哈夫曼树实验报告
数据结构课内实验报告
哈夫曼树
专业:计算机信息工程学院
班级:物联网
姓名: 25678899
学号: 23458900
指导老师:张红
“哈夫曼树”实验报告
一、实验目的:
(1)了解并掌握数据结构与算法的设计方法,具备初步的独立分析和设计能力;
(2)初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能;
(3)提高综合运用所学的理论知识和方法独立分析和解决问题的能力;
(4)训练用系统的观点和软件开发一般规范进行软件开发,培养软件工作者所应具备的科学的工作方法和作风。
二、实验内容:
a.随机生成数据并统计
b.创建哈夫曼树;
c.哈夫曼编码
d.哈夫曼译码;
三、概要设计
1、创建哈夫曼树的描述:
数据结构:数据的逻辑结构是树状结构;采用静态的三叉链表存放;
算法思想:1.先把三叉链表中1-N个元素进行初始化,存放叶子节
点,他们都没有孩子和双亲。2.再初始化后n-1个非叶子节点元素。3.
从当前森林中(在森林中树的根节点的双亲为0)选择两棵根的权值最
小的树;删除合并是将选到的两棵树的根权和存入数组当前最前面的空
闲元素中,并置入相应的双亲与孩子的位置。4.重复上述步骤直到森林
中只含有一棵二叉树为止;
2、哈夫曼树编码的描述:
数据结构:数据的逻辑结构是树状结构;采用静态的三叉链表存放; 算法思想:1.申请存储哈夫曼编码串的头指针数组,申请一个字符型指针,用来存放临时的编码串;2.从叶子节点开始向上倒退,若其为它双亲节点的左孩子则编码标0,否则标1;直到根节点为止,最后把临时存储编码复制到对应的指针数组所指向的内存中;3.重复上述步骤,直到所有的叶子节点都被编码完;
哈夫曼树译码的描述:
数据结构:数据的逻辑结构是树状结构;采用静态的三叉链表存放; 算法思想:1.从根结点开始向下递推,若其编码当前的数值为0,则到该节点的左孩子,否则转到其右孩子;重复上述步骤直到该编码中全部访问完,则树中对应的叶子节点则为所求2.依据上述步骤,对编码数组
中所有编码全部进行译码;
四、模块划分:
1.选择两个权值最小的结点;
2.创建哈夫曼树;
3.打印哈夫曼树
4.哈夫曼编码
5.哈夫曼译码
五、详细设计及运行结果:
1.哈夫曼编码:
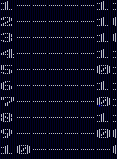
六、调试情况,设计技巧及体会
实验中对数据变量的修改有一部分没有太注意,没有传引用,导致实验结果和预期不对,断点调试后才找出问题所在。
通过这次试验,自我感觉收获很深,无论是对于编程本身还是对集成开发环境的使用上,还有对知识掌握的熟练程度上,都有了很大的提高。对于哈夫曼树的算法有了很深的印象。
七、流程图
八、源程序清单 Function.h
#include<iostream>
#include<fstream>
#include<time.h>
#define Status int
#define OK 1
#define ERROR 0
#define random(x) (rand()%x)
typedef struct{
double weight;
unsigned int parent,lchild,rchild;
char ch;
}HTNode, *HuffmanTree;
typedef char **HuffmanCode;
using namespace std;
Status CreatRandomNum()
{
srand(time(NULL));
fstream file;
file.open("random.txt",ios::binary|ios::out); int RNum[10000];
for(int i=0;i<10000;i++)
{
RNum[i]=random(10);
file<<RNum[i];
}
file.close();
puts("随机数已产生,保存在程序目录下的random.txt"); return OK;
}
Status GeHuffmanPos(double *n)
{
ifstream file("random.txt");
if(file.fail()) return ERROR;
char temp;
while(file.get(temp))
{
int t;
t=(int)temp-48;
n[t]+=1;
}
file.close();
for(int i=0;i<10;i++)
{
n[i]/=10000;
cout<<(n[i])<<endl;
}
return OK;
}
void Select(HuffmanTree HT,int t,int &s1,int &s2)
{
int i;
double m,n;
m=n=1;
for(i=1;i<=t;i++)
{
if(HT[i].parent==0&&(HT[i].weight<m||HT[i].weight<n)) if(m<n)
{
n=HT[i].weight;
s2=i;
}
else
{
m=HT[i].weight;
s1=i;
}
}
if(s1>s2) //s1放较小的序号
{
i=s1;
s1=s2;
s2=i;
}
}
Status HuffmanCoding(HuffmanTree &HT,HuffmanCode &HC,double n,Status &Huffcode)
{
if(w[0]==0)
return ERROR;
