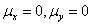 在方程(28)两边同时乘以xt,两边求期望得:
在方程(28)两边同时乘以xt,两边求期望得:
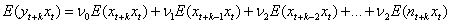 (29)
(29)
因为
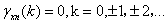
所以

因此
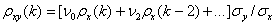 (30)
(30)
从(30)可以看出,互相关函数受到输入序列xt自相关函数和脉冲响应权重v j的影响。当输入序列xt是白噪声序列时,即对k≠0,=0,方程(30)可以化简成:
 (31)
(31)
此时,脉冲响应权重vk与互相关函数成比例关系。
⑵模型初步识别
①预白化输入序列x t
如果输入序列xt是白噪声,则可以得到如式(31)脉冲响应权重与互相关函数的关系式,因此先对输入序列xt做预白化处理。设传递函数为
(32)
设输入序列xt是一个平稳序列,其适应的模型为
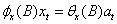
即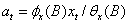 其中,a t是期望为0,方差为的白噪声序列。
其中,a t是期望为0,方差为的白噪声序列。
将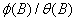 看成一个滤波器,对yt进行滤波变换,得
看成一个滤波器,对yt进行滤波变换,得
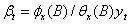 (33)
(33)
将(32)代入式(33),化简得
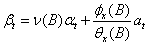
令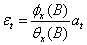 ,则
,则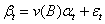 ,计算
,计算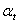 和
和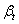 之间的样本的 CCF,
之间的样本的 CCF,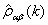 ,估计v k:
,估计v k:
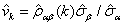
②传递函数部分识别
由式(22)的第一式可知前面b个脉冲响应权重为零,即
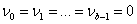
由传递函数的常见形式,知可由脉冲响应权重的呈现形式得到阶数r的值,又由式(31),显然可以直接由互相关函数图判断得到阶数r的值。
对于阶数s,若衰减从vb开始,则s =0;若衰减从vb+1开始,则s=1;若衰减从vb+2开始,则s =2。
③噪声部分识别
由模型,有
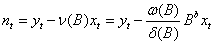 (34)
(34)
传递函数部分估计后,计算噪声序列估计
 (残差序列)
(残差序列)
噪声部分模型可以通过检验其样本的 ACF 和 PACF 进行识别:
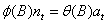
最终即可得到传递函数模型:
 (35)
(35)
1.5.4模型拟合与诊断
⑴模型估计
传递函数模型识别之后,就要进行参数估计,和ARMA 模型一样,主要的估计方法有矩估计法、最小二乘估计法和极大似然估计法等。
以最小二乘估计法为例,记待估计参数为:
由传递函数模型(35),可以改写模型为
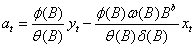 (36)
(36)
由样本序列(xt,yt)( t =1,2,…,N)求得样本残差序列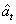 ( t =1,2,…,N), 是未知参数的函数,即
( t =1,2,…,N), 是未知参数的函数,即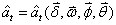 ,当
,当
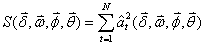 (37)
(37)
达到最小值时,求出的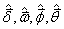 就是参数的最小二乘估计,且
就是参数的最小二乘估计,且
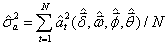
是白噪声a t的方差估计量。
⑵模型诊断检验
在模型识别和参数估计之后,还需对模型的进行适当性检验。检验内容分两部分,第一,传递函数模型是否拟合得当;第二,残差序列与输入序列x t派生出的预白化序列是否互相关。
①残差序列自相关检验
传递函数模型包括传递函数部分和噪声部分。如果传递函数模型拟合不当,则残差序列表现出自相关,如果是适当的模型,则残差序列自相关和偏自相关函数应无任何表现形式,此时残差序列可以看成白噪声序列的一个样本, 当样本容量足够大时,的自相关函数相互独立地服从 N ( 0,1/m),这里,m=n-u-p为可计算的观测值个数,其中,n是有效样本个数,u=max( r,s+b)检验统计量
