数据挖掘实验报告
数据挖掘实验报告
——药物研究
专业:
学号:
姓名:
时间:2011.12.08
一、实验目的
1、学习数据挖掘的理论知识,理解数据挖掘的目的和意义;
2、熟悉SPSS Clementine软件的功能,并学习使用该软件对数据进行分析;
3、对该软件提供的数据DRUG1n进行分析,了解人体的血压、类胆固醇、Na、K等的含量对人体的健康状况的影响。
二、实验环境
系统环境:Windows XP
软件环境:SPSS Clementine11.1
软件简介:作为一个数据挖掘平台, Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比, Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
SPSS Clementine软件中提供的数据DRUG1n,一共有200条数据,包含7个字段分别是Age(年龄)、 Sex(性别)、 BP(血压)、 Cholesterol (类胆固醇含量)、Na (Na含量)、K(K含量)、 Drug(药品种类)。
三、实验数据
本实验所使用的数据是SPSS Clementine软件中提供的数据DRUG1n,一共有200条数据,包含7个字段分别是Age(年龄)、 Sex(性别)、 BP(血压)、 Cholesterol (类胆固醇含量)、Na (Na含量)、K(K含量)、 Drug(药品种类)。
四、实验步骤与分析过程
本次实验,首先DRUG1n中的数据进行了一个简单的分析和解释,比如说Drug(药品)的分布情况、Na和K的含量等的分析。接着决策树分析的方法对数据进行分类和分析。
本实验所建立的数据流如图1所示,
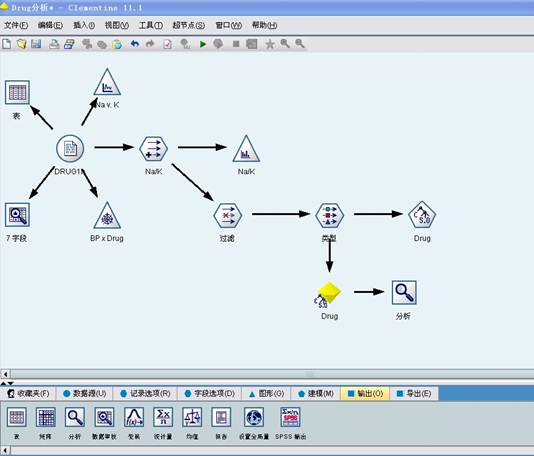
图1
具体的分析步骤如下:
第一部分:新建工作流,附加数据
1、打开软件,新建一个流,命名“Drug分析”。从数据源中选择“可变文件”拖入工作框,双击附加添加。如图2。

图2
第二部分:步骤1-4所示对Drug 1n的数据进行一个简单探索,了解数据的组成规律。步骤5、6所示,对字段进行选择重新分析Na和K的浓度.步骤7-11,先对数据进行过滤后执行C5.0分析。
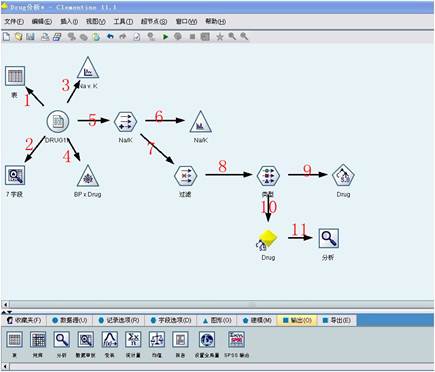
图3
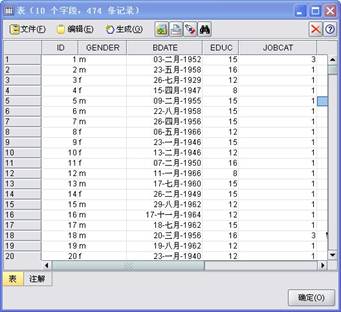 1、浏览数据内容。在输出选项中选择“表格”节点加到数据流中,执行该节点,如图3中的1-1步骤,所生成的数据表名将列在流管理窗口的输出选项中,结果如图4所示。
1、浏览数据内容。在输出选项中选择“表格”节点加到数据流中,执行该节点,如图3中的1-1步骤,所生成的数据表名将列在流管理窗口的输出选项中,结果如图4所示。
图4
2、观察各个变量的数据分布特征。在输出选项卡中选择“数据审核”节点添加到数据流中,执行该节点,如图3中的1-2步骤,所生成的数据如图5所示。

图5
可以看到,该数据有200个样本,7个字段。对Age、Na、K这三个数值型变量,计算且输出最小值、最大值、均值、标准值、偏系数等基本描述统计量。数据显示,病人的年龄差距比较大。
