中国居民的营养状况分析
中国居民的营养状况分析
班级:食工1204 学号:1201070121 姓名:丘荣欣
完成日期:20xx年1月3号
一、中国人现阶段营养状况
营养是人类生存的基本条件,更是反映一个国家经济水平和人民生活质量的重要指标。调查显示我国居民中仍然存在着营养不良问题。第三次全国营养调查指出,百姓中维生素和矿物质摄入不足及不均衡的现象普遍存在。儿童中因铁、碘、维生素A、D缺乏等造成的营养性疾病也较多。这种状况严重影响儿童的健康和智力的发育,甚至导致儿童死亡率的升高,进而将会影响国民健康水平的提高和经济的发展。
随着经济的发展和居民收入的提高,膳食结构及生活方式发生了变化,营养过剩或不平衡所致的慢性疾病增多,并且成为使人类丧失劳动能力和死亡的重要原因。据卫生部统计,我国每天死于慢性病的人数已占全部死亡的70%以上,而且由此造成的经济损失十分惊人。
营养素之间关系密切,补充时必须强调平衡。但当今市场上产品的配方多来自于西方国家。饮食习惯和体质的不同,决定了中国人所缺的维生素和矿物质与西方人不同,使用西方国家配方并不科学。然而,目前大多数中国人对此知之甚少,导致盲目补充的现象比比皆是。建立科学补充营养素的观念,成为改善中国人营养状况的当务之急。
中国营养学会理事长、世界营养科学联合会理事、著名营养学家葛可佑教授在20xx年9月27日的一个科学报告中有这样一段通俗易懂的比喻(木桶理论):中国人目前的营养状况是:有一些营养素不够,需要立刻补充;有一些营养素已经充足,就不需要再补了。各种营养素在身体里是相互搭配、相互作用、相互依赖、相互协调,关系十分复杂,比如:
维生素A得到维生素E的保护、维生素A防止维生素C的氧化、维生素B群、D、E及钙、磷、锌要成一定的比例、维生素B1、B2、B6必须符合1∶1∶1的比例、维生素B2与C要成比例、磷过量,钙会被耗损、铜过量,锌会损失 、
铁促进维生素B族的代谢、 锌要与维生素B6一起增加摄入量为上。
因此,人体补充营养素的基本原则是:必须把所缺的全部补齐,不缺的不能再补,使人体内各种营养素达到均衡。
(一) 中国人严重缺乏的营养素
(1)钙
钙是中国居民缺乏的严重程度排名第一的营养素。全国人均每天摄入量为405毫克,仅达到RDA(如果人体长期摄入某营养素不足,就会发生缺乏症的危险。当摄入量达到某一数值时,人们就没有发生缺乏症的危险。该数值称为RDA值。)要求的800毫克的49.2%。因缺钙,会有脚抽筋、盗汗、腰酸及骨质疏松等症状。
(2)维生素B2
维生素B2是中国居民缺乏的严重程度排名第二的营养素。全国人均每天摄入量为0.8毫克,仅占RDA要求的1.3毫克的58.4%。缺乏状况各地区之间差异不是很大。因缺乏维生素B2,一些人已出现嘴唇脱皮、皮肤发痒的症状。
(3) 维生素A
维生素A是中国居民缺乏程度排名第三的营养素。全国人均每天摄入量为476微克(其中157微克为维生素A,319微克来自β-胡萝卜素的转化),仅为RDA要求的800微克的61.7%。不少人都有皮肤干燥、粗糙,眼睛干涩、怕光的现象。
(二) 中国人缺乏的营养素
(1)锌
全国人均每天摄入锌12.0毫克,比RDA的要求量少20%,属中国人缺乏的营养素。尤其是儿童、青少年缺锌比较严重,已影响部分儿童、青少年智力和身高的正常发育。
(2)维生素B1
全国人均每天摄入量为1.2毫克,离RDA的要求差11.3%。因城市居民已广泛使用精白米面,而维生素B1主要含在大米、小麦的表面上,所以城市居民实
际缺乏情况比调查数据还要严重。煮熟的大米所含的维生素B1基本上已被破坏。
(3)硒
中国人均每天摄入量为42微克,离RDA要求相差11.7%。
(4)铁
调查食物摄入数据,中国人每天摄入铁已达到RDA要求,但据调查后分析,中国居民食用的铁,主要来自于大米、坚果、黑叶蔬菜等植物中的非原血红素铁,其利用率较低,吸收率也远远低于动物性食物中所含的铁。另外,中国人食用量最大的谷物中,含有浓度较高的植物酸,植物酸会明显抑制铁的吸收。所以,尽管摄入了一定量的铁,但真正被人体吸收的铁并不能满足人体的需要,仍然广泛存在着贫血现象。
(5)维生素C
全国人均每天摄入量为100.2毫克,已达到DRI的100毫克的要求。但是,维生素C主要来源于蔬菜中,中国居民饮食上习惯食用煮熟的蔬菜,其中多数维生素C已被破坏。
(三) 中国人不缺的营养素
(1) 磷
全国人均每天摄入量为1058毫克,而RDA的要求为700毫克,超出358毫克。因磷和钙最佳的比例为1∶1,如果磷大于钙的摄入量,钙的吸收就会被破坏。中国居民实际摄入比例为钙∶磷=406∶1058,钙与磷的比例严重倒置。这一点已引起中国营养界的高度重视。
(2) 铜
全国人均每天摄入量为2.4毫克,DRI推荐量为2.0毫克。过量的铜有明显的毒性,且铜过量会导致锌的损失。所以,中国摄入的铜是多了而不是少了。自人类有文字记载以来,尚未发现任何国家有过铜不足的记录,反而关于铜中毒的记载却不少。
(3) 女士不缺维生素D
因成年妇女维生素D的需求量为5微克,仅为儿童和老人的一半,中国成
年妇女已达到5微克的标准,故不缺维生素D,但儿童和老人因需求量比成年妇女大一倍,故有一定的缺乏。
(4)泛酸
中国居民饮食范围较广,而泛酸广泛地存在于各类食物中。所以,调查发现,中国人根本不缺泛酸。
