数据结构(C语言版)实验报告
数据结构(C语言版) 实验报告
姓名:
学号:
指导老师:
实验1
实验题目:单链表的插入和删除
实验目的:
了解和掌握线性表的逻辑结构和链式存储结构,掌握单链表的基本算法及相关的时间性能分析。
实验要求:
建立一个数据域定义为字符串的单链表,在链表中不允许有重复的字符串;根据输入的字符串,先找到相应的结点,后删除之。
实验主要步骤:
1、分析、理解给出的示例程序。
2、调试程序,并设计输入数据(如:bat,cat,eat,fat,hat,jat,lat,mat,#),测试程序的如下功能:不允许重复字符串的插入;根据输入的字符串,找到相应的结点并删除。
3、修改程序:
(1) 增加插入结点的功能。
(2) 将建立链表的方法改为头插入法。
程序代码:
#include"stdio.h"
#include"string.h"
#include"stdlib.h"
#include"ctype.h"
typedef struct node //定义结点
{
char data[10]; //结点的数据域为字符串
struct node *next; //结点的指针域
}ListNode;
typedef ListNode * LinkList; // 自定义LinkList单链表类型
LinkList CreatListR1(); //函数,用尾插入法建立带头结点的单链表
LinkList CreatList(void); //函数,用头插入法建立带头结点的单链表
ListNode *LocateNode(); //函数,按值查找结点
void DeleteList(); //函数,删除指定值的结点
void printlist(); //函数,打印链表中的所有值
void DeleteAll(); //函数,删除所有结点,释放内存
ListNode * AddNode(); //修改程序:增加节点。用头插法,返回头指针
//==========主函数==============
void main()
{
char ch[10],num[5];
LinkList head;
head=CreatList(); //用头插入法建立单链表,返回头指针
printlist(head); //遍历链表输出其值
printf(" Delete node (y/n):"); //输入"y"或"n"去选择是否删除结点
scanf("%s",num);
if(strcmp(num,"y")==0 || strcmp(num,"Y")==0){
printf("Please input Delete_data:");
scanf("%s",ch); //输入要删除的字符串
DeleteList(head,ch);
printlist(head);
}
printf(" Add node ? (y/n):"); //输入"y"或"n"去选择是否增加结点
scanf("%s",num);
if(strcmp(num,"y")==0 || strcmp(num,"Y")==0)
{
head=AddNode(head);
}
printlist(head);
DeleteAll(head); //删除所有结点,释放内存
}
//==========用尾插入法建立带头结点的单链表===========
LinkList CreatListR1(void)
{
char ch[10];
LinkList head=(LinkList)malloc(sizeof(ListNode)); //生成头结点
ListNode *s,*r,*pp;
r=head;
r->next=NULL;
printf("Input # to end "); //输入"#"代表输入结束
printf("\nPlease input Node_data:");
scanf("%s",ch); //输入各结点的字符串
while(strcmp(ch,"#")!=0) {
pp=LocateNode(head,ch); //按值查找结点,返回结点指针
if(pp==NULL) { //没有重复的字符串,插入到链表中
s=(ListNode *)malloc(sizeof(ListNode));
strcpy(s->data,ch);
r->next=s;
r=s;
r->next=NULL;
}
printf("Input # to end ");
printf("Please input Node_data:");
scanf("%s",ch);
}
return head; //返回头指针
}
//==========用头插入法建立带头结点的单链表===========
LinkList CreatList(void)
{
char ch[100];
LinkList head,p;
head=(LinkList)malloc(sizeof(ListNode));
head->next=NULL;
while(1)
{
printf("Input # to end ");
printf("Please input Node_data:");
scanf("%s",ch);
if(strcmp(ch,"#"))
{
if(LocateNode(head,ch)==NULL)
{
strcpy(head->data,ch);
p=(LinkList)malloc(sizeof(ListNode));
p->next=head;
head=p;
}
}
else
break;
}
return head;
}
//==========按值查找结点,找到则返回该结点的位置,否则返回NULL==========
ListNode *LocateNode(LinkList head, char *key)
{
ListNode *p=head->next; //从开始结点比较
while(p!=NULL && strcmp(p->data,key)!=0) //直到p为NULL或p->data为key止
p=p->next; //扫描下一个结点
return p; //若p=NULL则查找失败,否则p指向找到的值为key的结点
}
//==========修改程序:增加节点=======
ListNode * AddNode(LinkList head)
{
char ch[10];
ListNode *s,*pp;
printf("\nPlease input a New Node_data:");
scanf("%s",ch); //输入各结点的字符串
pp=LocateNode(head,ch); //按值查找结点,返回结点指针
printf("ok2\n");
if(pp==NULL) { //没有重复的字符串,插入到链表中
s=(ListNode *)malloc(sizeof(ListNode));
strcpy(s->data,ch);
printf("ok3\n");
s->next=head->next;
head->next=s;
}
return head;
}
//==========删除带头结点的单链表中的指定结点=======
void DeleteList(LinkList head,char *key)
{
ListNode *p,*r,*q=head;
p=LocateNode(head,key); //按key值查找结点的
if(p==NULL ) { //若没有找到结点,退出
printf("position error");
exit(0);
}
while(q->next!=p) //p为要删除的结点,q为p的前结点
q=q->next;
r=q->next;
q->next=r->next;
free(r); //释放结点
}
//===========打印链表=======
void printlist(LinkList head)
{
ListNode *p=head->next; //从开始结点打印
while(p){
printf("%s, ",p->data);
p=p->next;
}
printf("\n");
}
//==========删除所有结点,释放空间===========
void DeleteAll(LinkList head)
{
ListNode *p=head,*r;
while(p->next){
r=p->next;
free(p);
p=r;
}
free(p);
}
实验结果:
Input # to end Please input Node_data:bat
Input # to end Please input Node_data:cat
Input # to end Please input Node_data:eat
Input # to end Please input Node_data:fat
Input # to end Please input Node_data:hat
Input # to end Please input Node_data:jat
Input # to end Please input Node_data:lat
Input # to end Please input Node_data:mat
Input # to end Please input Node_data:#
mat, lat, jat, hat, fat, eat, cat, bat,
Delete node (y/n):y
Please input Delete_data:hat
mat, lat, jat, fat, eat, cat, bat,
Insert node (y/n):y
Please input Insert_data:put
position :5
mat, lat, jat, fat, eat, put, cat, bat,
请按任意键继续. . .
