应用时间序列分析实训报告
《应用时间序列分析》
实训报告
 实训项目名称 非平稳时间序列模型的建立
实训项目名称 非平稳时间序列模型的建立
 实 训 时 间 20##年12月16日
实 训 时 间 20##年12月16日
实 训 地 点 实验楼308
班 级 计科1001班
学 号
姓 名
《应用时间序列分析》
实训 (实践 ) 报告
实训名称 平稳时间序列模型的建立
一、 实训目的
本次实验是一个综合试验,通过自己选定问题,收集数据,确定研究方法,建立合适模型,解决实际问题,增强学生动手能力,提高学生综合分析的能力。
二、 实训内容
学生根据自己喜好,选定一个实际问题,确定指标,收集相关数据,利用所学时间序列分析方法队进行研究,建立时间序列模型,揭示其研究对象内部的规律,并对未来进行预测。并写出分析报告。具体实验内容如下:
1 确定研究问题
2 收集数据
3 建立合适模型
1.ARIMA模型建模前的准备:判断序列是否平稳.
①通过序列自相关图、趋势图等进行判断
②若序列不平稳:
均值非平稳序列通过差分变换转换为平稳
方差非平稳序列通过对数变换等转化为平稳序列
③模型平稳化以后,将序列零均值化
2.模型识别
主要通过序列的自相关函数、偏自相关函数表现的特征,进行初步的模型识别
3.模型参数估计
①在Eviews中估计ARMA模型的方法
②估计模型以后要能写出模型的形式(差分方程形式和用B算子表示的形式)
4.模型的诊断检验
①根据模型残差是不是白噪声来判断模型是否为适应性模型
②能根据输出结果判断模型是否平稳,是否可逆
③若有多个序列是模型的适应性模型,会用合适的方法从这些模型中进行选择,如比较模型的残差方差,AIC,SC等。
5.模型应用
①掌握追溯预测的操作方法
②外推预测的操作方法
四、实训分析与总结
1)输入数据
2)生成时序图

观测序列时序图,可知序列具有线性长期趋势,需要进行一阶差分

观测差分时序图看出并无明显的趋势性或者循环性,得出一阶差分平稳。

由图知,序列一阶自相关显著,序列平稳;Q统计量P值小于0.05,非白噪声;同时偏自相关拖尾、自相关一步截尾,可建立ARIMA(0,1,1)模型。
3)模型参数估计

ARMA模型估计方程:

SBC值为7.013764
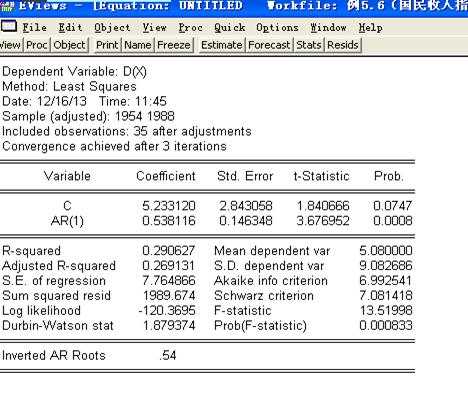
由图知偏自相关,C的值大于0.05,则去掉C,继续建立模型:

ARIMA模型估计方程:
SBC值为7.055671
比较两个模型的SBC 值,建立ARMA模型最优。
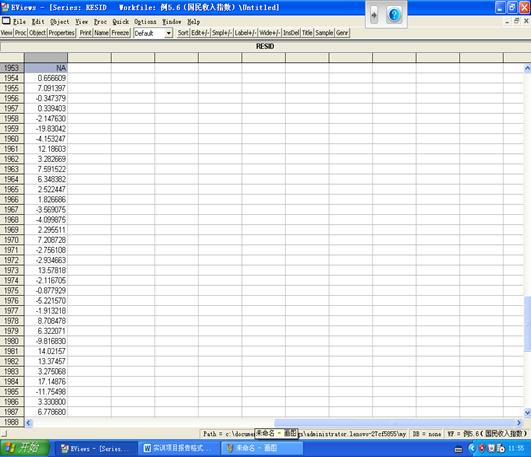
4)模型的诊断检验

残差分析:P值都大于0.05,显著有效,是白噪声序列。
五、实训报告评价与成绩
第二篇:时间序列分析与预测心得报告
時間序列分析與預測心得報告
所謂時間序列分析(Time Series Analysis),乃探討一串按時序列間的關係,並籍由此關係前瞻至未來。時間序列分析模式是計量經濟模式的一般化,可分為狹義及廣義。狹義的時間序列分析是Box and Jankins在1961年所提出的ARIMA模式和後人延伸的ARIMA相關系統;廣義的時間序列除了ARIMA及其相關體系外,還包括趨勢預測、時間序列分解、譜系分析及狀況空間分析等模式。其中,ARIMA轉移函數為高度一般化的模式,其特例簡化為自我迴歸模式及多項式遞延落差模式;而向量ARIMA模式更可簡化為聯立方程式模式。ARIMA、ARIMA轉移函數及向量ARIMA構成了ARIMA系統。
事實上,除了ARIMA模式外,尚有其他可用以預測外生變數之統計模式,但每種模式皆適用於不同的研究特性,如表4.1-1所示。表中,依模式誤差、變數性質、資料特性,可產生六種不同情況的組合,每一組合的預測,均有適當的統計模式可用。
預測模式之適用場合