(5) 儿童、青少年不缺维生素E
我国儿童、青少年人均每天摄入的维生素E偏高,达到RDA的300%。主要是因为我国食用豆油、麻油等植物油远高于西方国家。维生素E对提高成年人生育能力、抗氧化有很大的促进作用,但儿童、青少年过量则有较大风险。
(6)镁
镁缺乏症患者并不多,几乎只有患呼吸不良症、呕吐情形严重或注射大量缺镁输液,才会发生缺镁症状。镁过量会引起运动肌障碍,且会妨碍体内的铁效利用,建议中国人不要盲目补充。
(7) 维生素B12
维生素B12和在人体内仅停留4小时的维生素C不同,维生素B12在肝内的储存可以供3~6年之需。因此,中国缺乏维生素B12的人十分罕见。维生素B12过量,不仅会导致叶酸缺乏,还会出现哮喘、湿疹、面部浮肿、寒颤等过敏反应,发生心前区痛、心悸,常能使心绞痛的病情加重或发作次数增加。
二、饮食与健康的关系
世界卫生组织研究发现,个人的健康与寿命,生活方式决定了百分之六十,环境因素决定了百分之十七,生物学因素决定了百分之十五,医疗卫生只决定了百分之八。生活方式中有百分之三十是由饮食决定的。
所以膳食结构变化是影响疾病谱的因素之一。世界卫生组织驻中国代表处项目官员张平平曾指出“如果人们平衡膳食,适度地运动,80%以上的冠心病病例,还有90%以上的二型糖尿病病例,还有三分之一的肿瘤,都是可以预防的。”这是一个惊人的发现。
近20年来人们对肉类、油脂消费量大幅度增加,而谷类、蔬果等消费相应
减少,导致了膳食向高脂肪、高热能、低谷物的不健康方向发展。谷类加工过精,以致有的地区儿童出现维生素B1缺乏。即使在农村,高收入者也出现同样的消费结构变化趋势。这种趋势如不及时加以引导,不但会给人们的健康带来隐患。
我国目前有2亿人超重,6000万人肥胖,其中城市超两成儿童超重或肥胖。我国已经迈入肥胖者增加最快的国家行列。肥胖或超重将大大增加青少年患上心血管疾病、糖尿病甚至是癌症等慢性疾病的风险。而造成儿童超重和肥胖的原因主要是膳食结构不合理和缺乏体育锻炼。营养过剩是肥胖病,心血管疾病、糖尿病、恶性肿瘤等慢性病的共同危险因素:高脂肪膳食与冠心病发病率有关。
目前,动物性食物消费增长,禽肉类及油脂类消费过多、谷类食物消费偏低,使居民的慢性非传染性疾病在不断上升。中国糖尿病的发病率约为5%,且以每年100万新发糖尿病患者的速度增长。患病人数仅次于印度,居世界第二位。并且,世界上糖尿病的发生多在65岁左右;而在中国,则提前到45岁左右。中国的高血压患者达到1.6亿,高脂血症患者也有1.6亿;也就是说,平均每8个中国人里,就有1个高血压患者和一个高脂血症患者。而高血压、高血脂是引发心脑血管疾病和糖尿病的重要原因。出现了越来越多的“现代病”,“富贵病”,威胁到我们每一个人的健康,甚至带来生命危险,是因为我现代人的生活方式发生了改变,尤其是饮食变得和以前大为不同,而这种不同就会给我们健康带来风险和威胁。
此外,奶类、豆类制品摄入过低仍是全国普遍存在的问题。一些营养缺乏病依然存在。铁、维生素A等微量营养素缺乏是我国城乡居民普遍存在的问题.我国居民贫血患病率平均为15.2%。维生素A边缘缺乏率围45.1%。 全国城乡钙摄入量仅为每标准人日389mg,还不到适宜摄入量的半数。
现代人的饮食过于精致,吃入太多高糖、高精制淀粉、高不良油脂、高热量、高化肥、高农药和高化学添加物的食物,反而人体所需的维生素、矿物质和植物营养都很缺乏,所以长期处于一种 “营养不均衡”的状态。很多人意识到这一点,所以便服用人工综合维生素来补充,但这类人工合成的综合维生素会让身体添加许多毒素,反而雪上加霜。现代人不是虚胖就是太瘦,体力也不好。
参照国内外膳食掼提出调整膳食结构“4+1金字塔方案。“4+1”指每日膳食应以“粮、豆类”、“蔬菜、水果”、“奶及奶制品”、“肉、鱼、蛋”四类食物作为支柱,适当增加一类“油、盐、糖”。四类食物按人均计,每日粮豆类食物摄入量为400-500g,,其中大豆(黄豆)约40克;蔬菜、水果摄入量300~400g,其中水果约50克;奶及奶制品摄入量为200-300g;肉、鱼、蛋摄入量为100-200g,按重量堆砌恰似金字塔,塔尖为少量油、糖、盐。“方案”既可保持我国膳食以植物性食物为主,动物性食物为辅的基本特点,又能提高膳食质量特别是蛋白质和钙的数量和质量,还能防止“三高一低”膳食的缺陷;既能预防营养缺乏病,又能预防慢性病。
三、分析及结论
我国国民众的许多饮食行为和习惯正朝着非常不健康的方向转化,越来越多的慢性疾病在威胁着中国居民的身体健康,研究表明谷类食物的消费量与癌症和心血管疾病死亡率之间呈明显的负相关,而动物性食物则是和油脂的消费量与这些疾病的死亡率呈明显的正相关。
综上所述,中国人民的膳食结构应保持以植物性食物为主的传统结构,增加蔬菜、水果、奶类和大豆及其制品的消费。在贫困地区还应努力提高肉、禽、蛋等动物性食品的消费。此外,中国人民的食盐摄入量普遍偏高,食盐的摄入量要降低到每人每日6克以下。把握健康饮食的“十个网球”原则,即以一个网球的体积为标准,肉类每天不超过1个网球,保证两个网球大小的主食(约4-5两)、三个网球的水果以及四个网球的蔬菜。
参考文献
1、中国营养学会.中国居民膳食指南.拉萨:西藏人民出版社,2008,第一版.