if(n<=1) return ERROR;
*w,int
puts("Ok"); int m=2*n-1; int i; HT=(HuffmanTree)malloc((m+1)*sizeof(HTNode)); puts("OK"); HuffmanTree p; for(p=HT+1,i=1;i<=n;++i,++p,++w) { p->weight=*w; p->lchild=0; p->rchild=0; p->parent=0; } for(;i<=m;++i,++p) { p->weight=0; p->lchild=0; p->rchild=0; p->parent=0; } puts("OK"); int j; for(i=0,j=0;i<10;i++) { HT[j+1].ch=i+'0'; j++; } int s1,s2; for(i=n+1;i<=m;++i) { Select(HT,i-1,s1,s2); HT[s1].parent=i;HT[s2].parent=i; HT[i].lchild=s1;HT[i].rchild =s2; HT[i].weight =HT[s1].weight+HT[s2].weight; } HC=(HuffmanCode)malloc((n+1)*sizeof(char *)); char *cd; cd=(char*)malloc(n*sizeof(char)); cd[n-1]='\0'; int start,c; unsigned int f; for(i=1;i<=n;++i) { start=n-1;
for(c=i,f=HT[i].parent;f!=0;c=f,f=HT[f].parent)
{
if(HT[f].lchild==c) cd[--start]='0';
else cd[--start]='1';
}
HC[i]=(char *)malloc((n-start)*sizeof(char));
strcpy(HC[i],&cd[start]);
puts(HC[i]);
}
free(cd);
Huffcode=OK;
return OK;
}
Status PrintHuffman(HuffmanCode HC,Status &Huffcode)
{
if(!Huffcode) return ERROR;
for(int i=1;i<=10;i++)
{
printf("%d-----%s\n",i,HC[i]);
}
return OK;
}
Status HuffEncrypt(HuffmanCode HC,Status &Huffcode,Status &Huffcrypt) {
if(!Huffcode) return ERROR;
ifstream file("random.txt");
if(file.fail()) return ERROR;
char temp;
int i;
fstream encryptfile;
encryptfile.open("encrypt.txt",ios::out);
while(file.get(temp))
{
for(i=0;HC[temp-47][i]!='\0';i++)
{
encryptfile<<(HC[temp-47][i]-48);
}
}
puts("编码结果存放在目录下的encrypt.txt");
file.close();
encryptfile.close();
Huffcrypt=OK;
return OK;
}
Status HuffDecrypt(HuffmanTree HT,Status &Huffcrypt,int n) {
if(!Huffcrypt) return ERROR;
int m=2*n-1;
int mm;
//if(!Huffcrypt) return ERROR;
ifstream file1("encrypt.txt");
char *CodeStr;
int k=0;
char chch;
while(file1.get(chch))
{
k++;
}
file1.close();
CodeStr=new char[k+1];
ifstream file2("encrypt.txt");
k=0;
while(file2.get(chch))
CodeStr[k++]=chch;
file2.close();
ofstream file3("decrypt.txt");
CodeStr[k]='\0';
mm=m;
for(int i=0;i<=k;)
{
if(HT[mm].lchild==0&&HT[mm].rchild==0)
{
file3.put(HT[mm].ch);
mm=m;
continue;
}
else
{
if(CodeStr[i]=='0')
{
mm=HT[mm].lchild;
} i++; } else { mm=HT[mm].rchild; i++; } } } puts("编码结果存放在目录下的decrypt.txt"); file3.close(); return OK;
Main.cpp
#include"Function.h"
void main()
{
double NumCount[10]={0};
int n=10;
int ChooSe;
Status Huffcode=ERROR;
Status Huffcrypt=ERROR;