示意图:
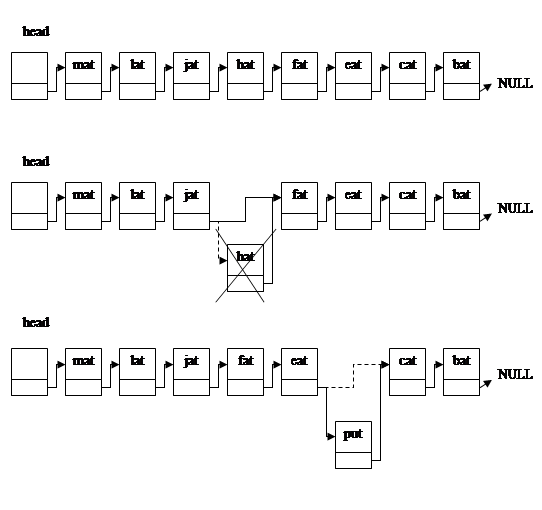
心得体会:
本次实验使我对链表更加了解,对链表的一些基本操作也更加熟练了。另外实验指导书上给出的代码是有一些问题的,这使我们认识到实验过程中不能想当然的直接编译执行,应当在阅读并完全理解代码的基础上再执行,这才是实验的意义所在。
实验2
实验题目:二叉树操作设计和实现
实验目的:
掌握二叉树的定义、性质及存储方式,各种遍历算法。
实验要求:
采用二叉树链表作为存储结构,完成二叉树的建立,先序、中序和后序以及按层次遍历的操作,求所有叶子及结点总数的操作。
实验主要步骤:
1、分析、理解程序。
2、调试程序,设计一棵二叉树,输入完全二叉树的先序序列,用#代表虚结点(空指针),如ABD###CE##F##,建立二叉树,求出先序、中序和后序以及按层次遍历序列,求所有叶子及结点总数。
实验代码
#include"stdio.h"
#include"stdlib.h"
#include"string.h"
#define Max 20 //结点的最大个数
typedef struct node{
char data;
struct node *lchild,*rchild;
}BinTNode; //自定义二叉树的结点类型
typedef BinTNode *BinTree; //定义二叉树的指针
int NodeNum,leaf; //NodeNum为结点数,leaf为叶子数
//==========基于先序遍历算法创建二叉树==============
//=====要求输入先序序列,其中加入虚结点"#"以示空指针的位置==========
BinTree CreatBinTree(void)
{
BinTree T;
char ch;
if((ch=getchar())=='#')
return(NULL); //读入#,返回空指针
else{
T= (BinTNode *)malloc(sizeof(BinTNode)); //生成结点
T->data=ch;
T->lchild=CreatBinTree(); //构造左子树
T->rchild=CreatBinTree(); //构造右子树
return(T);
}
}
//========NLR 先序遍历=============
void Preorder(BinTree T)
{
if(T) {
printf("%c",T->data); //访问结点
Preorder(T->lchild); //先序遍历左子树
Preorder(T->rchild); //先序遍历右子树
}
}
//========LNR 中序遍历===============
void Inorder(BinTree T)
{
if(T) {
Inorder(T->lchild); //中序遍历左子树
printf("%c",T->data); //访问结点
Inorder(T->rchild); //中序遍历右子树
}
}
//==========LRN 后序遍历============
void Postorder(BinTree T)
{
if(T) {
Postorder(T->lchild); //后序遍历左子树
Postorder(T->rchild); //后序遍历右子树
printf("%c",T->data); //访问结点
}
}
//=====采用后序遍历求二叉树的深度、结点数及叶子数的递归算法========
int TreeDepth(BinTree T)
{
int hl,hr,max;
if(T){
hl=TreeDepth(T->lchild); //求左深度
hr=TreeDepth(T->rchild); //求右深度
max=hl>hr? hl:hr; //取左右深度的最大值
NodeNum=NodeNum+1; //求结点数
if(hl==0&&hr==0) leaf=leaf+1; //若左右深度为0,即为叶子。
return(max+1);
}
else return(0);
}
//====利用"先进先出"(FIFO)队列,按层次遍历二叉树==========
void Levelorder(BinTree T)
{
int front=0,rear=1;
BinTNode *cq[Max],*p; //定义结点的指针数组cq
cq[1]=T; //根入队
while(front!=rear)
{
front=(front+1)%NodeNum;
p=cq[front]; //出队
printf("%c",p->data); //出队,输出结点的值
if(p->lchild!=NULL){
rear=(rear+1)%NodeNum;
cq[rear]=p->lchild; //左子树入队
}
if(p->rchild!=NULL){
rear=(rear+1)%NodeNum;
cq[rear]=p->rchild; //右子树入队
}
}
}
//====数叶子节点个数==========
int countleaf(BinTree T)
{
int hl,hr;
if(T){
hl=countleaf(T->lchild);
hr=countleaf(T->rchild);
if(hl==0&&hr==0) //若左右深度为0,即为叶子。
return(1);
else return hl+hr;
}
else return 0;
}
//==========主函数=================
void main()
{
BinTree root;
char i;
int depth;
printf("\n");
printf("Creat Bin_Tree; Input preorder:"); //输入完全二叉树的先序序列,
// 用#代表虚结点,如ABD###CE##F##
root=CreatBinTree(); //创建二叉树,返回根结点
do { //从菜单中选择遍历方式,输入序号。
printf("\t********** select ************\n");