2、崔朝辉,周 琴,胡小琪等。中国居民谷类及薯类消费现状分析[J].中国食物与营养,2008.
3、黄梅丽,王俊卿. 家庭科学饮食指南[M].北京:金盾出版社,2002.
第二篇:中国居民水平因素分析
中国居民消费水平因素分
【摘要】:本文旨在从我国19xx年—20xx年人均GDP,通货膨胀率,年底城镇人口占总人口的比重,城乡居民储蓄存款年底余额,通货膨胀率对我国居民人均消费水平的影响进行实例分析。首先,我们综合了几种影响消费因素的理论,建立了理论模型;进而,收集了相关的数据,并利用EVIEWS软件对计量模型进行了参数估计和检验,并加以修正;最后,我们对所得的分析结果进行了经济意义的分析,并相应提出了一些政策建议。
【关键字】:居民消费水平 人均GDP 年底城镇人口占总人口的比重 城乡居民储蓄存款年底余额 通货膨胀率
一.模型的概况
1、问题的提出:
消费是所有经济行为有效实现的最终环节,是促进经济增长的三驾马车之
一。然而,在我国对于经济的拉动却大部分是靠投资,消费贡献率过小。我国经济生活中突出的问题是粗放的增长方式转变缓慢。我国的经济增长过多依靠增加物质要素投入和资源消耗,“三高两低”,即高投入、高消耗、高污染、低质量、低效益问题突出。而对于一个成熟的市场经济,应该是需求导向型经济,而市场需求首先是消费需求。否则市场将会由短缺经济走向过剩经济、由卖方市场转向买方市场,社会消费需求不足,居民消费问题显得更加突出,这对于经济的发展十分不利。现在,所以对于如何启动内需,扩大居民消费变得越来越重要。面对这种现状,认真分析研究中国居民消费的影响因素将有很大的意义。
2、理论基础:
凯恩斯的绝对收入假说,在短期内影响个人消费的主观因素是比较稳定的,消费者的短期消费水平主要取决于现期收入的绝对水平,即居民总体消费水平是受到了居民的可支配收入。GDP是用于衡量一国总收入的一种整体经济指标,人均GDP影响着人均收入,经济扩张时期,人均GDP上升,居民收入增加并稳定,居民用于消费的支出较多,消费水平较高;反之,人均GDP下降时,居民人均收入下降,从而影响居民人均消费水平随之下降。
城镇居民与农村居民的消费倾向不同,且城镇居民的人均收入大于农村居民的人均收入,故而城镇居民占人口总数的比例也影响着我国居民消费水平。 改革开放以来,我国的居民储蓄率始终保持了较高水平。而凯恩斯的绝对收入理论中,其中储蓄是指可支配收入扣除当期消费后的部分。而当可支配收入一定时,消费和储蓄呈负相关。其中凯恩斯的《就业、利息和货币通论》中提出了储蓄悖论:在银行利率一定下储蓄的增多会使得银行可供给企业的贷款增加,从而增加投资,增大供给与收入分配,增加消费;然而存蓄的增加又会影响居民用的消费。所以储蓄对消费的最终作用取决于两个作用之和。而在中国居民储蓄到底会不会影响消费水平?影响的程度有多大?我们选择居民储蓄存款年底余额作为模型中的一个变量来研究存蓄对于消费的影响。
根据曼昆的需求曲线,我们可以知道需求量与价格之间是存在着负相关关系的,所以价格的波动会影响商品的需求量。故而通货膨胀率对于消费有着负相关
关系。
所以我们选取居民消费水平、人均GDP、年底城镇人口占总人口的比重、 城乡居民储蓄存款年底余额、通货膨胀率,研究他们对于中国居民消费水平的影响。
二.模型的数据
1980
1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009
注:Y-居民消费水平(元) X2-人均GDP(元) X3-年底城镇人口占总人口的比重(%) X4-城乡居民储蓄存款年底余额(亿元)(数据来自中经网) X5-通货膨胀率(%)(来自中国统计局《国民经济和社会发展统计公报》)
Y(元)
238
264 288 316 361 446 497 565 714 788 833 932 1116 1393 1833 2355 2789 3002 3159 3346 3632 3887 4144 4475 5032 5573 6263 7255 8349 9098
X2(元)
463 492 528 583 695 858 963 1112.4 1365.5 1519 1644 1893 2311 2998 4044 5046 5846 6420 6796 7159 7858 8622 9398 10542 12336 14185 16500 20169 23708 25575
X3(%) X4(亿元) X5(%)
19.39 20.16 21.13 21.62 23.01 23.71 24.52 25.32 25.81 26.21 26.41 26.94 27.46 27.99 28.51 29.04 30.48 31.91 33.35 34.78 36.22 37.66 39.09 40.53 41.76 42.99 43.9 44.94 45.68 46.6
395.8 523.7 675.4 892.5 1214.7 1622.6 2238.5 3081.4 3822.2 5196.4 7119.6 9244.9 11757.3 15203.5 21518.8 29662.3 38520.8 46279.8 53407.5 59621.8 64332.4 73762.4 86910.7 103617.7 119555.4 141051 161587.3 172534.2 217885.4 260771.7