HuffmanCode HC;
HuffmanTree HT;
while(true)
{
puts("*******************************************"); puts(" 哈弗曼编解码实验 "); puts("1.生成随机数文件");
puts("2.显示随机数概率");
puts("3.生成哈夫曼编码树及哈夫曼编码");
puts("4.哈夫曼编码");
} } puts("5.显示码文"); puts("6.译码并输出"); puts("7.退出"); cin>>ChooSe; switch(ChooSe) { case 1: if(!CreatRandomNum()) puts("随机数生成失败"); break; case 2: if(!GeHuffmanPos(NumCount)) puts("概率生成失败"); break; case 3: if(!HuffmanCoding(HT,HC,NumCount,n,Huffcode)) puts("哈夫曼树生成失败"); break; case 4: if(!HuffEncrypt(HC,Huffcode,Huffcrypt)) puts("未生成哈夫曼树及编码"); break; case 5: if(!PrintHuffman(HC,Huffcode)) puts("未生成哈夫曼树及编码"); break; case 6: HuffDecrypt(HT,Huffcrypt,n); break; case 7: exit(NULL); break; default: puts("ERROR"); } getchar();
第二篇:哈夫曼编译码实验指导书
实验七 哈夫曼编/译码器
一、实验目的
通过哈夫曼树的构造,深刻理解二叉树的构造。通过哈夫曼编/译码过程,深刻领会二叉树的基本操作和二叉树的应用,帮助学生熟练掌握二叉数组织数据的基本原理和对二叉数操作的实现方法。
二、实验内容
本实验的主要内容是:
1、由文本字符及字符在文本文件中出现的频率,构造带权路径最短的最优二叉树(哈夫曼树),并依此为基础构造字符的前缀编码(哈夫曼编码);
2、编码:从文本文件中读入文本字符,按照已知的字符哈夫曼编码将文本字符转换为二进制串的哈夫曼编码形式。
3、译码:从文件中读入二进制串字符,按照哈夫曼树将其转换为文本字符。
4、输出哈夫曼树:以凹入表(层次表)的形式显示哈夫曼树。
三、实验仪器
微型计算机
实验用编程语言:Turbo C 2.0,Borland C 3.0等以上版本
四、实验原理
1、哈夫曼树的定义
哈夫曼树(最优二叉树):设有n个权值{w1,w2,...,wn},试构造一棵有n个叶结点的二叉树,第i个叶结点的权值为wi,则其中带权路径长度为最小的二叉树被称为最优二叉树或哈夫曼树。
2、哈夫曼算法:
哈夫曼算法要点是:
(1)根据给定的n个权值{w1,w2,...,wn}构成n棵二叉树的集合F={T1,T2,...,Tn},其中每棵二叉树Ti只有一个带权为Wi的根结点,左右子树为空。
(2)在F中选取两棵根结点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树根结点的权值为左右子树根结点权值之和。
(3)在F中删除这两棵树,同时将新得到的树加入到F中。
(4)重复(2)和(3),直到只剩下一棵二叉树为止。这棵二叉树便是哈夫曼树。
3、哈夫曼编码
对于字符的二进制编码,若任一字符的二进制编码都不是另一个字符的二进制编码的前缀。这种编码叫做前缀编码。
以n种字符出现的频率作权,设计一棵哈夫曼树,并用二叉树的叶结点分别表示待编码的字符,并约定左分支表示字符‘0’,右分支表示字符‘1’。则对每个叶结点,都有唯一的一条从根结点出发的路径,则该路径上分支字符组成的字符串作为该叶子结点的编码。由此得到的编码必为二进制的前缀编码,而且是编码总长最短的二进制前缀编码,这种编码即为哈夫曼编码。
例:设有8个字符{A,B,C,D,E,F,G,H},其概率为{0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11},设其权值用整数表示为 {5,29,7,8,14,23,3,11}
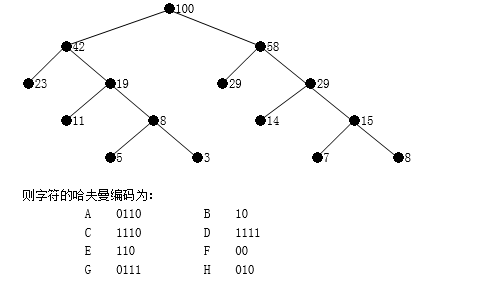
则字符的哈夫曼编码为:
A 0110 B 10
C 1110 D 1111
E 110 F 00
G 0111 H 010
五、实现
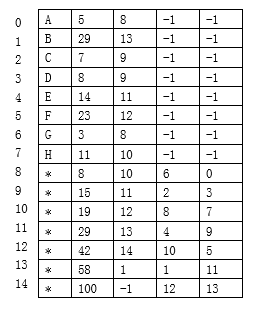
1、哈夫曼树的存储结构
根据哈夫曼树的构造算法,哈夫曼数除叶结点外,其余结点的度均为2。对于具有n个权值构造的哈夫曼树,根据二叉树的性质3,哈夫曼树的结点总数为m=2n-1,即哈夫曼树所需存储空间是由文本中不同字符的个数唯一确定的。为了便于对多棵二叉树进行组织和便于查找各二叉树的根结点,采用静态链表作为二叉树的存储结构。其存储结构描述如下:
typedef struc {
char ch;
unsigned int weight;
unsigned int parent,lchild,rchild;
}HTNode,*HuffmanTree;
2、哈夫曼编码的存储结构
若要编码的文本文件的字符集不变,则其哈夫曼编码不变。字符的哈夫曼编码一旦确定,可以长期使用。因此,需要用文件同时保存字符的哈夫曼编码和字符。哈夫曼编码的表示形式既要考虑存储空间的效率,也要考虑文件读取的方便。