printf("\t1: Preorder Traversal\n");
printf("\t2: Iorder Traversal\n");
printf("\t3: Postorder traversal\n");
printf("\t4: PostTreeDepth,Node number,Leaf number\n");
printf("\t5: Level Depth\n"); //按层次遍历之前,先选择4,求出该树的结点数。
printf("\t0: Exit\n");
printf("\t*******************************\n");
fflush(stdin);
scanf("%c",&i); //输入菜单序号(0-5)
switch (i-'0'){
case 1: printf("Print Bin_tree Preorder: ");
Preorder(root); //先序遍历
break;
case 2: printf("Print Bin_Tree Inorder: ");
Inorder(root); //中序遍历
break;
case 3: printf("Print Bin_Tree Postorder: ");
Postorder(root); //后序遍历
break;
case 4:
depth=TreeDepth(root); //求树的深度及叶子数
printf("BinTree Depth=%d BinTree Node number=%d",depth,NodeNum);
printf(" BinTree Leaf number=%d",countleaf(root));
break;
case 5: printf("LevePrint Bin_Tree: ");
Levelorder(root); //按层次遍历
break;
default: exit(1);
}
printf("\n");
} while(i!=0);
}
实验结果:
Creat Bin_Tree; Input preorder:ABD###CE##F##
********** select ************
1: Preorder Traversal
2: Iorder Traversal
3: Postorder traversal
4: PostTreeDepth,Node number,Leaf number
5: Level Depth
0: Exit
*******************************
1
Print Bin_tree Preorder: ABDCEF
2
Print Bin_Tree Inorder: DBAECF
3
Print Bin_Tree Postorder: DBEFCA
4
BinTree Depth=3 BinTree Node number=6 BinTree Leaf number=3
5
LevePrint Bin_Tree: ABCDEF
0
Press any key to continue
二叉树示意图
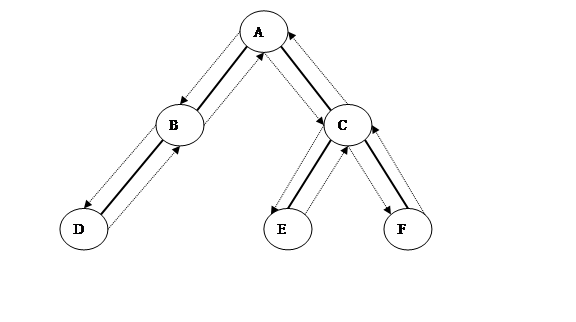
心得体会:
这次实验加深了我对二叉树的印象,更加熟悉对二叉树的遍历。了解了二叉树的存储方式。通过这次的实验,让我更加熟悉对二叉树的一系列操作,和层次遍历。
实验3
实验题目:图的遍历操作
实验目的:
掌握有向图和无向图的概念;掌握邻接矩阵和邻接链表建立图的存储结构;掌握DFS及BFS对图的遍历操作;了解图结构在人工智能、工程等领域的广泛应用。
实验要求:
采用邻接矩阵和邻接链表作为图的存储结构,完成有向图和无向图的DFS和BFS操作。
实验主要步骤:
设计一个有向图和一个无向图,任选一种存储结构,完成有向图和无向图的DFS(深度优先遍历)和BFS(广度优先遍历)的操作。
1. 邻接矩阵作为存储结构
#include"stdio.h"
#include"stdlib.h"
#define MaxVertexNum 100 //定义最大顶点数
typedef struct{
char vexs[MaxVertexNum]; //顶点表
int edges[MaxVertexNum][MaxVertexNum]; //邻接矩阵,可看作边表
int n,e; //图中的顶点数n和边数e
}MGraph; //用邻接矩阵表示的图的类型
//=========建立邻接矩阵=======
void CreatMGraph(MGraph *G)
{
int i,j,k;
char a;
printf("Input VertexNum(n) and EdgesNum(e): ");
scanf("%d,%d",&G->n,&G->e); //输入顶点数和边数
scanf("%c",&a);
printf("Input Vertex string:");
for(i=0;i<G->n;i++)
{
scanf("%c",&a);
G->vexs[i]=a; //读入顶点信息,建立顶点表
}
for(i=0;i<G->n;i++)
for(j=0;j<G->n;j++)
G->edges[i][j]=0; //初始化邻接矩阵
printf("Input edges,Creat Adjacency Matrix\n");
for(k=0;k<G->e;k++) { //读入e条边,建立邻接矩阵
scanf("%d%d",&i,&j); //输入边(Vi,Vj)的顶点序号
G->edges[i][j]=1;
G->edges[j][i]=1; //若为无向图,矩阵为对称矩阵;若建立有向图,去掉该条语句
}
}
//=========定义标志向量,为全局变量=======
typedef enum{FALSE,TRUE} Boolean;
Boolean visited[MaxVertexNum];
//========DFS:深度优先遍历的递归算法======
void DFSM(MGraph *G,int i)