6 2.4 1.9 1.5 2.8 9.3 6.5 7.3 18.8 18 3.1 3.4 6.4 14.7 24.1 17.1 8.3 2.8 -0.8 -1.4 0.4 0.7 -0.8 1.2 3.9 1.8 1.5 4.8 5.9 4.3
三.模型的建立和检验
1、分析被解释变量与解释变量的散点图:
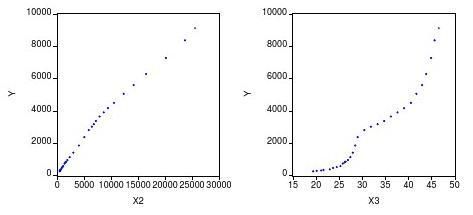
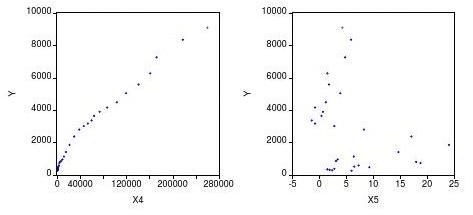
由散点图,可以发现X2与Y大致成线性关系,X3与Y大致成二次方关系,X4与Y成对数关系,而X5与Y的关系不详。
2、根据以上的散点图,我们初步建立的模型为:
Yi=β1+β2X2i+β3(X3i)^2+β4IN(X4i)+β5X5i+Ui
其中,Y=居民消费水平; (元)
X2=人均GDP; (元)
X3=城镇人口比重; (%)
X4=居民储蓄存款年底余额; (亿元)
X5=通货膨胀率。 (%)
3、时间序列平稳性的检验,利用ADF检验对模型中的变量进行平稳性的检验: 1对X2进行平稳性检验: ○
Null Hypothesis: D(X2,2) has a unit root
Exogenous: Constant
Lag Length: 3 (Fixed)
t-Statistic -2.858916 -3.737853 -2.991878 -2.635542
Prob.* 0.0652
Prob. 0.0100 0.0187 0.1627 0.0090 0.2188 -71.79167 532.0482 14.31701 14.56243 15.46836 0.000009
Augmented Dickey-Fuller test statistic Test critical values:
1% level 5% level 10% level
*MacKinnon (1996) one-sided p-values.
Dependent Variable: D(X2,3) Method: Least Squares Date: 12/06/10 Time: 20:10 Sample (adjusted): 1986 2009
Augmented Dickey-Fuller Test Equation
Included observations: 24 after adjustments
Variable D(X2(-1),2) D(X2(-1),3) D(X2(-2),3) D(X2(-3),3)
C
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
Coefficient -1.003519 0.985169 -0.542236 1.133836 87.65592
Std. Error 0.351014 0.383023 0.373292 0.389481 68.93041
t-Statistic -2.858916 2.572090 -1.452580 2.911150 1.271658
0.765065 Mean dependent var 0.715605 S.D. dependent var 283.7344 Akaike info criterion 1529599. Schwarz criterion -166.8041 F-statistic 2.203747 Prob(F-statistic)
从检验结果看,在1%、5%、10%三个显著性水平下,单位根检验的Mackinnon临界值分别为-3.737853、-2.991878、-2.635542,t检验统计值-2.858916在10% level小于相应的临界值,从而拒绝H。的,这表明X2的二阶差分序列不存在单位根,是平稳序列,也就是说X2序列是二阶单整。 2对于(X3)^2=Z1进行平稳性检验: ○
Null Hypothesis: D(Z1,2) has a unit root Exogenous: None Lag Length: 3 (Fixed)
t-Statistic
Prob.*
Augmented Dickey-Fuller test statistic Test critical values:
1% level 5% level 10% level
-2.076779 -2.664853 -1.955681 -1.608793
Std. Error 0.435842 0.390908 0.331093 0.207418
t-Statistic -2.076779 -0.585165 -0.002351 0.157767
0.0386
Prob. 0.0509 0.5650 0.9981 0.8762 1.965438 25.15882 8.564686 8.761028 1.993734
*MacKinnon (1996) one-sided p-values.