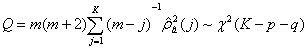
其中,p和q是噪声部分模型的参数个数;K一般取足够大。
②残差序列互相关检验
在传递函数模型(36)中,假设at是噪声序列,而且和输入序列x t 是互相独立,因此它就和输入序列
x t派生出的预白化序列独立。如果传递函数适当,残差和输入序列x t派生出的预白化序列之间样本互相关函数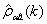 独立渐近服从N(0,1/m)。检验统计量S
独立渐近服从N(0,1/m)。检验统计量S
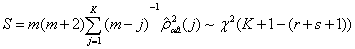 (38)
(38)
因为互相关函数有同期相关,所以式(38)从k =0开始。r+s+1是传递函数部分的参数个数。
1.6多变量传递函数模型
输出序列可能被多个输入序列影响,所以推广到多变量传递函数模型

或者
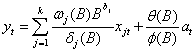
其中,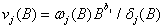 是输入序列x jt的j次传递函数,且at与每一个输入序列x jt, j =1,2,…,k独立。
是输入序列x jt的j次传递函数,且at与每一个输入序列x jt, j =1,2,…,k独立。
1.7变量带干预的时间序列模型
时间序列常受突发事件或特殊事件影响,诸如经济政策的改变、新环境法规的采纳、罢工以及广告促销活动。我们称这类外部事件为干预事件。干预分析模型是传递函数模型的一个特殊情况,使用传递函数模型可以解释干预事件对时间序列的影响。这里的输入序列是简单的指示性变量形式,一个仅仅取0或1的输入变量。
1.7.1单干预分析模型
单干预输入情形,干预分析模型有如下形式
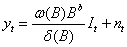
其中,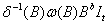 表示干预事件对时间序列yt的影响,It是输入干预变量,nt是噪声序列,假设
表示干预事件对时间序列yt的影响,It是输入干预变量,nt是噪声序列,假设
nt服从ARIMA模型,。噪声模式通常是时间序列yt在受到干预事件影响之前,用单变量模型识别方法加以识别。
⑴干预变量
常用的干预变量有两种类型:一类表示干预在时刻T发生,但其影响仍然保持,即干预是一个阶跃函数:
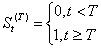
另一类表示是干预只在一个时点T发生,即干预是脉冲函数:
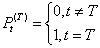
这里脉冲函数可以通过对阶跃函数差分而得到,即
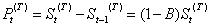
因此,一个干预模型可以等价地用阶跃函数或脉冲函数表示。
⑵干预响应形式
对于阶跃或脉冲干预有各种可能的响应,下面是常见的响应形式。
①突然发生,影响持续时间长久的输入干预影响的形式为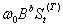 这里输入干预变量是
这里输入干预变量是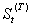 ,输出变量b期才做出反映,且影响强度为
,输出变量b期才做出反映,且影响强度为 ,之后继续保留下去,再不回到以前的状况。
,之后继续保留下去,再不回到以前的状况。
②缓慢发生,影响持续时间长久的输入干预影响形式为 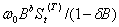 。
。
③突然发生,影响持续时间短暂的输入干预影响形式为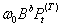 ,这里输入干预变量是
,这里输入干预变量是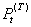 ,输出变量b期才做出反映,且影响强度为,之后干预影响消失,回到以前的状况。
,输出变量b期才做出反映,且影响强度为,之后干预影响消失,回到以前的状况。
④缓慢发生,影响持续时间短暂的输入干预影响形式为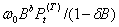 。
。
⑤各种响应都可以用阶梯和脉冲函数的不同组合来生成,如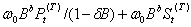
一般地,一个响应可以表示为有理函数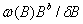 。b是干预影响的时间延迟,多项式
。b是干预影响的时间延迟,多项式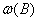 的权重
的权重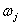 是用来表示干预影响的初始期值,多项式