{ //以Vi为出发点对邻接矩阵表示的图G进行DFS搜索,邻接矩阵是0,1矩阵
int j;
printf("%c",G->vexs[i]); //访问顶点Vi
visited[i]=TRUE; //置已访问标志
for(j=0;j<G->n;j++) //依次搜索Vi的邻接点
if(G->edges[i][j]==1 && ! visited[j])
DFSM(G,j); //(Vi,Vj)∈E,且Vj未访问过,故Vj为新出发点
}
void DFS(MGraph *G)
{
int i;
for(i=0;i<G->n;i++)
visited[i]=FALSE; //标志向量初始化
for(i=0;i<G->n;i++)
if(!visited[i]) //Vi未访问过
DFSM(G,i); //以Vi为源点开始DFS搜索
}
//===========BFS:广度优先遍历=======
void BFS(MGraph *G,int k)
{ //以Vk为源点对用邻接矩阵表示的图G进行广度优先搜索
int i,j,f=0,r=0;
int cq[MaxVertexNum]; //定义队列
for(i=0;i<G->n;i++)
visited[i]=FALSE; //标志向量初始化
for(i=0;i<G->n;i++)
cq[i]=-1; //队列初始化
printf("%c",G->vexs[k]); //访问源点Vk
visited[k]=TRUE;
cq[r]=k; //Vk已访问,将其入队。注意,实际上是将其序号入队
while(cq[f]!=-1) { //队非空则执行
i=cq[f]; f=f+1; //Vf出队
for(j=0;j<G->n;j++) //依次Vi的邻接点Vj
if(G->edges[i][j]==1 && !visited[j]) { //Vj未访问
printf("%c",G->vexs[j]); //访问Vj
visited[j]=TRUE;
r=r+1; cq[r]=j; //访问过Vj入队
}
}
}
//==========main=====
void main()
{
int i;
MGraph *G;
G=(MGraph *)malloc(sizeof(MGraph)); //为图G申请内存空间
CreatMGraph(G); //建立邻接矩阵
printf("Print Graph DFS: ");
DFS(G); //深度优先遍历
printf("\n");
printf("Print Graph BFS: ");
BFS(G,3); //以序号为3的顶点开始广度优先遍历
printf("\n");
}
2. 邻接链表作为存储结构
#include"stdio.h"
#include"stdlib.h"
#define MaxVertexNum 50 //定义最大顶点数
typedef struct node{ //边表结点
int adjvex; //邻接点域
struct node *next; //链域
}EdgeNode;
typedef struct vnode{ //顶点表结点
char vertex; //顶点域
EdgeNode *firstedge; //边表头指针
}VertexNode;
typedef VertexNode AdjList[MaxVertexNum]; //AdjList是邻接表类型
typedef struct {
AdjList adjlist; //邻接表
int n,e; //图中当前顶点数和边数
} ALGraph; //图类型
//=========建立图的邻接表=======
void CreatALGraph(ALGraph *G)
{
int i,j,k;
char a;
EdgeNode *s; //定义边表结点
printf("Input VertexNum(n) and EdgesNum(e): ");
scanf("%d,%d",&G->n,&G->e); //读入顶点数和边数
scanf("%c",&a);
printf("Input Vertex string:");
for(i=0;i<G->n;i++) //建立边表
{
scanf("%c",&a);
G->adjlist[i].vertex=a; //读入顶点信息
G->adjlist[i].firstedge=NULL; //边表置为空表
}
printf("Input edges,Creat Adjacency List\n");
for(k=0;k<G->e;k++) { //建立边表
scanf("%d%d",&i,&j); //读入边(Vi,Vj)的顶点对序号
s=(EdgeNode *)malloc(sizeof(EdgeNode)); //生成边表结点
s->adjvex=j; //邻接点序号为j
s->next=G->adjlist[i].firstedge;
G->adjlist[i].firstedge=s; //将新结点*S插入顶点Vi的边表头部
s=(EdgeNode *)malloc(sizeof(EdgeNode));
s->adjvex=i; //邻接点序号为i
s->next=G->adjlist[j].firstedge;
G->adjlist[j].firstedge=s; //将新结点*S插入顶点Vj的边表头部
}
}
//=========定义标志向量,为全局变量=======
typedef enum{FALSE,TRUE} Boolean;
Boolean visited[MaxVertexNum];
//========DFS:深度优先遍历的递归算法======
void DFSM(ALGraph *G,int i)
{ //以Vi为出发点对邻接链表表示的图G进行DFS搜索
EdgeNode *p;
printf("%c",G->adjlist[i].vertex); //访问顶点Vi
visited[i]=TRUE; //标记Vi已访问
p=G->adjlist[i].firstedge; //取Vi边表的头指针