Dependent Variable: D(Z1,3) Method: Least Squares Date: 12/06/10 Time: 20:12 Sample (adjusted): 1986 2009
Augmented Dickey-Fuller Test Equation
Included observations: 24 after adjustments
Variable D(Z1(-1),2) D(Z1(-1),3) D(Z1(-2),3) D(Z1(-3),3) R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood
Coefficient -0.905148 -0.228745 -0.000778 0.032724
0.637374 Mean dependent var 0.582980 S.D. dependent var 16.24684 Akaike info criterion 5279.197 Schwarz criterion -98.77623 Durbin-Watson stat
从检验结果看,在1%、5%、10%三个显著性水平下,单位根检验的Mackinnon临界值分别为-2.664853、-1.955681、-1.608793,t检验统计值-2.076779在10% level小于相应的临界值,从而拒绝H。的,这表明X3的二阶差分序列不存在单位根,是平稳序列,也就是说X2序列是二阶单整。
3对于IN(X4)=Z2进行平稳性检验: ○
Null Hypothesis: D(Z2,2) has a unit root Exogenous: Constant Lag Length: 3 (Fixed)
t-Statistic -3.198174 -3.737853 -2.991878 -2.635542
Prob.* 0.0326
Augmented Dickey-Fuller test statistic Test critical values:
1% level 5% level 10% level
*MacKinnon (1996) one-sided p-values.
Dependent Variable: D(Z2,3) Method: Least Squares Date: 12/06/10 Time: 20:13 Sample (adjusted): 1986 2009
Included observations: 24 after adjustments
Variable D(Z2(-1),2) D(Z2(-1),3) D(Z2(-2),3) D(Z2(-3),3)
C
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
Coefficient -1.944775 0.692049 0.317768 0.319251 -0.010208
Std. Error 0.608089 0.520834 0.394585 0.278001 0.013277
t-Statistic -3.198174 1.328731 0.805321 1.148383 -0.768843
Prob. 0.0047 0.1997 0.4306 0.2651 0.4514 -0.001459 0.096291 -2.519536 -2.274108 8.834139 0.000332
Augmented Dickey-Fuller Test Equation
0.650327 Mean dependent var 0.576712 S.D. dependent var 0.062647 Akaike info criterion 0.074569 Schwarz criterion 35.23443 F-statistic 2.007936 Prob(F-statistic)
从检验结果看,在1%、5%、10%三个显著性水平下,单位根检验的Mackinnon临界值分别为-3.198174、-2.991878、-2.635542,t检验统计值 -3.198174在10% level小于相应的临界值,从而拒绝H。的,这表明IN(X4)的二阶差分序列不存在单位根,是二阶单整序列。
4对X5进行平稳性检验: ○
Null Hypothesis: D(X5) has a unit root Exogenous: Constant, Linear Trend Lag Length: 3 (Fixed)
t-Statistic -4.375699 -4.374307 -3.603202 -3.238054
Prob.* 0.0100
Augmented Dickey-Fuller test statistic Test critical values:
1% level 5% level 10% level
*MacKinnon (1996) one-sided p-values.
Dependent Variable: D(X5,2) Method: Least Squares
Prob. 0.0003 0.0043 0.1789 0.0244 0.5491 0.5196 -0.116000 7.157262 6.173951 6.466481 6.944135 0.000766
Augmented Dickey-Fuller Test Equation
Date: 12/06/10 Time: 20:14 Sample (adjusted): 1985 2009
Included observations: 25 after adjustments
Variable D(X5(-1)) D(X5(-1),2) D(X5(-2),2) D(X5(-3),2)
C
@TREND(1980) R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
Coefficient -1.745690 1.046283 0.341901 0.485579 1.514563 -0.088363
Std. Error 0.398951 0.323128 0.244953 0.198601 2.483040 0.134663
t-Statistic -4.375699 3.237979 1.395783 2.444991 0.609963 -0.656177
0.646319 Mean dependent var 0.553245 S.D. dependent var 4.783897 Akaike info criterion 434.8277 Schwarz criterion -71.17439 F-statistic 1.815690 Prob(F-statistic)
从检验结果看,在1%、5%、10%三个显著性水平下,单位根检验的Mackinnon临界值分别为-4.374307、-3.603202、-3.238054,t检验统计值-4.375699在10% level小于相应的临界值,从而拒绝H。的,这表明X5的二阶差分序列不存在单位根,是平稳序列,也就是说X5序列是二阶单整。
5对Y进行平稳性检验: ○
Null Hypothesis: D(Y,2) has a unit root Exogenous: None Lag Length: 3 (Fixed)
t-Statistic -2.025748 -2.664853 -1.955681 -1.608793
Prob.* 0.0431
Augmented Dickey-Fuller test statistic Test critical values:
1% level 5% level 10% level
*MacKinnon (1996) one-sided p-values.