是用来表示干预影响的初始期值,多项式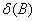 的根假设在单位圆上或者在圆外。单位圆上的根刻画额线性增长的响应现象,而单位圆外的根则表明具有渐变的影响。
的根假设在单位圆上或者在圆外。单位圆上的根刻画额线性增长的响应现象,而单位圆外的根则表明具有渐变的影响。
1.7.2模型识别、诊断及预测
干预分析模型虽然是传递函数模型中的特殊情况,但是在模型识别上有差异,这里的干预传递算子
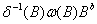 能以预白化技术为基础,这里应该通过考虑那些有可能造成变化或者影响的机制以及预期变化的隐含形式,来假定干预模型的形式。实际中,我们经常通过直接观察数据,以及数据序列图,以初步判定干预事件对时间序列的影响形式,初步得出干预算子形式。模型初步识别后,再利用传递函数模型参数估计方法估计参数值,通过参数显著性检验、残差序列的自相关检验,检验模型是否是适应的。
能以预白化技术为基础,这里应该通过考虑那些有可能造成变化或者影响的机制以及预期变化的隐含形式,来假定干预模型的形式。实际中,我们经常通过直接观察数据,以及数据序列图,以初步判定干预事件对时间序列的影响形式,初步得出干预算子形式。模型初步识别后,再利用传递函数模型参数估计方法估计参数值,通过参数显著性检验、残差序列的自相关检验,检验模型是否是适应的。
1.7.3多变量干预分析模型
对于多干预输入情形,有一般模型
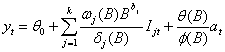
这里,Ijt,j =1,2,…,k是干预变量,这些干预变量或者是阶梯函数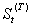 或者是脉冲函数。一般地,可以是特定的示性变量。第 j个响应的式子
或者是脉冲函数。一般地,可以是特定的示性变量。第 j个响应的式子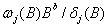 是根据对给定干预时的预期响应而设定的。
是根据对给定干预时的预期响应而设定的。
对于一个非平稳过程,模型通常不包含常数项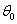 。
。
1.8变量带干预的传递函数模型
当时间序列受到外界突发事件影响时,需要考虑带干预变量,做干预分析模型。那么当一个时间序列不仅受到其它时间序列影响,而且还受到外界突发事件影响时,例如股市上的成交量与收盘价有影响,同时收盘价是个波动较大的序列,一旦有突然事件发生,收盘价受到较大的波动,此时不能再简单只是对该时间序列建立干预分析模型,也不能简单用输入序列建立输出序列的传递函数模型。针对这类情况的出现,提出了变量带干预的传递函数模型。
1.8.1模型简介
⑴输出变量带干预的传递函数模型
当一个时间序列受到其它序列影响,同时受到外界干预时,并且这里的突发事件只对该时间序列有影响。那么我们考虑对输出变量建立带有输入变量和干预变量的传递函数模型。简称输出变量带干预的传递函数模型,模型一般形式如下:
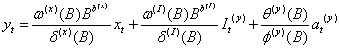
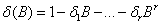
yt是输出变量,xt是输入变量,b (x)是xt的延迟参数,It(y)是yt的干预变量, b (I)是It(y)的延迟参数,这些干预变量或者是阶梯函数或者是脉冲函数, at(y)是yt白噪声序列。
推广到更多变量多干预情况:
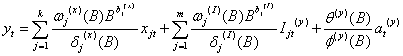
yt是输出变量,xjt(j =1,2,…,k)是输入变量,b j(x) (j =1,2,…,k)是xjt的延迟参数,Ijt(y) (j =1,2,…,m)是yt的干预变量,b j (I) (j =1,2,…,m)是I jt(y)的延迟参数,这些干预变量或者是阶梯函数或者是脉冲函数, at(y)是白噪声序列。
⑵输入变量带干预的传递函数模型
当输入变量受到外界影响时,且影响是十分显著的。由于输出变量与输入变量之间存在单向关系,所以在事件发生后,输出变量也受到影响,在这种情况下可以考虑事件发生时,输入序列建立干预分析模型,而不再是 ARMA 模型,再对输出序列建立传递函数模型。简称输入变量带干预的传递函数模型。模型一般形式如下:
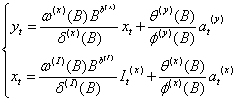
yt是输出变量,xt是输入变量,b (x)是xt的延迟参数,It(x)是xt的干预变量, b (I)是It(x)的延迟参数,这些干预变量或者是阶梯函数或者是脉冲函数, at(y) 和at(x)是yt和xt白噪声序列。
推广到多变量多干预情况:
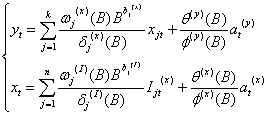
yt是输出变量,xjt(j =1,2,…,k)是输入变量,b j(x) (j =1,2,…,k)是xjt的延迟参数,Ijt(x) (j =1,2,…,n)是xjt的干预变量,b j (I) (j =1,2,…,n)是I jt(x)的延迟参数,这些干预变量或者是阶梯函数或者是脉冲函数, at(y) 和at(x)是yt和xt白噪声序列。