模式依特性可分為非隨機模式和隨機模式。非隨機模式(Non-stochastic Model)的誤差項背後無隨機過程的假定,亦即時間序列不是由隨機過程產生。典型的非隨機模式為趨勢預測模式。這種模式非常單純,僅用一個數學函數,配適在所觀察到的時間序列上,再用函數的特性,產生未來的預測。趨勢預測模式有誤差項,假定遵循NID(0, s2)。
非隨機模式的特例為確定性模式(Deterministic Model),模式中無誤差項,純為數學結構,不是統計推理的應用,沒有假說檢定,也沒有常態分配的觀念存在。典型的確定性模式,就是時間序列分解模式。這種模式用數學的方式,將時間序列分解成長期趨勢、循環變動、季節變動、不規則變動。預測時,捨棄不規則變動,將其他三個因子分別預測至未來,再組合起來即得。
另一類模式是隨機模式(Stochastic Model),假定所觀察到的時間序列是一個隨機樣本,共有T個觀察值,抽取自我一個隨機過程(Stochastic Process)。隨機模式中,時間序列是樣本,而隨機過程是母體。ARIMA體系內的所有模式,包括ARIMA、ARIMAT、SARIMA、SARIMAT,均屬隨機模式。
變數依特性可分為外生變數與內生變數。外生變數(Exogenous Variable)不受其他變數影響,內生變數(Endogenous Variable)是會受其他變數的影響。奱數之外生性或內生性,不是與生具來的本質,而要視在研究架構中所扮演的角色。例如,行銷研究中,單位需求受國民所得的影響,國民所得為外生變數;而在經濟研究中,國民所得受消費、投資、政府支出的影響,故國民所得為內生變數。同樣是國民所得,在兩個研究領域中所扮演的角色,郤截然不同。不過,這兩個研究郤彼此相關,行銷研究預測市場需求時,要先預測經濟環境,而經濟環境的預測,是由經濟研究完成的。
資料依特性可分為連續性資料(Consecutive Data)與季節性資料(Seasonal Data),連續性資料不會定期循環,季節性資料則會定期循環。年資料因不會產生定期循環,大多為連續性資料。而季資料、月資料,是否為季節性資料,就要視是否會產生定期循環而異了。例如,可樂銷售量月資料,會產生夏天高、冬天低的定期循環,屬季節性資料;而利率月資料,不會有定期循環的情況產生,屬連續性資料。
ARIMA有狹義與廣義之分。狹義指ARIMA模式。而廣義則指ARIMA體系,包括四個模式,分別為ARIMA模式、ARIMAT模式、SARIMA模式、SARIMAT模式。僅提ARIMA,未特別指明是哪一個模式的話,基本上,視為廣義的ARIMA,泛指四個模式中的一個。
茲以每人牛奶用量預測為例,說明ARIMA體系的應用。長期預測適合以年資料為基礎,如以過30年資料預測未來5年,解釋變數為國民所得,早期所得低時,消費者喝不起牛奶,量會較少。短期預測適合以月資料為基礎,如以過去36個月資料預測未來3個月,解釋變數則為月均溫,天氣熱時,每人用量會較多。
ARIMA與AIRMAT適用於以年資料產生長期預測。ARIMA模式適用於外生變數、連續性資料之預測,可用以預測國民所得。ARIMAT為ARIMA轉移函數(Transfer Function),適用於內生變數、連續性資料之預測,可用以估計每人用量與國民所得之轉移函數,並將國民所得預測代入轉移函數,產生每人用量預測。
SARIMA與SAIRMAT適用於以月資料產生短期預測。SARIMA模式為季節性ARIMA(Seasonal ARIMA)模式,適用於外生變數、季節性資料之預測,可用以預測月均溫。SARIMAT為季節性ARIMA轉移函數(Seasonal ARIMA Transfer Function)模式,適用於內生變數、季節性資料之預測,可用以估計每人用量與月均溫之轉移函數,並將月均溫預測代入轉移函數,產生每人用量預測。
模型設定與估計:
ARIMA (p,d,q)模式,如下所示:

ARIMA(p,d,q)模式可改寫為:

d之辨認
d是序列之差分階數,通常可藉由序列之趨勢圖加以判定,若趨勢為水平,則設定d=0;若趨勢為直線,則不論是直線上升或直線下降,皆設定d=1;若趨勢為二次式,皆設定d=2。
在辨認d值之後,應對原始序列進行差分d階之工作。將差分後之序列(ÑdYt)減去差分後之均值(m),即產生一差分後之新序列yt,亦即yt=ÑdYt-μ。差分之目的,就是在使新序列yt滿足定態之要求。
(p,q)之辨認
模式設定之第二個步驟是(p,q)之辨認,依據準則是ACF、PACF等二圖之型式,在辨認(p,q)時,應先檢驗模式是否為單純AR(p)或單純MA(q)模式,若二者皆不是,便可判定模式為ARMA(p,q)。
(p,q)辨認準則

下圖,由於ACF為尾部收斂, PACF皆在一階後切斷,故可辨認出模式為AR(1)。

圖1 單純AR之相關函數
另一方面,根據辨認準則,單純MA之相關函數如圖9.8-3所示。若ACF在q階後切斷, PACF皆為尾部收斂,則可辨認出模式為MA(q)。圖中,由於ACF 在一階後切斷, PACF皆為尾部收斂,故可辨認出模式為MA(1)型式。
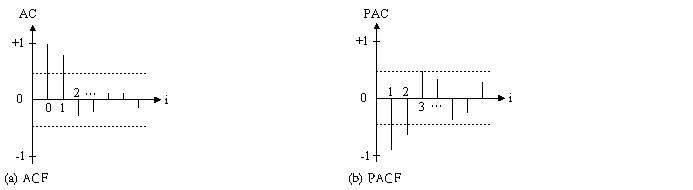
圖2 單純MA之相關函數
然而,若ACF、PACF等二圖都沒有明顯的切斷點時,序列很可能屬於ARMA(p,q)模式。遇到ARMA(p,q)模式時,實務上可用試誤法(Try and Error)。將所有可能的模式分別進行分析,最後由模式診斷來判定何者較為合適。
或者,從差分後之序列的自我相關係數估計值可以觀察出。以自我相關系數估計值落在信賴區間外之最大落差項為q。
為要考驗落差項高於q之自我相關系數是否為零,可用Bartlett計算第k項落差(k>q)之自我相關系數(rk)之變異數,並假設rk為為一平均值為零之常態分配變數,從而建立一個信賴區間。Bartlett公式如下:

自我相關系數在此信賴區間內則模型建立正確。
(二)模型診斷
有關模型設定是否正確可用Q檢驗值來診斷如果模型之設定正確時,檢驗值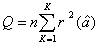 將是卡方分配自由度為K-p-q,即
將是卡方分配自由度為K-p-q,即
 (K-p-q)。其中
(K-p-q)。其中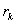
 為誤差項
為誤差項 之自我關係數估計值p和q為AR及MA之級次,K為檢驗配適度時所使用之落差個數。
之自我關係數估計值p和q為AR及MA之級次,K為檢驗配適度時所使用之落差個數。
-
时间序列分析报告
时间序列分析期末课程实践报告课程名称时间序列分析学期20xx20xx1学院专业姓名学号日期20xx0113第一题下表数据是某公司在…
-
时间序列分析实验报告
时间序列分析SAS软件实验报告以我国20xx第一季度到20xx年第一季度国内生产总值数据季节效应模型分析班级统计系统计0姓名学号指…
-
时间序列分析实验报告
课程名称时间序列分析实验项目ARMA模型实验类型验证型学生学号20xx9620xx学生姓名张艳杰学生班级统计学课程教师范英兵实验日…
-
应用时间序列分析实训报告
应用时间序列分析实训报告金融学院应用时间序列分析实训报告实训项目名称非平稳时间序列模型的建立实训时间20xx年12月16日实训地点…
-
时间序列分析报告(8)
湖北工程学院时间序列分析实验报告八实验项目确定性分析趋势分析专业统计学专业班级0123011242姓名学号012301124213…
-
时间序列分析报告
时间序列分析期末课程实践报告课程名称时间序列分析学期20xx20xx1学院专业姓名学号日期20xx0113第一题下表数据是某公司在…
-
时间序列分析实验报告
时间序列分析SAS软件实验报告以我国20xx第一季度到20xx年第一季度国内生产总值数据季节效应模型分析班级统计系统计0姓名学号指…
-
时间序列分析实验报告
课程名称时间序列分析实验项目ARMA模型实验类型验证型学生学号20xx9620xx学生姓名张艳杰学生班级统计学课程教师范英兵实验日…
-
时间序列分析报告(8)
湖北工程学院时间序列分析实验报告八实验项目确定性分析趋势分析专业统计学专业班级0123011242姓名学号012301124213…
-
时间序列分析报告5
时间序列分析课程实验报告时间序列分析课程实验报告时间序列分析课程实验报告一上机练习P228SAS系统中的ARIMA过程可以支持单位…