Augmented Dickey-Fuller Test Equation
Dependent Variable: D(Y,3) Method: Least Squares Date: 12/06/10 Time: 20:15 Sample (adjusted): 1986 2009
Included observations: 24 after adjustments
Variable D(Y(-1),2) D(Y(-1),3) D(Y(-2),3) D(Y(-3),3)
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood
Coefficient -0.799888 0.412340 -0.211934 -0.082242
Std. Error 0.394860 0.394951 0.351791 0.310783
t-Statistic -2.025748 1.044029 -0.602442 -0.264628
Prob. 0.0563 0.3089 0.5536 0.7940 -16.04167 152.2411 12.65342 12.84976 1.747804
0.409130 Mean dependent var 0.320499 S.D. dependent var 125.4951 Akaike info criterion 314980.4 Schwarz criterion -147.8411 Durbin-Watson stat
从检验结果看,在1%、5%、10%三个显著性水平下,单位根检验的Mackinnon临界值分别为-1.955681、-1.955681、-1.608793,t检验统计值-2.025748在10% level小于相应的临界值,从而拒绝H。的,这表明Y的二阶差分序列不存在单位根,是平稳序列,也就是说Y序列是二阶单整,即Y是I(2)。
分析Y,X2,(x3)^2、IN(X4)、X5之间是否存在协整关系,所以得用Y,x2,(x3)^2、IN(X4)、X5一阶差分后的结果进行回归,即回归方程为
Y-Y(-1)=β1+β2[X2i-X2i(-1)]+β3[(X3i)^2-(X3i(-1))^2]+β4[INX4i-INX4i(-1)]+β5[X5i-X5i(-1)]
进行回归得:( Z1=(X3)^2, Z2=In(x4))
Dependent Variable: Y-Y(-1) Method: Least Squares Date: 12/06/10 Time: 20:51 Sample (adjusted): 1981 2009
Included observations: 29 after adjustments
Variable C X2-X2(-1) Z1-Z1(-1) Z2-Z2(-1) X5-X5(-1)
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
Coefficient -71.24305 0.295533 0.554170 386.4778 -0.661120
Std. Error 104.0234 0.015323 0.677512 292.6315 2.552170
t-Statistic -0.684875 19.28665 0.817948 1.320698 -0.259042
Prob. 0.5000 0.0000 0.4214 0.1991 0.7978 305.5172 290.5970 11.44545 11.68119 120.1911 0.000000
0.952453 Mean dependent var 0.944529 S.D. dependent var 68.44248 Akaike info criterion 112425.0 Schwarz criterion -160.9590 F-statistic 0.976861 Prob(F-statistic)
检验回归残差的平稳性:
Null Hypothesis: E has a unit root Exogenous: None Lag Length: 3 (Fixed)
t-Statistic -1.879937 -2.660720 -1.955020 -1.609070
Std. Error 0.289998 0.304121 0.282825
t-Statistic -1.879937 0.429275 -0.710518
Prob.* 0.0585
Prob. 0.0741 0.6721 0.4852
Augmented Dickey-Fuller test statistic Test critical values:
1% level 5% level 10% level
*MacKinnon (1996) one-sided p-values.
Dependent Variable: D(E) Method: Least Squares Date: 12/06/10 Time: 20:53 Sample (adjusted): 1985 2009
Augmented Dickey-Fuller Test Equation
Included observations: 25 after adjustments
Variable E(-1) D(E(-1)) D(E(-2))
Coefficient -0.545178 0.130551 -0.200952
D(E(-3))
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood
-0.000750 0.262165 -0.002861 0.9977 8.817361 66.70558 11.21591 11.41093 1.765753
0.260460 Mean dependent var 0.154811 S.D. dependent var 61.32521 Akaike info criterion 78976.41 Schwarz criterion -136.1988 Durbin-Watson stat
从检验结果看,在1%、5%、10%三个显著性水平下,单位根检验的Mackinnon临界值分别为-2.660720、-1.955020、-1.609070,t检验统计值-1.879937在10% level小于相应的临界值,从而拒绝H。的,这表明残差E的二阶差分序列不存在单位根,是平稳序列,也就是说E序列是二阶单整。序列X2、(X3)^2、IN(X4)、X5与Y之间存在协整。
4、对模型进行初步回归
根据以上的数据和建立的模型,利用EVIEWS软件,用OLS方法进行进行多重回归分析,得:
Dependent Variable: Y Method: Least Squares Date: 12/06/10 Time: 20:58 Sample: 1980 2009 Included observations: 30
Variable C X2 (X3)^2 LOG(X4) X5
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
Coefficient -1344.204 0.290249 0.213243 0.213243 -11.83202
Std. Error 186.9043 0.014019 0.251527 33.68747 4.256366
t-Statistic -7.191937 20.70330 0.847792 6.129625 -2.779840
Prob. 0.0000 0.0000 0.4046 0.0000 0.0102 2764.767 2565.384 12.69973 12.93327 2886.270 0.000000
0.997839 Mean dependent var 0.997494 S.D. dependent var 128.4350 Akaike info criterion 412388.4 Schwarz criterion -185.4960 F-statistic 0.506903 Prob(F-statistic)
Yi=-1344.204+0.290249X2i+0.213243 (X3i)^2-0.213243IN(X4i)-11.83202X5i
(-7.191937) (20.70330) (0.847792) (6.129625) (-2.779840) R?=0.997839 R2=0.997494 F=2886.270
5、多重共线性的检验与修正 C、X2、IN(X4)、X5的t值都显著,但是(X3)^2的t值很小,方程的F值很大,说明方程可能存在严重的多重共线性。对方程进行多重共线性的检验及修正:
X2 Z1 Z2 X5
X2 1 0.9618225208
25347 33196 271481
1 44041 858484
0.83333903720.9114759896
1 327645
-0.250154389-0.311116023-0.179865313
1
Z1 25347
Z2 33196 44041
X5 271481 858484 -0.179865313327645
0.96182252080.8333390372-0.250154389
0.9114759896-0.311116023
(Z1=(x3)^2,z2=IN(x4))
由相关系数矩阵可以看出,X2与(X3)^2,X2与IN(X4)之间相关系数很高,证实确实存在严重的多重共线性。
修正多重共线性:采用逐步回归的方法,去检验和解决多重共线性问题。 分别做Y对X2、(X3)^2、IN(X4)、X5的一元回归结果如下:
变量 参数估计值 t统计量
X2 0.357671 46.57830 0.987258 0.986803
(X3)^2 4.459784 25.45669 0.958583 0.957103
IN(X4) 1125.519 9.890244 0.777454 0.769506
X5 -109.1137 -1.514741 0.075738 0.042729
R2
R
2
其中,加入X2的方程R2最大,以X2为基础,顺次加入其它变量逐步回归。结果如下:
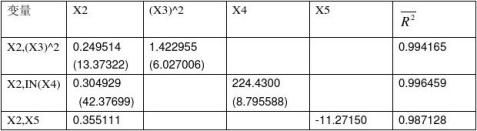

经比较,新加入IN(x4)的方程R2=0.996459,比只有X2时的一元回归改进最大,而且各参数的T检验显著,选择保留IN(X4),再加入其它新的变量逐步回归,结果如下:
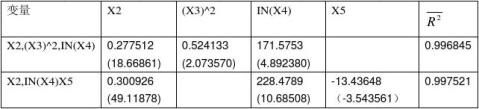
当分别加入X5时,R2=0.9975214比原先二元回归的R2=0.996459大。 最后修正严重多重共线性影响后的回归结果为
Dependent Variable: Y Method: Least Squares Date: 12/06/10 Time: 21:15 Sample: 1980 2009 Included observations: 30
Variable C X2 LOG(X4) X5
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
Coefficient -1392.328 0.300926 228.4789 -13.43648
Std. Error 177.1103 0.006126 21.38297 3.791802
t-Statistic -7.861360 49.11878 10.68508 -3.543561
Prob. 0.0000 0.0000 0.0000 0.0015 2764.767 2565.384 12.66141 12.84824 3890.202 0.000000
0.997777 Mean dependent var 0.997521 S.D. dependent var 127.7384 Akaike info criterion 424244.6 Schwarz criterion -185.9212 F-statistic 0.552486 Prob(F-statistic)
Yi=-1392.328+0.300926X2i+228.4789IN(X4i)-13.43648X5i t=(-7.861360) (49.11878) (10.68508) (-3.543561)
R2=0.997777 R2=0.997521 F=3890.202 DW=0.552486
6、模型设定误差的检验
在多重共线性中,我们剔除了变量(X3)^2,但是IN(X4)的参数为正,这与上面理论分析中不符。所以,我们要对于模型进行设定误差检验。检验是否多了或者少了解释变量。
作模型Yi=-1392.328+0.300926X2i+228.4789IN(X4i)-13.43648X5i 显然,模型可能存在自相关现象,其主要原因可能是建模时遗漏了重要的相关变量造成的。
进行模型设定误差检验:
Omitted Variables: (X3)^2 F-statistic Log likelihood ratio
Test Equation: Dependent Variable: Y Method: Least Squares Date: 12/06/10 Time: 21:40 Sample: 1980 2009 Included observations: 30
Variable C X2 LOG(X4) X5 (X3)^2
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
Coefficient -1344.204 0.290249 206.4916 -11.83202 0.213243
Std. Error 186.9043 0.014019 33.68747 4.256366 0.251527
0.718751 Prob. F(1,25)
t-Statistic -7.191937 20.70330 6.129625 -2.779840 0.847792
0.404598 0.356458
Prob. 0.0000 0.0000 0.0000 0.0102 0.4046 2764.767 2565.384 12.69973 12.93327 2886.270 0.000000
0.850335 Prob. Chi-Square(1)
0.997839 Mean dependent var 0.997494 S.D. dependent var 128.4350 Akaike info criterion 412388.4 Schwarz criterion -185.4960 F-statistic 0.506903 Prob(F-statistic)
不拒绝原假设,说明(X3)^2是遗漏变量,加入(X3)^2,检验是否有多余变量:
Redundant Variables: (X3)^2 F-statistic
0.718751 Prob. F(1,25)
0.404598
Log likelihood ratio
Test Equation: Dependent Variable: Y Method: Least Squares
0.850335 Prob. Chi-Square(1)
Std. Error 177.1103 0.006126 21.38297 3.791802
t-Statistic -7.861360 49.11878 10.68508 -3.543561
Coefficient -1392.328 0.300926 228.4789 -13.43648
0.356458
Prob. 0.0000 0.0000 0.0000 0.0015 2764.767 2565.384 12.66141 12.84824 3890.202 0.000000
Date: 12/06/10 Time: 21:45 Sample: 1980 2009 Included observations: 30
Variable C X2 LOG(X4) X5
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
0.997777 Mean dependent var 0.997521 S.D. dependent var 127.7384 Akaike info criterion 424244.6 Schwarz criterion -185.9212 F-statistic 0.552486 Prob(F-statistic)
从检验中,我们可以知道,(X3)^2是遗漏变量。
由于IN(X4)的参数正负号与经济意义不符,对其进行多余变量检验:
Redundant Variables: LOG(X4) F-statistic Log likelihood ratio
Test Equation: Dependent Variable: Y Method: Least Squares Date: 12/06/10 Time: 21:49 Sample: 1980 2009 Included observations: 30
Variable C X2 (X3)^2
Coefficient -400.3029 0.250766 1.400195
Std. Error 164.3261 0.019317 0.249029
37.57230 Prob. F(1,25)