while(p) { //依次搜索Vi的邻接点Vj,这里j=p->adjvex
if(! visited[p->adjvex]) //若Vj尚未被访问
DFSM(G,p->adjvex); //则以Vj为出发点向纵深搜索
p=p->next; //找Vi的下一个邻接点
}
}
void DFS(ALGraph *G)
{
int i;
for(i=0;i<G->n;i++)
visited[i]=FALSE; //标志向量初始化
for(i=0;i<G->n;i++)
if(!visited[i]) //Vi未访问过
DFSM(G,i); //以Vi为源点开始DFS搜索
}
//==========BFS:广度优先遍历=========
void BFS(ALGraph *G,int k)
{ //以Vk为源点对用邻接链表表示的图G进行广度优先搜索
int i,f=0,r=0;
EdgeNode *p;
int cq[MaxVertexNum]; //定义FIFO队列
for(i=0;i<G->n;i++)
visited[i]=FALSE; //标志向量初始化
for(i=0;i<=G->n;i++)
cq[i]=-1; //初始化标志向量
printf("%c",G->adjlist[k].vertex); //访问源点Vk
visited[k]=TRUE;
cq[r]=k; //Vk已访问,将其入队。注意,实际上是将其序号入队
while(cq[f]!=-1) { 队列非空则执行
i=cq[f]; f=f+1; //Vi出队
p=G->adjlist[i].firstedge; //取Vi的边表头指针
while(p) { //依次搜索Vi的邻接点Vj(令p->adjvex=j)
if(!visited[p->adjvex]) { //若Vj未访问过
printf("%c",G->adjlist[p->adjvex].vertex); //访问Vj
visited[p->adjvex]=TRUE;
r=r+1; cq[r]=p->adjvex; //访问过的Vj入队
}
p=p->next; //找Vi的下一个邻接点
}
}//endwhile
}
//==========主函数===========
void main()
{
int i;
ALGraph *G;
G=(ALGraph *)malloc(sizeof(ALGraph));
CreatALGraph(G);
printf("Print Graph DFS: ");
DFS(G);
printf("\n");
printf("Print Graph BFS: ");
BFS(G,3);
printf("\n");
}
实验结果:
1. 邻接矩阵作为存储结构
执行顺序:
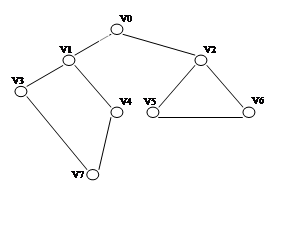 Input VertexNum(n) and EdgesNum(e): 8,9
Input VertexNum(n) and EdgesNum(e): 8,9
Input Vertex string: 01234567
Input edges,Creat Adjacency Matrix
0 1
0 2
1 3
1 4
2 5
2 6
3 7
4 7
5 6
Print Graph DFS: 01374256
Print Graph BFS: 31704256
2. 邻接链表作为存储结构
执行顺序:
Input VertexNum(n) and EdgesNum(e): 8,9
Input Vertex string: 01234567
 Input edges,Creat Adjacency List
Input edges,Creat Adjacency List
0 1
0 2
1 3
1 4
2 5
2 6
3 7
4 7
5 6
Print Graph DFS: 02651473
Print Graph BFS: 37140265
心得体会:
这次实验较以前的实验难度加大,必须先理解深度优先和广度优先两种遍历思路,和数据结构中队列的基本操作,才能看懂理解代码。同时图这种数据结构对抽象的能力要求非常高,代码不容易看懂,排错也比较麻烦,应该多加练习,才能掌握。
实验4
实验题目:排序
实验目的:
掌握各种排序方法的基本思想、排序过程、算法实现,能进行时间和空间性能的分析,根据实际问题的特点和要求选择合适的排序方法。
实验要求:
实现直接排序、冒泡、直接选择、快速、堆、归并排序算法。比较各种算法的运行速度。
实验主要步骤:
实验代码
#include"stdio.h"
#include"stdlib.h"
#define Max 100 //假设文件长度
typedef struct{ //定义记录类型
int key; //关键字项
}RecType;
typedef RecType SeqList[Max+1]; //SeqList为顺序表,表中第0个元素作为哨兵
int n; //顺序表实际的长度
//==========直接插入排序法======
void InsertSort(SeqList R)
{ //对顺序表R中的记录R[1‥n]按递增序进行插入排序
int i,j;
for(i=2;i<=n;i++) //依次插入R[2],……,R[n]
if(R[i].key<R[i-1].key){ //若R[i].key大于等于有序区中所有的keys,则R[i]留在原位
R[0]=R[i];j=i-1; //R[0]是R[i]的副本
do
{ //从右向左在有序区R[1‥i-1]中查找R[i] 的位置
R[j+1]=R[j]; //将关键字大于R[i].key的记录后移
j--;
}
while(R[0].key<R[j].key); //当R[i].key≥R[j].key 是终止
R[j+1]=R[0]; //R[i]插入到正确的位置上
}//endif
}
//==========冒泡排序=======
typedef enum {FALSE,TRUE} Boolean; //FALSE为0,TRUE为1