文本字符的哈夫曼编码是不等长的二进制码,用不等长的二进制字符串表示,节省存储空间,但用文件读取不方便。若用等长的结构体表示,可能要浪费一点存储空间,但文件存取方便。为了便于文件存取,采用等长结构体表示哈夫曼具有可取之处,其存储结构描述如下:
#define NODENUM 26 //字符集
struct HuffmanCoding
{ char ch; //字符
char coding[NODENUM]; //字符编码
};
3、字符及权值的输入形式
为了避免字符及其权值的手工键盘输入带来的错误,可以将字符及其权值组织成文本文件的形式。文本文件的格式为:
字符 权值
例如:
A 5
B 19
C 7
D 8
E 14
F 23
G 3
H 11
一般读入单个字符很不方便,格式化输入字符串和数值型数据很方便,所以字符数据可以采用读串的方式读入,然后把它赋给字符变量。
4、文件的设置
(1)字符权值文件
const char *WeighFileName = "Weight.txt";
存放需构造哈夫曼树的字符和权值数据,为文本数据,见“字符及权值的输入形式”。
(2)哈夫曼树数据文件
const char *TableFileName = "HfmTbl.txt";
存放哈夫曼树数据,二进制HTNode结构型。格式为:
<数据个数M><记录1><记录2>……<记录M>
数据个数—哈夫曼树的结点数,M=2n-1,n为权值个数
记录i--二进制HTNode结构型数据
(3)字符编码数据文件
const char *CodeFileName = "CodeFile.txt";
存放字符编码数据,二进制struct HuffmanCoding结构型。格式为:
<数据个数n><记录1><记录2>……<记录n>
数据个数—权值个数
记录i--二进制struct HuffmanCoding结构型数据
(4)文本文件
const char *SourceFileName = "SrcText.txt";
存放需编码的文本字符串数据,其中的字符属于编码字符集。
(5)编码数据文件
const char *EnCodeFileName = "EnCodeFile.txt";
存放对文本文件编码后的数据,其中的数据为“0”和“1”的字符串。
(6)译码字符文件
const char *DecodeFileName = "DecodeFile.txt";
存放译码后的字符文件
5、程序基本功能
(1)初始化:输入编码字符和其权值,生成哈夫曼树和字符的哈夫曼编码,并用文件保存哈夫曼树和字符的哈夫曼编码。
(2)编码:把文本字符串转换为“0”和“1”表示的哈夫曼编码。
(3)译码:把“0”和“1”表示的哈夫曼编码串转换为文本字符串
(4)显示哈夫曼树:以凹入形式显示哈夫曼树。
(5)显示哈夫曼表:以表格形式显示哈夫曼树
(6)显示字符编码
6、辅助功能
(1)菜单选择:将上述功能通过“菜单”形式罗列出来,通过菜单选择进行交互式控制程序运行。
(2)读文件:把哈夫曼树数据读入内存。
(3)选择结点:选择两个具有最小权值的根结点。
7、程序结构
本程序可以由10个函数组成,其中主函数1个,基本功能函数6个,辅助功能函数3个。函数间的调用关系图2所示。
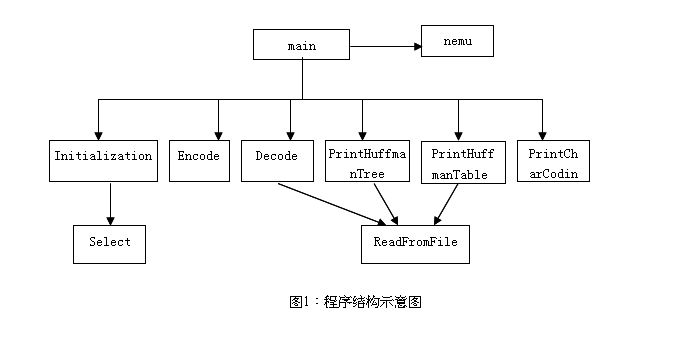
8、程序函数
(1)主函数:main
功能:通过菜单选择控制对系统功能的操作
(2)菜单选择函数:menu
函数格式: int menu(void)
函数功能:构造功能菜单,并选择下一步要操作的功能。
函数参数:无参数。
函数返回值:1~7中的一个序号。
可供选择的功能如下:
1--- Initialization
2---Encode
3---Decode
4---Print huffmantree
5---Print huffman Table
6---Print char Coding
7---Quit
(3)初始化函数:Initialization
函数格式:void Initialization()
函数参数:无参数
函数功能:输入编码字符和权值,生成哈夫曼树和字符编码,并用文件TableFileName和CodeFileName保存哈夫曼树和字符编码数据。
函数返回值:无
(4)文本串编码函数:Encode
函数格式void Encode(void)
函数功能:从文本串文件SourceFileName中读入文本字符,按照CodeFileName文件中字符的编码将其转换为“0”和“1”表示的哈夫曼编码,并把编码结果写入文件EnCodeFileName中。
函数参数:无
函数返回值:无
(5)译码函数:Decode
函数格式 void Decode()
函数功能:从文件EnCodeFileName中读入“0”和“1”表示的哈夫曼编码数据,将其转换为文本字符,并将译码结果写入文件DecodeFileName中。
函数参数:无
函数返回值:无
(6)显示哈夫曼树函数:PrintHuffmanTree
函数格式 void PrintHuffmanTree()
函数功能:以凹式形式显示哈夫曼树
函数参数:无
函数返回值:无
(7)显示哈夫曼树表函数:PrintHuffmanTable
函数格式 void PrintHuffmanTable()
函数功能:以表格形式显示哈夫曼树
函数参数:无
函数返回值:无