⑶输入输出变量带干预传递函数模型
当输出变量和输入变量同时受到不同的干预事件影响时,当这些的干预事件不相影响,就需要分别对输出变量和输入变量都建立带有干预变量的模型,再建立传递函数模型,简称输入输出变量带干预传递函数模型。模型一般形式如下:
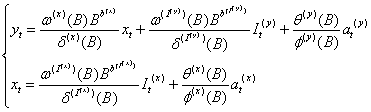
yt是输出变量,xt是输入变量,b (x)是xt的延迟参数,It(y)是yt的干预变量, 是It(y)的延迟参数,It(x)是xt的干预变量,
是It(y)的延迟参数,It(x)是xt的干预变量, 是It(x)的延迟参数,这些干预变量或者是阶梯函数或者是脉冲函数, at(y) 和at(x)是yt和xt白噪声序列。
是It(x)的延迟参数,这些干预变量或者是阶梯函数或者是脉冲函数, at(y) 和at(x)是yt和xt白噪声序列。
推广到多变量多干预情况:
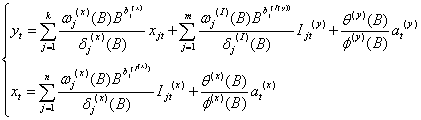
yt是输出变量,xjt(j =1,2,…,k)是输入变量,b j(x) (j =1,2,…,k)是xjt的延迟参数,Ijt(y) (j =1,2,…,m)和Ijt(x) (j =1,2,…,n)分别是yt和xt的干预变量,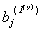 和
和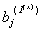 分别是Ijt(y) 和Ijt(x)的延迟参数,这些干预变量或者是阶梯函数或者是脉冲函数, at(y) 和at(x)是yt和xt白噪声序列。
分别是Ijt(y) 和Ijt(x)的延迟参数,这些干预变量或者是阶梯函数或者是脉冲函数, at(y) 和at(x)是yt和xt白噪声序列。
2传递函数模型在土壤溶质运移中的模拟
Jury(1982)等提出了模拟田间稳定流条件下保守溶质Br-运移的TFM(Tromsfer Function Model)。该模型通过研究溶质从土壤表面运移到土壤某一深度历经时间的概率密度函数(probability density function,简称pdf),来推求溶质平均浓度与时间和土壤深度的关系,并以此来模拟溶质在土壤中的运移.在以后的研究中,Jury等(1986)、White等(1986)、Jury等(1990)又把该模型推广运用于模拟非稳定流场中田间土壤示踪溶质Br-的运移。
TFM把土壤视为时不变系统,把溶质输入和输出过程与溶质分子在土壤中的运移与转化过程的概率联系起来,其输出可通过卷积方程得到。它主要考虑溶质在土体“两端”的输入和输出过程,利用系统辨识的方法,求出溶质分子在土体中历经时间的概率密度函数从而对土壤溶质运移过程作出模拟和预测。
一般而言,溶质进入土体的方式可概化为阶跃输入和脉冲输入,无论对于哪种方式,传递函数方程的一般形式均为:
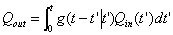 (39)
(39)
式中Qout(t)为溶质质量在观测时间t通过下边界,或吸附进入固相,或挥发进入气相,或转化为另一不同形式而消失等方式离开土壤的损失速率;Qin(t′)为较早时间t'溶质质量进入土壤的速率;g[(t-t')′]为溶质寿命关于溶质进入土壤时间的条件概率密度函数或传递函数。式(39)表明:在时间t溶质质量从土壤中的累积损失速率等于累积的加权溶质质量输入速率,该权重因子是溶质寿命的条件概率密度,溶质的寿命等于时间t和较早时间t'之差。传递函数方程将溶质的输入过程Qin(t′)与输出过程Qout(t)联系起来。某一特定溶质运移现象的g[(t-t′) t′]的求解问题,即为给定有关溶质输入和输出速率的实验数据将式(39)作为时间的方程来求解。
脉冲输入(如降雨或灌溉历时与对溶质运移过程的监测时间相比很短时,可视为此种输入),其对土壤的物理扰动最轻微,因此,系统对溶质的反应完全可由隐含于溶质寿命pdf的内在的土壤过程所决定,溶质质量输入速率在决定溶质质量损失速率方面不起主要作用。故可假设溶质从土壤表层的输入Qin(t′)与从出流表面的输出Qout(t)是两个独立的随机过程,即假定溶质寿命的概率密度函数与输入时间t′无关,则式(39)可简化为:
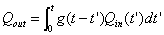 (40)
(40)
又脉冲输入速率可近似表为:
 (41)
(41)
这里,k为归一化常数, 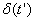 为Dirac函数,由其性质,可将方程(40)进一步简化为:
为Dirac函数,由其性质,可将方程(40)进一步简化为:
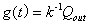 (42)
(42)
若溶质仅仅通过一个出流面流失,而忽略通过其它方式溶质的损失,式(42)中g(t)便成为溶质历经时间而非方程(39)所定义的溶质寿命的pdf.这样,式(42)就可写成:
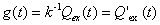 (43)
(43)
式中Qex(t)为溶质的出流速率.