void BubbleSort(SeqList R) { //自下向上扫描对R做冒泡排序
int i,j; Boolean exchange; //交换标志
for(i=1;i<n;i++) { //最多做n-1趟排序
exchange=FALSE; //本趟排序开始前,交换标志应为假
for(j=n-1;j>=i;j--) //对当前无序区R[i‥n] 自下向上扫描
if(R[j+1].key<R[j].key){ //两两比较,满足条件交换记录
R[0]=R[j+1]; //R[0]不是哨兵,仅做暂存单元
R[j+1]=R[j];
R[j]=R[0];
exchange=TRUE; //发生了交换,故将交换标志置为真
}
if(! exchange) //本趟排序未发生交换,提前终止算法
return;
}// endfor(为循环)
}
//1.========一次划分函数=====
int Partition(SeqList R,int i,int j)
{ // 对R[i‥j]做一次划分,并返回基准记录的位置
RecType pivot=R[i]; //用第一个记录作为基准
while(i<j) { //从区间两端交替向中间扫描,直到i=j
while(i<j &&R[j].key>=pivot.key) //基准记录pivot相当与在位置i上
j--; //从右向左扫描,查找第一个关键字小于pivot.key的记录R[j]
if(i<j) //若找到的R[j].key < pivot.key,则
R[i++]=R[j]; //交换R[i]和R[j],交换后i指针加1
while(i<j &&R[i].key<=pivot.key) //基准记录pivot相当与在位置j上
i++; //从左向右扫描,查找第一个关键字小于pivot.key的记录R[i]
if(i<j) //若找到的R[i].key > pivot.key,则
R[j--]=R[i]; //交换R[i]和R[j],交换后j指针减1
}
R[i]=pivot; //此时,i=j,基准记录已被最后定位
return i; //返回基准记录的位置
}
//2.=====快速排序===========
void QuickSort(SeqList R,int low,int high)
{ //R[low..high]快速排序
int pivotpos; //划分后基准记录的位置
if(low<high) { //仅当区间长度大于1时才排序
pivotpos=Partition(R,low,high); //对R[low..high]做一次划分,得到基准记录的位置
QuickSort(R,low,pivotpos-1); //对左区间递归排序
QuickSort(R,pivotpos+1,high); //对右区间递归排序
}
}
//======直接选择排序========
void SelectSort(SeqList R)
{
int i,j,k;
for(i=1;i<n;i++){ //做第i趟排序(1≤i≤n-1)
k=i;
for(j=i+1;j<=n;j++) //在当前无序区R[i‥n]中选key最小的记录R[k]
if(R[j].key<R[k].key)
k=j; //k记下目前找到的最小关键字所在的位置
if(k!=i) { // //交换R[i]和R[k]
R[0]=R[i];
R[i]=R[k];
R[k]=R[0];
} //endif
} //endfor
}
//==========大根堆调整函数=======
void Heapify( SeqList R,int low,int high)
{ // 将R[low..high]调整为大根堆,除R[low]外,其余结点均满足堆性质
int large; //large指向调整结点的左、右孩子结点中关键字较大者
RecType temp=R[low]; //暂存调整结点
for(large=2*low; large<=high;large*=2){ //R[low]是当前调整结点
//若large>high,则表示R[low]是叶子,调整结束;否则先令large指向R[low]的左孩子
if(large<high && R[large].key<R[large+1].key)
large++; //若R[low]的右孩子存在且关键字大于左兄弟,则令large指向它
//现在R[large]是调整结点R[low]的左右孩子结点中关键字较大者
if(temp.key>=R[large].key) //temp始终对应R[low]
break; //当前调整结点不小于其孩子结点的关键字,结束调整
R[low]=R[large]; //相当于交换了R[low]和R[large]
low=large; //令low指向新的调整结点,相当于temp已筛下到large的位置
}
R[low]=temp; //将被调整结点放入最终位置上
}
//==========构造大根堆==========
void BuildHeap(SeqList R)
{ //将初始文件R[1..n]构造为堆
int i;
for(i=n/2;i>0;i--)
Heapify(R,i,n); //将R[i..n]调整为大根堆
}
//==========堆排序===========
void HeapSort(SeqList R)
{ //对R[1..n]进行堆排序,不妨用R[0]做暂存单元
int i;
BuildHeap(R); //将R[1..n]构造为初始大根堆
for(i=n;i>1;i--){ //对当前无序区R[1..i]进行堆排序,共做n-1趟。
R[0]=R[1]; R[1]=R[i];R[i]=R[0]; //将堆顶和堆中最后一个记录交换
Heapify(R,1,i-1); //将R[1..i-1]重新调整为堆,仅有R[1]可能违反堆性质。
}
}
//=====将两个有序的子序列R[low..m]和R[m+1..high]归并成有序的序列R[low..high]==