(8)显示字符哈夫曼编码函数:PrintCharCoding
函数格式 void PrintCharCoding()
函数功能:显示字符的哈夫曼编码
函数参数:无
函数返回值:无
(9)读文件函数:ReadFromFile
函数格式 int ReadFromFile()
函数功能:从文件TableFileName中读哈夫曼树数据
函数参数:无
函数返回值:0—读数据失败
>0--读入的数据个数
(10)选择根界点函数:Select
函数格式 void Select(struct node ht[],int n, int *s1,int *s2)
函数功能:从多棵树中选择两个权值最小的根结点
函数参数:struct node ht[]—哈夫曼树
int n—选择结点的范围,即只能在0~n中选择结点
int *s1—指向第一个权值最小的结点的指针
int *s2—指向第二个权值最小的结点的指针
函数返回值:无
六、主要算法描述
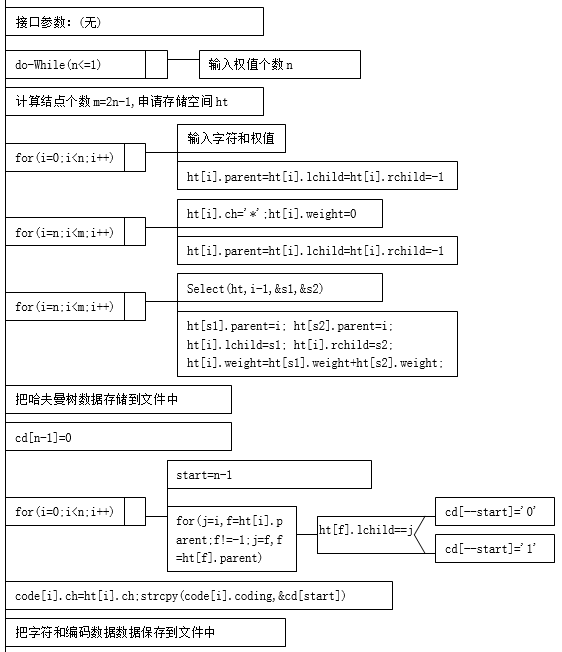
1、初始化函数Initialization算法描述
功能:读入字符及其权值,生成哈夫曼树和字符哈夫曼编码。
字符输入的处理:C语言输入字符的处理很不方便,任何一个字符都当作有效字符处理,包括空格字符和回车符。而用格式读函数读字符串很方便,空格字符和回车符都当作字符串数据的分隔。因此,可以先把字符用格式读函数把字符读入字符数组中,再将其赋值给字符变量,这样处理更简单。
算法步骤:
(1)输入:读入n个叶结点的字符和权值存放于静态树T中的前n个分量中。
(2)初始化:将树T的其余结点的三个指针均置为空(-1),权值置为0,字符为“*”。
(3)合并:进行n-1次合并,将产生的新结点i依次放入T的第i个分量中(n≤i≤m-1)。合并分两步进行:
①在当前森林T[0..i-1]的所有结点中,选取权最小和次小的两个根结点T[p1]和T[p2]作为合并对象。(0≤p1,p2≤i-1)
②将根为T[p1]和T[p2]的两棵树作为左右子树合并为一棵新的树。新树的根为T[i],权值为T[p1]和T[p2]的权值之和。并且T[p1]和T[p2]的parent为i,T[i]的lchild和rchild分别为p1和p2。
(4)保存哈夫曼树数据。
(5)生成字符编码。
(6)保存字符编码数据。
算法描述如下:
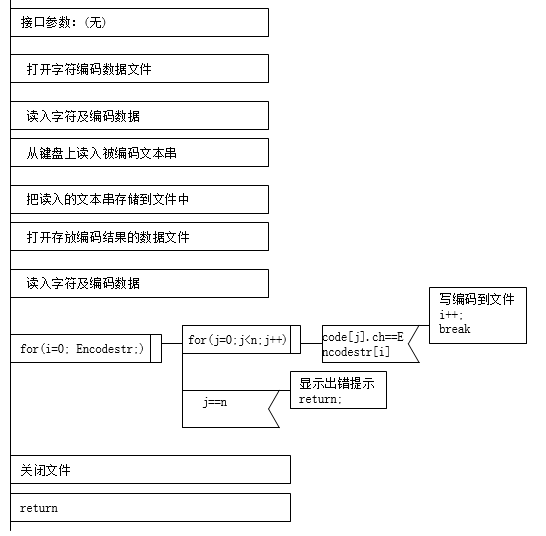
2、编码函数Encode算法描述
原理:对被编码文件中的每个字符,在编码数据表中查找,若字符在编码数据表中,则取出字符编码放入结果文件中。
算法描述如下:
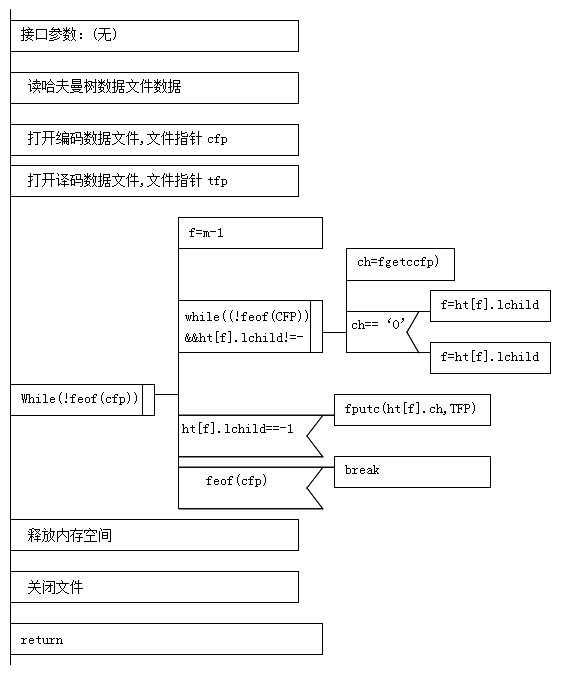
3、译码函数Decode算法描述
译码原理:依次从文件中读入“0”和“1”串,从哈夫曼树根结点开始,若读入的是“0”,则指针以到根结点的左孩子结点;若为“1”,则指针以到根结点的右孩子结点。重复该过程,直到指针达到哈夫曼树的叶结点,输出该叶结点对应的字符,即完成一个字符的译码。
算法描述如下图所示。
3、显示哈夫曼树函数PrintHuffmanTree算法描述
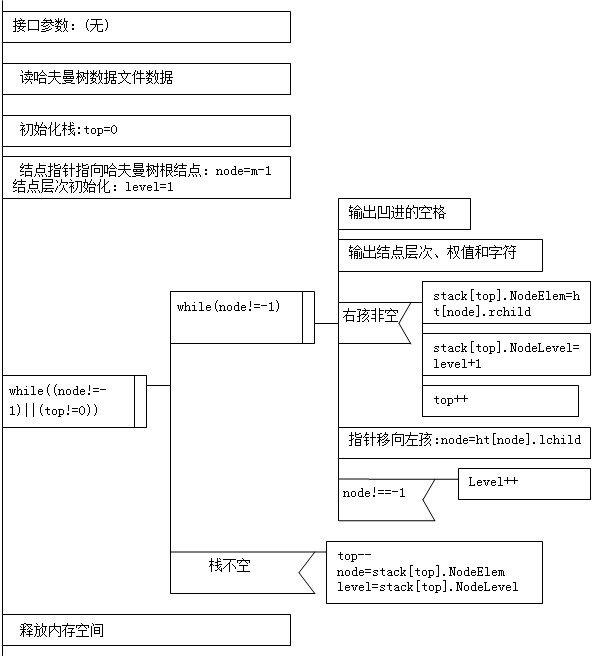
原理:显示哈夫曼树的过程实际上就是按先根顺序输出哈夫曼树结点的过程。如果要按凹式形式输出结点,不仅要知道结点的树出顺序,而且要知道结点的层次,通过结点的层次可以计算出输出内容凹进的格数。在先序遍历的非递归算法中,把结点的层次也作为栈元素的基本内容就可以解决该问题。
栈的结点结构定义如下:
struct stacknode{
int NodeLevel; //结点的层次
int NodeElem; //结点的序号
};
采用顺序栈存储结构。
算法描述如下:
4、选择具有最小权值的两个根结点的函数Select算法描述
原理:根结点的条件是指向父结点的指针为空。
选择第一个具有最小权值的跟结点时,首先要找到第一个根结点,即父结点指针为空的结点,再以次为基础找具有最小权值的根结点。
选择第二个具有最小权值的跟结点时,首先要找到第一个根结点,即父结点指针为空,而且不是第一个被选择的的结点,在以次为基础找具有最小权值的根结点时,同样要注意,满足条件的结点既是根结点,又不是第一个已选结点。
算法描述如下图所式。

七、部分函数代码
#include /* for size_t, printf() */
#include /* for getch() */
#include /* for tolower() */
#include /* for malloc(), calloc(), free() */
#include /* for memmove(), strcpy() */
/*树结构和全局结构指针*/
#define NODENUM 26
/*----------哈夫曼树结点结构-------------*/
struct node
{
char ch;
int weight;
int parent;
int lchild,rchild;
} *ht; //指向哈夫曼树的存储空间的指针变量
/*----------字符编码结点结构-------------*/
struct HuffmanCoding
{ char ch;
char coding[NODENUM];
};
/*--------哈夫曼树遍历时栈的结点结构------*/
struct stacknode{