另一方面,显然有
 (44)
(44)
比较(43)、(44)两式便知: 
式(44)即为通过实验数据由计算间接获得pdf的公式。
经田间和室内土柱实验的验证,表明运用历经时间pdf呈如下对数正态分布的TFM能够较好地模拟溶质在土壤中的运移:
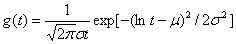 (45)
(45)
其中μ和σ2分别为lnt的均值和方差。
若已知g(t;λ),μ和σ2∈参数空间λ,则用极大似然法估算μ和σ2的似然函数L形如:
 (46)
(46)
式中N为实验取样观察次数, CK为不同观测时段以式(44)表示的规一化浓度,ΔtK为观测时段。
式(46)取对数并对其中参数求导得:
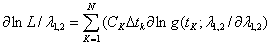 (47)
(47)
进一步地可导出:
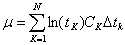 (48)
(48)
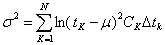 (49)
(49)
在研究排水条件下溶质历经时间的pdf时,时间中值tm和时间均值 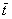 是描述pdf特性十分重要的时间变量。tm是指施于土壤表面的一个溶质分子有50%概率出现在所感兴趣的的排水深度时所用的时间,其计算公式为:
是描述pdf特性十分重要的时间变量。tm是指施于土壤表面的一个溶质分子有50%概率出现在所感兴趣的的排水深度时所用的时间,其计算公式为:
tm=exp(μ) (50)
而 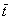 定义为表施溶质的一半已经到达所感兴趣的排水深度时所用的时间,计算公式如下:
定义为表施溶质的一半已经到达所感兴趣的排水深度时所用的时间,计算公式如下:
=exp(μ+ σ2/2) (51)
White(1987)定义:参与溶质运移的土壤体积含水量为:θst=q0tl-1,其中q0为平均降雨强度;t为中值或均值历经时间;l为从土壤表面到地下排水工程的距离。上式适用于雨强较大、排水工程埋深较浅的湿润气候区。对于脉冲灌水条件下,土壤非稳定流场中的溶质运移而言,入渗水和原有土壤水是一个不稳定的混合过程,它们对土壤溶质运移的贡献不同。一般用出流速率d(t,l)代替q0则更能反映参与输运土壤溶质出流的那部分水体。于是有
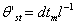 (52)
(52)
和 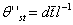 (53)
(53)
以氮素为例,White(1987)研究了降雨条件下氮素在土壤中的淋失,给出在时段[t1,t2]内淋失量的表达式:
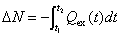 (54)
(54)
而对于给定的观测时段[0,t],以脉冲注入的溶质通过出流口的累积淋失量(忽略上式中表示淋失量是减少意义的负号)为:
 (55)
(55)
令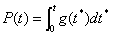
联立和两式解得:
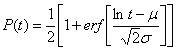 (57)
(57)
则
 (58)
(58)
3传递函数模型在神经网络中的应用
目前,传递函数模型的构建方法主要有线性回归、非线性回归、神经网络等,其中,基于前馈神经网络理论建立的传递函数由于不需要先验假设,可通过迭代运算获得目标变量的最优函数,具有较大的优越性。下面简要介绍了概率神经网络(PNN)的结构模型、功能、基本学习算法。
3.1概率神经网络模型
概率神经网络(Probabilistic Neural Networks,PNN)是由D. F. Specht在1990年提出的。主要思想是用贝叶斯决策规则,即错误分类的期望风险最小,在多维输入空间内分离决策空间。它是一种基于统计原理的人工神经网络,它是以Parzen窗口函数为激活函数的一种前馈网络模型。PNN吸收了径向基神经网络与经典的概率密度估计原理的优点,与传统的前馈神经网络相比,在模式分类方面尤其具有较为显著的优势。
3.1.1概率神经网络分类器的理论推导
由贝叶斯决策理论:
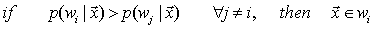 (59)
(59)
其中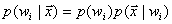 。
。
一般情况下,类的概率密度函数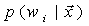 是未知的,用高斯核的Parzen估计如下:
是未知的,用高斯核的Parzen估计如下:
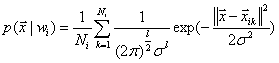 (60)
(60)
其中,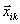 是属于第
是属于第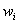 类的第k个训练样本,
类的第k个训练样本, 是样本向量的维数,
是样本向量的维数,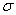 是平滑参数,