void Merge(SeqList R,int low,int m,int high)
{
int i=low,j=m+1,p=0; //置初始值
RecType *R1; //R1为局部量
R1=(RecType *)malloc((high-low+1)*sizeof(RecType)); //申请空间
while(i<=m && j<=high) //两个子序列非空时取其小者输出到R1[p]上
R1[p++]=(R[i].key<=R[j].key)? R[i++]:R[j++];
while(i<=m) //若第一个子序列非空,则复制剩余记录到R1
R1[p++]=R[i++];
while(j<=high) //若第二个子序列非空,则复制剩余记录到R1中
R1[p++]=R[j++];
for(p=0,i=low;i<=high;p++,i++)
R[i]=R1[p]; //归并完成后将结果复制回R[low..high]
}
//=========对R[1..n]做一趟归并排序========
void MergePass(SeqList R,int length)
{
int i;
for(i=1;i+2*length-1<=n;i=i+2*length)
Merge(R,i,i+length-1,i+2*length-1); //归并长度为length的两个相邻的子序列
if(i+length-1<n) //尚有一个子序列,其中后一个长度小于length
Merge(R,i,i+length-1,n); //归并最后两个子序列
//注意:若i≤n且i+length-1≥n时,则剩余一个子序列轮空,无须归并
}
//========== 自底向上对R[1..n]做二路归并排序===============
void MergeSort(SeqList R)
{
int length;
for(length=1;length<n;length*=2) //做[lgn]趟排序
MergePass(R,length); //有序长度≥n时终止
}
//==========输入顺序表========
void input_int(SeqList R)
{
int i;
printf("Please input num(int):");
scanf("%d",&n);
printf("Plase input %d integer:",n);
for(i=1;i<=n;i++)
scanf("%d",&R[i].key);
}
//==========输出顺序表========
void output_int(SeqList R)
{
int i;
for(i=1;i<=n;i++)
printf("%4d",R[i].key);
}
//==========主函数======
void main()
{
int i;
SeqList R;
input_int(R);
printf("\t******** Select **********\n");
printf("\t1: Insert Sort\n");
printf("\t2: Bubble Sort\n");
printf("\t3: Quick Sort\n");
printf("\t4: Straight Selection Sort\n");
printf("\t5: Heap Sort\n");
printf("\t6: Merge Sort\n");
printf("\t7: Exit\n");
printf("\t***************************\n");
scanf("%d",&i); //输入整数1-7,选择排序方式
switch (i){
case 1: InsertSort(R); break; //值为1,直接插入排序
case 2: BubbleSort(R); break; //值为2,冒泡法排序
case 3: QuickSort(R,1,n); break; //值为3,快速排序
case 4: SelectSort(R); break; //值为4,直接选择排序
case 5: HeapSort(R); break; //值为5,堆排序
case 6: MergeSort(R); break; //值为6,归并排序
case 7: exit(0); //值为7,结束程序
}
printf("Sort reult:");
output_int(R);
}
实验结果:
Please input num(int):10
Plase input 10 integer:265
301
751
129
937
863
742
694
76
438
******** Select **********
1: Insert Sort
2: Bubble Sort
3: Quick Sort
4: Straight Selection Sort
5: Heap Sort
6: Merge Sort
7: Exit
***************************
1
129, 265, 301, 751, 937, 863, 742, 694, 76, 438,
129, 265, 301, 751, 863, 937, 742, 694, 76, 438,
129, 265, 301, 742, 751, 863, 937, 694, 76, 438,
129, 265, 301, 694, 742, 751, 863, 937, 76, 438,
76, 129, 265, 301, 694, 742, 751, 863, 937, 438,
76, 129, 265, 301, 438, 694, 742, 751, 863, 937,
Sort reult: 76, 129, 265, 301, 438, 694, 742, 751, 863, 937,
2
76,265,301,751,129,937,863,742,694,438,
76,129,265,301,751,438,937,863,742,694,