int NodeLevel;
int NodeElem;
};
/*---------------常量文件名---------------*/
const char *TableFileName = "HfmTbl.txt"; //哈夫曼树数据文件
const char *CodeFileName = "CodeFile.txt"; //字符编码数据文件
const char *SourceFileName = "SrcText.txt"; //需编码的字符串文件
const char *EnCodeFileName = "EnCodeFile.txt"; //编码数据文件
const char *DecodeFileName = "DecodeFile.txt"; //译码字符文件
/************************************************************/
/* 释放哈夫曼树数据空间函数 */
/************************************************************/
void free_ht()
{
if(ht != NULL)
{
free(ht);
ht = NULL;
}
}
/************************************************************/
/* 从文件读取哈夫曼树数据函数 */
/************************************************************/
int ReadFromFile()
{
int i;
int m;
FILE *fp;
if((fp=fopen(TableFileName,"rb"))==NULL)
{ printf("cannot open %s\n", TableFileName);
getch();
return 0;
}
fread(&m,sizeof(int),1,fp); //m为数据个数
free_ht();
ht=(struct node *)malloc(m*sizeof(struct node));
fread(ht,sizeof(struct node),m,fp);
fclose(fp);
return m;
}
/************************************************************/
/* 吃掉无效的垃圾字符函数函数 */
/* 从键盘读字符数据时使用,避免读到无效字符 */
/************************************************************/
void EatCharsUntilNewLine()
{
while(getchar()!='\n') continue;
}
/************************************************************/
/* 选择权值最小的两个根结点函数 */
/************************************************************/
void Select(struct node ht[],int n, int *s1,int *s2)
{ int i,j;
(学生完成)
}
/************************************************************/
/* 创建哈夫曼树和产生字符编码的函数 */
/************************************************************/
void Initialization()
{
int i=0,n,m,j,f,s1,s2,start;
char cd[NODENUM];
struct HuffmanCoding code[NODENUM];
FILE *fp;
printf("输入字符总数 n:");
scanf("%d",&n);
EatCharsUntilNewLine();
m=2*n-1;
ht=(struct node *)malloc(m*sizeof(struct node));
//申请哈夫曼树的存储空间
/********************************************************/
/* 创建哈夫曼树 */
/* 1、输入字符和权值 */
/* 2、初始化哈夫曼树 */
/* 3、建立哈夫曼树 */
/********************************************************/
//把哈夫曼树的数据存储到文件中
if((fp=fopen(TableFileName,"wb"))==NULL)
{ printf("cannot open %s\n", TableFileName);
getch();
return;
}
fwrite(&m,sizeof(int),1,fp);
fwrite(ht,sizeof(struct node),m,fp);
fclose(fp);
/*********************************************************/
/* 产生字符编码 */