是平滑参数,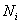 是第类的训练样本总数。
是第类的训练样本总数。
去掉共有元素,判别函数可简化为:
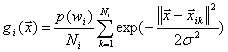 (61)
(61)
3.1.2概率神经元网络的结构模型
PNN的结构以及各层的输入输出关系量如图1所示,共由四层组成,当进行并行处理时,能有效地进行上式的计算。
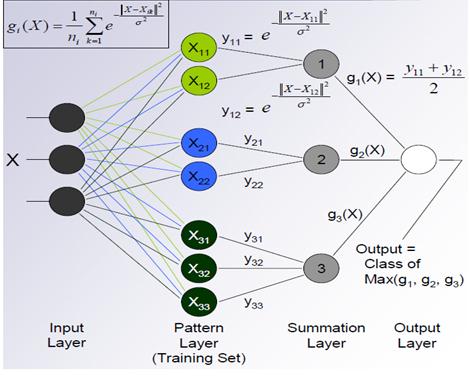
图 1 概率神经网络结构(以3个类别为例)
如图1-1所示,PNN网络由四部分组成:输入层、样本层、求和层和竞争层。PNN的工作过程:首先将输入向量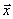 输入到输入层,在输入层中,网络计算输入向量与训练样本向量之间的差值
输入到输入层,在输入层中,网络计算输入向量与训练样本向量之间的差值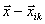 ,差值绝对值
,差值绝对值 的大小代表这两个向量之间的距离,所得的向量由输入层输出,该向量反映了向量间的接近程度;接着,输入层的输出向量送入到样本层中,样本层结点的数目等于训练样本数目的总和,
的大小代表这两个向量之间的距离,所得的向量由输入层输出,该向量反映了向量间的接近程度;接着,输入层的输出向量送入到样本层中,样本层结点的数目等于训练样本数目的总和,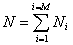 ,其中M是类的总数。样本层的主要工作是:先判断哪些类别与输入向量有关,再将相关度高的类别集中起来,样本层的输出值就代表相识度;然后,将样本层的输出值送入到求和层,求和层的结点个数是M,每个结点对应一个类,通过求和层的竞争传递函数进行判决;最后,判决的结果由竞争层输出,输出结果中只有一个1,其余结果都是0,概率值最大的那一类输出结果为1。
,其中M是类的总数。样本层的主要工作是:先判断哪些类别与输入向量有关,再将相关度高的类别集中起来,样本层的输出值就代表相识度;然后,将样本层的输出值送入到求和层,求和层的结点个数是M,每个结点对应一个类,通过求和层的竞争传递函数进行判决;最后,判决的结果由竞争层输出,输出结果中只有一个1,其余结果都是0,概率值最大的那一类输出结果为1。
3.2基本学习算法
以下几步构成了PNN神经网络的算法:
第一步:首先必须对输入矩阵进行归一化处理,这样可以减小误差,避免较小的值被较大的值“吃掉”。设原始输入矩阵为:
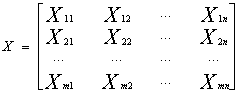 (62)
(62)
从样本的矩阵如式(62)中可以看出,该矩阵的学习样本有m个,每一个样本的特征属性有n个。在求归一化因子之前,必须先计算 矩阵:
矩阵:
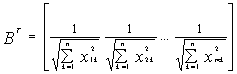
然后计算:
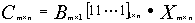 =
=
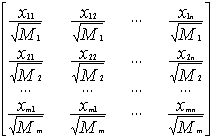
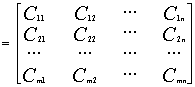 (63)
(63)
式中, 
则归一化后的学习矩阵为C。在式(63)中,符号“ ”表示矩阵在做乘法运算时,相应元素之间的乘积。
”表示矩阵在做乘法运算时,相应元素之间的乘积。
第二步:将归一化好的m个样本送入到网络样本层中。因为是有监督的学习算法,所以很容易就知道每个样本属于那种类型。假设样本有m个,那么一共可以分为c类,并且各类样本的数目相同,设为k,于是m=k*c。
第三步:模式距离的计算,该距离是指样本矩阵与学习矩阵中相应元素之间的距离。假设将由P个n维向量组成的矩阵称为待识别样本矩阵,则经归一化后,需要待识别的输入样本矩阵为:
 (64)
(64)
计算欧式距离:就是需要识别的样本向量,样本层中各个网络节点的中心向量,这两个向量相应量之间的距离:
 (65)
(65)
第四步:样本层径向基函数的神经元被激活。学习样本与待识别样本被归一化后,通常取标准差 =0.1的高斯型函数。激活后得到初始概率矩阵:
=0.1的高斯型函数。激活后得到初始概率矩阵:

(66)
第五步:假设样本有m个,那么一共可以分为c类,并且各类样本的数目相同,设为k,则可以在网络的求和层求得各个样本属于各类的初始概率和:
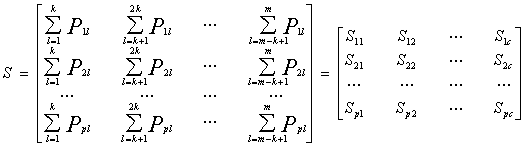
(67)
在上式中,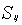 代表的意思是:将要被识别的样本中,第i个样本属于第j类的初始概率和。
代表的意思是:将要被识别的样本中,第i个样本属于第j类的初始概率和。
第六步:计算概率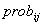 ,即第i个样本属于第j类的概率。
,即第i个样本属于第j类的概率。
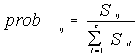 (68)
(68)
参考文献:
[1] 倪雅茜,张文华,郭生练.流量过程线分割方法的分析探讨[J].水文,2005,25(3):10-14,19.