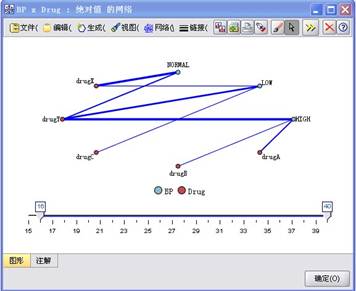 3、不同血压特征病人的药物选择。在“图形”选项卡中选择“网络”节点加到数据流中,设置节点参数指定绘制关于Drug和BP的网状图,执行该节点,如图3中1-3步骤,所生成的图形如图6所示。
3、不同血压特征病人的药物选择。在“图形”选项卡中选择“网络”节点加到数据流中,设置节点参数指定绘制关于Drug和BP的网状图,执行该节点,如图3中1-3步骤,所生成的图形如图6所示。
图6
4、观察服用不同药物的病人唾液中钾钠的含量情况。在“图形”选项卡中选择“图形”节点加到数据流中,设置节点参数,指定Na为X轴,K为Y轴,服用不同的Drug的病人采用不同颜色的点,执行该节点,执行该节点,如图3中1-4步骤,所生成的图形如图7所示。
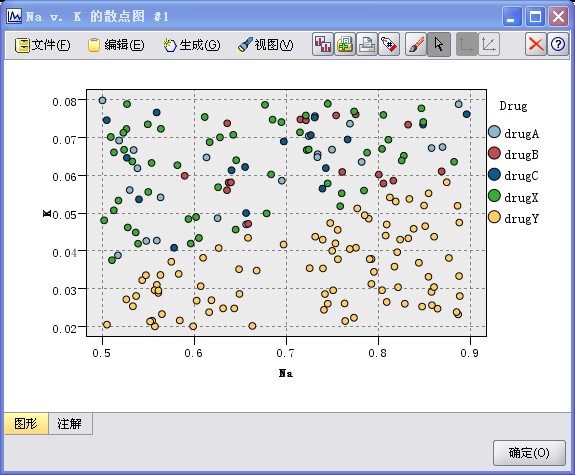
图7
5、观察服用不同药物病人唾液中钠钾的浓度比例情况。为了更准确地评价药物状况单纯的。在“字段”选项卡中选择“导出”节点加到数据流中,设置节点参数,指定Na为X轴,K为Y轴,服用不同的Drug的病人采用不同颜色的点,执行该节点,执行该节点,如图3中5步骤。
6、从导出的新字段中,选择“图形”中的“直方图”选项卡,设置节点参数绘制Na/K的直方图,且服用不同药物的病人采用不同的颜色。执行该节点,如图3的步骤6,所生成的图形如图8所示。
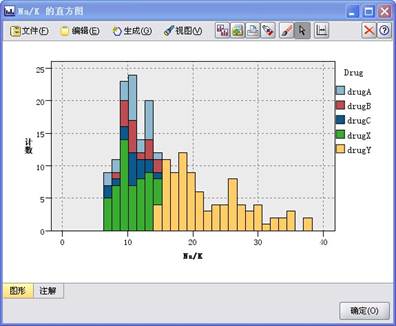
图8
7、全面分析决定药物所选择的其他影响因素。通过前面的分析,似乎对选择DrugY的依据有了一定的结论,但是没有考虑Age、Sex、BP、Cholesterol、Na/K的综合角度分析选择不同的药物依据。
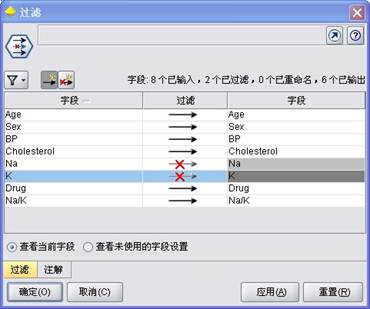 首先,在建模中将不再直接采用Na和K的变量,而是采用Na/K,因此应先将变量K和Na删掉。在“字段”中选择“类型”节点加到数据流中,如图3中的步骤7,如图9所示。
首先,在建模中将不再直接采用Na和K的变量,而是采用Na/K,因此应先将变量K和Na删掉。在“字段”中选择“类型”节点加到数据流中,如图3中的步骤7,如图9所示。
图9
8、然后,指定建立模型过程中各个变量的作用,这里的Age、Sex、BP、Cholesterol、Na/K为解释变量,称为模型的输入变量,Drug为被解释变量,称为模型的输出变量,在“字段”选项卡中选择“类型”节点加到数据流中,设置参数指定不同变量的作用角色,如图3中步骤8,如图10所示。

9、最后,在“模型”选项卡选择C5.0节点加到数据流中。选择C5.0模型,执行C5.0节点,如图1-3中步骤9所示,生成的模型名将列在流管理窗口的模型选项卡,右击鼠标,选择弹出菜单中的“浏览”选项,浏览结果,如图10所示。
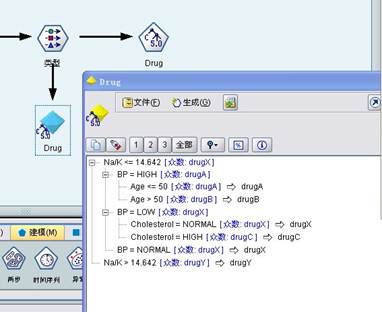
图10
可以看出,当病人的Na/K值高于14.642时,应选择DrugY,无需考虑其他因素。当病人的Na/K值低于14.642时,对于高血压病人,年龄是主要的判断依据,年龄低于50岁时,更适合选用DrugA,高于50岁的则应选择DrugB;对于低血病人,则应依据其胆固醇指标选择DrugX和DrugC。对于血压正常的病人可选择DrugX。性别对选择药物没有影响。