/* 从页结点开始,沿父结点上升,直到根结点 ,若沿 */
/* 父结点的左分支上升,则得编码字符“0”, 若沿父结 */
/* 点的右分支上升,则得编码字符“1” */
/*********************************************************/
//把字符编码数据存储到文件中
if(!(fp=fopen(CodeFileName,"wb")))
{ printf("cannot open %s\n", CodeFileName);
getch();
return;
}
fwrite(&n,sizeof(int),1,fp);
fwrite(code,sizeof(struct HuffmanCoding),n,fp);
fclose(fp);
free_ht();
printf("\nInitial successfule!\n");
getch();
}
/************************************************************/
/* 哈夫曼编码的函数 */
/************************************************************/
void Encode(void)
{
int i,j,n;
char Encodestr[256];
struct HuffmanCoding code[NODENUM];
FILE *fp1, *fp2;
/********************************************************/
/* 字符编码 */
/* 1、读字符编码数据 */
/* 2、读需编码的字符串 */
/* 3、存储被编码的字符串数据到文件中 */
/* 4、打开存储编码的数据文件 */
/* 5、字符编码 */
/* 方法:依次从被编码的字符串中取一个字符,然后 */
/* 字符编码表中查找对应字符,若找到,则把对应 */
/* 的编码输出到编码数据文件中。 */
/********************************************************/
}
/************************************************************/
/* 哈夫曼译码的函数 */
/************************************************************/
void Decode()
{
FILE *CFP, *TFP;
char DeCodeStr[256];
char ch;
int f,m;
/********************************************************/
/* 字符译码 */
/* 1、读哈夫曼树数据 */
/* 2、打开编码数据文件 */
/* 3、打开存储译码的数据文件 */
/* 4、字符译码 */
/* 方法:依次从编码数据文件中读取编码字符,并从 */
/* 哈夫曼树开始,若是数字字符“0”,则沿其左分 */
/* 支下降到孩子结点;若是数字字符“1”,则沿其 */
/* 右分支下降到孩子结点;如此反复,直到页结点, */
/* 则输出页结点对应的字符到译码数据文件中,并 */
/* 显式。每当译出一个字符,又从页结点开始,如 */
/* 此重复若找到,直到读完编码数据文件中所有字符。 */
/********************************************************/
free_ht();
fclose(CFP);
fclose(TFP);
printf("\n");
getch();
}
/************************************************************/
/* 以凹式形式打印哈夫曼树的函数 */
/************************************************************/
void PrintHuffmanTree()
{ int i,node,child,level,m,top;
struct stacknode stack[80];
m=ReadFromFile();
printf("\n%10c Huffman TRee in Level\n",' ');
printf("%10c--------------------------------------\n",' ');
(学生完成)
}
/************************************************************/
/* 打印哈夫曼字符编码的函数 */
/************************************************************/
void PrintCharCoding()
{ int i,n;
struct HuffmanCoding code[NODENUM];
FILE *fp;
/********************************************************/
/* 打印字符编码 */
/* 1、读字符编码数据 */
/* 2、打印字符编码数据 */
/* 格式: */
/* charactor coding */