[2] 詹道江,叶守泽.工程水文学[M].3版.北京:中国水利电力出版社,2000.
[3] 刘清华,史红亮,安书全.人工神经网络在地表径流预报中的应用[J].三峡大学学报:自然科学版,2007,29(4):292-294.
[4] 顾慰祖,谢 民.同位素示踪划分藤桥流域流量过程线的试验研究[J].水文,1997(1):29-32,23.
[5] Mazvimavi D, Meijerink A M J, Stein A. Prediction of Base Flows from Basin Characteristics: a Case Study from Zimbabwe [ J]. Hydrological Sciences Journal,2004,49(4):703-715.
[6] 黄国如.流量过程线的自动分割方法探讨[J].灌溉排水学报,2007,26(1):73-78.
[7] Sloto R A, Crouse M Y. HYSEP: HYSEP: A Computer Program for Streamflow Hydrograph Separation and Analysis: U.S. Geological Survey Water-Resources Investigations Report 96-4040[M]. Lemoyne, Pennsylvania: U.S. Department of the Interior, 1996:46.
[8] Lyne V D, Hollick M. Stochastic Time Variable Rainfall Runoff Modeling: Proceedings of Hydrology and Water Resources Symposium [M]. Perth, Australia:National Committee on Hydrology and Water Resources of the Institution of Engineers, 1979:89-92.
[9] Institute of Hydrology. Low flow studies: Research Report[M]. Wallingford, UK.: Institute of Hydrology,1980.
[10] Eckhardt K. How to Construct Recursive Digital Filters for Baseflow Separation [J]. Hydrological Processes,2005,19:507-515.
[11] Nathan R J and McMahon T A. Evaluation of Automated Techniques for Base Flow and Recession Analyses[J]. Water Resources Research, 1990,26 (7): 1465-1473.
[12]黄真理,李玉粱,李锦秀, 等. 三峡水库水环境容量计算 [J]. 水利学报, 2004,3: 7-14. (HUANG Zhenli, LI Yuliang, LI Jinxiu, et al .The calculation of Three Gorges reservoir water capacity [J]. Journal of Hydraulic Engineering, 2004, 3: 7-14. (in Chinese))
[13] 陈强, 李德靖, 赵兴明. 浅析青海省地下水资源评价中的基流分割[J]. 水资源与水工程学报, 21 (1): 164-167.(CHEN Qiang, LI Dejing, ZHAO Xingming. Simply analysis on the evaluation of groundwater resources in baseflow separation in Qinghai Province[J]. Journal of Water Resources and Water Engineering, 21 (1):164-167. (in Chinese))
[14] 成小松, 刘宗义. 浅析贵州省地下水资源评价中的基流分割 [J].贵州水力发电,2006, 20 (5): 11-14.(CHENG Xiaosong,LIU Zongyi.Simply analysis on the evaluation of groundwater resources in baseflow separation in Guizhou Province [J]. Guizhou Water Power,2006, 20(5): 11-14. (in Chinese))
[15] 石伟, 王光谦. 黄河下游生态需水量及其估算 [J]. 地理学报,2002,57 (5): 595-602.(SHI Wei, WANG Guangqian. The downstream of Yellow River ecological water demand and its estimation [J]. ActaGeographica Sinica, 2002, 57(5): 595-602. (in Chinese)))
[16] Santhi, C., Arnold J., Williams J., et al. Validation of the SWAT model on a large RWER basin with point and nonpoint sources [J].JAWRA Journal of the American Water Resources Association,2001, 37(5): 1169-1188.