10、模型的预测精度评价。首先,选择流管理窗口中的模型选项卡,右击鼠标,选择弹出的菜单中的增加评价选项,将模型算结果增加到数据流中,如图3中的步骤10;然后,在输出选项卡中选择分析节点并与模型结果节点相连,执行分析节点,如图3中的步骤11,所生成的结果如图11所示。
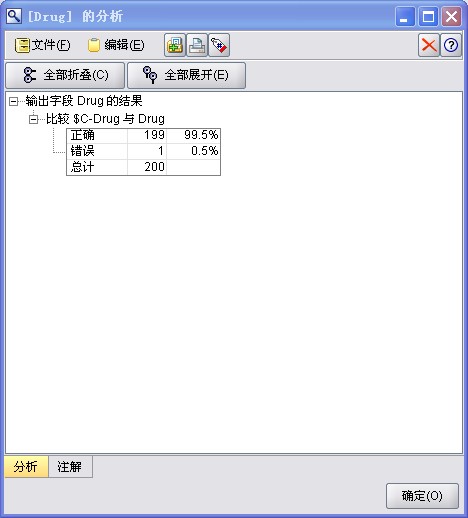
五、实验总结
在本次实验中,从新建工作流一直到获得最终结果,整个流程让我对数据挖掘中数据分析处理的基本方法有了深入的了解,特别是C5.0模型应用的理解,同时,也学会了如何使用 Clementine 通过建模(使用 GRI)和直观化(使用 Web 显示)发现数据库中的关系(即链接)以及利用这些链接与数据中的案例组相对应关系可以通过建模(使用 C5.0 规则集)可详细研究这些组并描绘其特征,增强了运用Clementine11.1的能力。
通过这次学习让我意识到,对于数据我们不仅要能会用spss统计来分析它的规律,也要能会通过数据挖掘软件来挖掘数据当中的潜在信息,更好的数据使用者。
第二篇:数据挖掘实验报告5
甘肃政法学院
本科生实验报告
(五)
姓名:贾燚
学院:计算机科学学院
专业:信息管理与信息系统
班级:10级信管班
实验课程名称:数据仓库与数据挖掘
实验日期:20##年12月14日
指导教师及职称:朱正平
实验成绩:
开课时间:20##-20##学年二学期
甘肃政法学院实验管理中心印制

-
数据挖掘实验报告
数据挖掘实验报告K最临近分类算法学号311062202姓名汪文娟一数据源说明1数据理解选择第二包数据IrisDataSet共有15…
- 数据挖掘实验报告
-
数据挖掘实验报告4
甘肃政法学院本科生实验报告四姓名贾燚学院计算机科学学院专业信息管理与信息系统班级10级信管班实验课程名称数据仓库与数据挖掘实验日期…
-
数据挖掘实验报告
数据挖掘实验报告药物研究专业学号姓名时间20xx1208数据挖掘实验报告药物分析一实验目的1学习数据挖掘的理论知识理解数据挖掘的目…
-
数据挖掘实验报告
计算机科学与技术系数据挖掘实验报告姓名学号授课教师完成时间1数据挖掘实验报告评分2目录1数据挖掘综述411什么是数据挖掘412数据…
-
数据挖掘读书报告
读书报告数据挖掘可以看成是信息技术自然化的结果。数据挖掘(Datamining),又译为资料探勘、数据采矿。它是数据库知识发现(K…
-
数据挖掘实验报告 超市商品销售分析及数据挖掘
通信与信息工程学院课程设计说明书课程名称数据仓库与数据挖掘课程设计题目超市商品销售分析及数据挖掘专业班级电子商务理组长学号组员学号…
-
数据挖掘大作业结果分析报告
数据仓库期末作业数据挖掘分析报告某药店常用药品信息数据挖掘解决方案作者刘金龙学院计算机信息管理学院专业计算机科学与技术年级20xx…
-
数据挖掘报告
研究方向前沿读书报告数据挖掘技术的算法与应用目录第一章数据仓库511概论512数据仓库体系结构613数据仓库规划设计与开发7131…
-
数据挖掘实验报告4
甘肃政法学院本科生实验报告四姓名贾燚学院计算机科学学院专业信息管理与信息系统班级10级信管班实验课程名称数据仓库与数据挖掘实验日期…
-
数据挖掘实验报告
数据挖掘实验报告一实验名称有线电视服务销售CampR树二实验目的1学习和了解数据挖掘的基础知识学会使用SPSSClementine…