/* ------------------------ */
/* charactor coding */
/* */
/* */
/********************************************************/
}
/************************************************************/
/* 以表的形式打印哈夫曼树的函数 */
/************************************************************/
void PrintHuffmanTable()
{ int i,m;
FILE *fp;
/************************************************************/
/* 打印字符编码 */
/* 1、读哈夫曼树数据 */
/* 2、打印哈夫曼树数据 */
/* 格式: */
/* Huffman Table */
/* ------------------------------------------------ */
/* Number charactor weight Parent Lchild Rchild */
/* */
/* */
/************************************************************/
free_ht();
}
int nemu()
{
int num;
printf("\n ******* huffman arithmetic demonstration *********\n");
printf(" *%15c1---Initial%23c\n",' ','*');
printf(" *%15c2---Encode%24c\n",' ','*');
printf(" *%15c3---Decode%24c\n",' ','*');
printf(" *%15c4---Print huffmantree%13c\n",' ','*');
printf(" *%15c5---Print huffman Table%11c\n",' ','*');
printf(" *%15c6---Print char Coding%13c\n",' ','*');
printf(" *%15c7---Quit%26c\n",' ','*');
printf(" **************************************************\n");
printf("%15cSelcet 1,2,3,4,5,6,7: ",' ');
do{
scanf("%d",&num);
}while(num<1 ||num>7);
return(num);
}
void main()
{
while(1)
{
switch(nemu())
{
case 1:
Initialization();
break;
case 2:
Encode();
break;
case 3:
Decode();
break;
case 4:PrintHuffmanTree();
break;
case 5:PrintHuffmanTable();
break;
case 6:PrintCharCoding();
break;
case 7:
return;
}
}
}
-
哈夫曼树实验报告
数学与计算机学院数据结构实验报告年级09数计学号***姓名**专业数电实验地点主楼401指导教师**实验项目哈夫曼树解决编码解码实…
-
数据结构哈夫曼树实验报告
北京邮电大学信息与通信工程学院20xx级数据结构实验报告实验名称实验3哈夫曼树学生姓名陈家斌班级20xx211121班内序号16学…
-
哈夫曼树的实验报告1
哈夫曼编译器一需求分析1本演示程序实现Haffman编译码器的作用目的是为信息收发站提供一个编译系统从而使信息收发站利用Haffm…
-
哈夫曼树实验报告
北京邮电大学信息与通信工程学院20xx级数据结构实验报告实验名称实验三树学生姓名王璇班级20xx211118班内序号29学号092…
-
哈夫曼编码实验报告
哈夫曼编码器实验报告学院:计算机学院班级:计科0801班姓名:***学号:***一.实验目的练习树和哈夫曼树的有关操作,和各个算法…
-
哈夫曼编码实验报告
哈夫曼编码器实验报告学院:计算机学院班级:计科0801班姓名:***学号:***一.实验目的练习树和哈夫曼树的有关操作,和各个算法…
-
哈夫曼编码译码器实验报告
问题解析与解题方法问题分析:设计一个哈夫曼编码、译码系统。对一个ASCII编码的文本文件中的字符进行哈夫曼编码,生成编码文件;反过…
-
实验四 哈夫曼树与哈夫曼编码
实验四哈夫曼树与哈夫曼编码一实验内容问题描述已知n个字符在原文中出现的频率求它们的哈夫曼编码基本要求1初始化从键盘读入n个字符以及…
-
数据结构实验二哈夫曼树及哈夫曼编码译码的实现
福建农林大学金山学院实验报告系教研室专业计算机科学与技术年级08实验课程姓名学号实验室号计算机号实验时间指导教师签字成绩实验二哈夫…
-
哈夫曼编码译码系统课程设计实验报告(含源代码C++ C语言)
东北电力大学计算机科学与技术专业综合设计报告目录摘要IIAbstractII第一章课题描述111问题描述112需求分析113程序设…