[17] 陈利群, 刘昌明, 李发东. 基流研究综述 [J]. 地理科学进展,2006,25 (001): 1-15. (CHEN Liqun, LIU Changming, LI Fadong. Research of baseflow [J]. Progress in Geography, 2006, 25(1): 1-15.(in Chinese))
[18] Nathan, R., McMahon T. Evaluation of automated techniques forbase flow and recession analyses [J]. Water Resources Research,1990, 26(7): 1465-1473.
[19] Arnold, J., Allen P. Automated methods for estimating baseflow and ground water recharge from streamflow records [J]. JAWRA Journal of the American Water Resources Association, 1999, 35 (2): 411-424.
[20] 程佩青 . 数字滤波与快速傅里叶变换 [M]. 清华大学出版社 ,1990. (CHENG Peiqing. Digital Filtering and Fast Fourier Transform [M]. Tsinghua University Press, 1990. (in Chinese))
[21] 林凯荣, 陈晓宏, 江涛, 等. 数字滤波进行基流分割的应用研究[J]. 水力发电,2008, 34(6): 28-30. ( LIN Kairong, CHEN Xiaohong, JIANG Tao, et al. Digital filter for the application of research baseflow separation [J]. Water Power,2008, 34 (6): 28-30.(in Chinese))
[22] Lyne, V., Hollick M., Stochastic time-variable rainfall-runoff modeling[A].In:Hydrology and Water Resources Symposium [C]. Australia: National Committee on Hydrology and Water Resources of the Institute of Engineering,,Western Australia, 1979:89-93.
[23] Aksoy, H., Kurt I., Eris E. Filtered smoothed minima baseflow separation method [J]. Journal of Hydrology, 2009, 372(1-4): 94-101.
[24] 董晓华, 邓霞, 薄会娟, 等. 平滑最小值法与数字滤波法在流域径流分割中的应用比较[J]. 三峡大学学报: 自然科学版, 2010,32(2): 1 -4. ( DONG Xiaohua, DENG Xia, BO Huijuan, et al. The Application comparison of minimum smoothing method and digital filtering in the streamflow separation [J]. Journal of China Three Gorges University(Natural Sciences), 2010,32(2): 1-4. (in Chinese))
[25] Mau DP,Winter TC. Estimating groundwater recharge from streamflow hydrographs for a small mountain watershed in a temperate humid climate,New Hampshire,USA. Groundwater,1997,35: 291-304
-
论文阅读报告要求及范例
科技论文阅读报告要求:1.撰写科技论文阅读报告是对阅读的一个归纳和提炼,并针对这些问题提出自己的见解。2.中文撰写,1-3页,主要…
-
论文类读书报告格式
读书报告格式读书报告一般写法是先介绍书的内容,然后谈自己的看法。读书报告具体要求格式如下:1、报告统一用A4打印稿形式提交;为节约…
-
论文读书报告模板
读书报告模板使用本模板撰写时请按照蓝色提示定稿后请删掉蓝色提示大标题字体14号宋体居中加粗标题应准确清楚简洁地概括全文25个字以内…
-
期刊论文读书笔记格式
期刊论文读书笔记格式初稿一期刊论文概述可以用表的形式题目作者包括作者单位主要观点主要研究方法个人评论二主要观点及其论证过程选择13…
-
论文阅读报告
论文阅读报告撰写人张胜时间10月9号一标题ParallelSpectralDistributedSystems二出处Cluster…
-
大学生毕业论文读书笔记
“专业文献读、写、议”读书笔记会计082*********一篇完整的本科毕业设计论文通常由封面、摘要、关键词、目录、前言(引言)、…
-
论文阅读报告
题目注意:1.阅读一篇论文时,要始终带着疑问去读,首先搞清楚为什么要读这篇论文,这篇论文能给我们提供哪些帮助,针对论文提出的解决方…
-
读书报告范文
抒写个性与济世载道——周作人《中国新文学的源流》读书报告摘要:周作人的人生观和文学观始终交织着表现个性和国民性的矛盾运动。他的“言…
-
论文类读书报告格式
读书报告格式读书报告一般写法是先介绍书的内容,然后谈自己的看法。读书报告具体要求格式如下:1、报告统一用A4打印稿形式提交;为节约…
-
大学生读书报告范文
大学生读书报告范文读书报告的格式读书报告应当包括下列内容:(1)内容提要:概括性地归纳书的主要内容,包括作者陈述的基本观点(最好不…
-
读书心得论文
读书心得论文书到用时方恨少,事非经过不知难。《学记》曰:“是固教然后知困,学然后知不足也。”对于我们教师而言,要学的东西太多,而我…