76,129,265,301,438,751,694,937,863,742,
76,129,265,301,438,694,751,742,937,863,
76,129,265,301,438,694,742,751,863,937,
Sort reult: 76, 129, 265, 301, 438, 694, 742, 751, 863, 937,
3
76,129,265,751,937,863,742,694,301,438,
76,129,265,751,937,863,742,694,301,438,
76,129,265,438,301,694,742,751,863,937,
76,129,265,301,438,694,742,751,863,937,
76,129,265,301,438,694,742,751,863,937,
76,129,265,301,438,694,742,751,863,937,
Sort reult: 76, 129, 265, 301, 438, 694, 742, 751, 863, 937,
4
76,301,751,129,937,863,742,694,265,438,
76,129,751,301,937,863,742,694,265,438,
76,129,265,301,937,863,742,694,751,438,
76,129,265,301,438,863,742,694,751,937,
76,129,265,301,438,694,742,863,751,937,
76,129,265,301,438,694,742,751,863,937,
Sort reult: 76, 129, 265, 301, 438, 694, 742, 751, 863, 937,
5
863,694,751,265,438,301,742,129, 76,937,
751,694,742,265,438,301, 76,129,863,937,
742,694,301,265,438,129, 76,751,863,937,
694,438,301,265, 76,129,742,751,863,937,
438,265,301,129, 76,694,742,751,863,937,
301,265, 76,129,438,694,742,751,863,937,
265,129, 76,301,438,694,742,751,863,937,
129, 76,265,301,438,694,742,751,863,937,
76,129,265,301,438,694,742,751,863,937,
Sort reult: 76, 129, 265, 301, 438, 694, 742, 751, 863, 937,
6
265,301,129,751,863,937,694,742, 76,438,
129,265,301,751,694,742,863,937, 76,438,
129,265,301,694,742,751,863,937, 76,438,
76,129,265,301,438,694,742,751,863,937,
Sort reult: 76, 129, 265, 301, 438, 694, 742, 751, 863, 937,
7
Press any key to continue
运行速度比较:
直接排序 冒泡排序 直接插入 冒泡排序 快速排序
时间复杂度 O(n2),其中快速排序效率较高 其它的效率差不多
堆排序 归并排序
时间复杂度 (nlogn) ,平均效率都很高
心得体会:
此次试验了解了各种排序的基本思想,在分析各种排序的程序代码,对程序进行调试执行等等过程中,锻炼了自己分析数据结构的能力。此次试验然我知道排序的多种方法,也让我知道要编写好一个程序,首先要掌握其基本的思想及算法。
-
数据结构(C语言版)实验报告
数据结构C语言版实验报告姓名学号指导老师实验1实验题目单链表的插入和删除实验目的了解和掌握线性表的逻辑结构和链式存储结构掌握单链表…
-
数据结构实验报告(C语言)(强力推荐)
数据结构实验实验内容和目的掌握几种基本的数据结构集合线性结构树形结构等在求解实际问题中的应用以及培养书写规范文档的技巧学习基本的查…
-
数据结构C语言版实验报告
苏州科技学院数据结构C语言版实验报告专业班级测绘0911学号0920xx5130姓名朱辉实习地点指导教师史守正实验四图一程序设计的…
-
数据结构(C语言版)实验报告
数据结构C语言版实验报告学院计算机科学与技术专业计算机大类强化学号xxx班级xxx姓名xxx指导教师xxx实验1实验题目单链表的插…
-
数据结构(C语言版) 实验报告
数据结构C语言版实验报告专业计算机科学与技术学号班级姓名指导教师青岛大学信息工程学院20xx年10月实验1实验题目顺序存储结构线性…
-
《 数据结构(C语言版) 》课程综合性实验报告
华北科技学院计算机系综合性实验实验报告课程名称数据结构C语言版实验学期20xx至20xx学年第2学期学生所在系部计算机系年级大二专…
-
数据结构实验报告(C语言)(强力推荐)
数据结构实验实验内容和目的掌握几种基本的数据结构集合线性结构树形结构等在求解实际问题中的应用以及培养书写规范文档的技巧学习基本的查…
-
数据结构实验报告(C语言)(强力推荐)
数据结构实验实验内容和目的掌握几种基本的数据结构集合线性结构树形结构等在求解实际问题中的应用以及培养书写规范文档的技巧学习基本的查…
-
数据结构(C语言版)实验报告
数据结构C语言版实验报告学院计算机科学与技术专业计算机大类强化学号xxx班级xxx姓名xxx指导教师xxx实验1实验题目单链表的插…
-
数据结构实验报告(C语言)单链表的基本操作
计算机科学与技术系实验报告专业名称计算机科学与技术课程名称数据结构与算法项目名称单链表的基本操作班级学号姓名实验日期格式要求实验报…
-
数据结构综合实验心得体会
心得体会:做了一个星期的程序设计终于做完了,在这次程序设计课中,真是让我获益匪浅。对大一学习的C语言和这学期开的数据结构,并没有掌…