t-Statistic -2.436028 12.98144 5.622609
0.000002 0.000000
Prob. 0.0220 0.0000 0.0000
27.52341 Prob. Chi-Square(1)
X5
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
-2.104257 6.126885 -0.343446 0.7340 2764.767 2565.384 13.55051 13.73734 1593.864 0.000000
0.994592 Mean dependent var 0.993968 S.D. dependent var 199.2451 Akaike info criterion 1032164. Schwarz criterion -199.2577 F-statistic 0.186550 Prob(F-statistic)
从检验中,我们可以发现IN(X4)是多余变量,剔除后,检验是否有遗漏:
Omitted Variables: LOG(X4) F-statistic Log likelihood ratio
Test Equation: Dependent Variable: Y Method: Least Squares Date: 12/06/10 Time: 21:47 Sample: 1980 2009 Included observations: 30
Variable C X2 (X3)^2 X5 LOG(X4)
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
Coefficient -1344.204 0.290249 0.213243 -11.83202 206.4916
Std. Error 186.9043 0.014019 0.251527 4.256366 33.68747
37.57230 Prob. F(1,25)
t-Statistic -7.191937 20.70330 0.847792 -2.779840 6.129625
0.000002 0.000000
Prob. 0.0000 0.0000 0.4046 0.0102 0.0000 2764.767 2565.384 12.69973 12.93327 2886.270 0.000000
27.52341 Prob. Chi-Square(1)
0.997839 Mean dependent var 0.997494 S.D. dependent var 128.4350 Akaike info criterion 412388.4 Schwarz criterion -185.4960 F-statistic 0.506903 Prob(F-statistic)
IN(X4)是多余变量,可以将其剔除。 于是,模型改为:
Dependent Variable: Y Method: Least Squares Date: 12/06/10 Time: 21:51
Sample: 1980 2009 Included observations: 30
Variable C X2 (X3)^2 X5
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
Coefficient -400.3029 0.250766 1.400195 -2.104257
Std. Error 164.3261 0.019317 0.249029 6.126885
t-Statistic -2.436028 12.98144 5.622609 -0.343446
Prob. 0.0220 0.0000 0.0000 0.7340 2764.767 2565.384 13.55051 13.73734 1593.864 0.000000
0.994592 Mean dependent var 0.993968 S.D. dependent var 199.2451 Akaike info criterion 1032164. Schwarz criterion -199.2577 F-statistic 0.186550 Prob(F-statistic)
Yi=-400.3029+0.250766X2i+1.400195 (X3)^2--2.104257X5i t=(-2.436028) (12.98144) (5.622609) (-0.343446) R2=0.994592 R2=0.993968 F=1593.864 DW=0.186550 7、异方差检验与修正
异方差的检验:利用WHITE检验对模型进行异方差性的检验:
White Heteroskedasticity Test: F-statistic Obs*R-squared
Test Equation:
Dependent Variable: RESID^2 Method: Least Squares Date: 12/06/10 Time: 22:13 Sample: 1980 2009 Included observations: 30
Variable C X2 X2^2 (X3)^2 ((X3)^2)^2
X5
Coefficient 14431.35 50.06543 -0.000892 -46.16602 -0.136259 7181.690
Std. Error 43004.22 7.847507 0.000209 99.67133 0.035346 2453.126
14.30197 Prob. F(6,23)
t-Statistic 0.335580 6.379787 -4.261592 -0.463183 -3.854984 2.927566
0.000001 0.000603
Prob. 0.7402 0.0000 0.0003 0.6476 0.0008 0.0076
23.65878 Prob. Chi-Square(6)
X5^2
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
-385.1219 112.6354 -3.419191 0.0023 34405.46 45320.65 23.15955 23.48650 14.30197 0.000001
0.788626 Mean dependent var 0.733485 S.D. dependent var 23396.83 Akaike info criterion 1.26E+10 Schwarz criterion -340.3933 F-statistic 1.170199 Prob(F-statistic)
从图中可以看出,n R2=23.65878,由WHITE检验知,在α=0.1下,查表得χ
1
20 。
(6)=10.6446(在WHITE检验辅助函数中有6项含有解释变量)所以n
20 。1
R2=23.65878>χ
(9)=10.6446,所以拒绝原假设,标明模型中存在异方差。
利用WLS法修正异方差:
Dependent Variable: Y Method: Least Squares Date: 12/06/10 Time: 22:15 Sample (adjusted): 1981 2009
Included observations: 29 after adjustments Weighting series: 1/(E^2)
Variable C X2 (X3)^2 X5
R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat
R-squared Adjusted R-squared S.E. of regression
Coefficient 403.6726 0.274527 0.792824 -36.10786
Std. Error 115.0856 0.009921 0.154332 7.967899
t-Statistic 3.507585 27.67023 5.137128 -4.531667
Prob. 0.0017 0.0000 0.0000 0.0001 4306.714 10988.94 13.16391 13.35251 9361.397 0.000000
2851.897 2565.220 2883275.
Weighted Statistics
0.999111 Mean dependent var 0.999004 S.D. dependent var 163.9066 Akaike info criterion 671634.4 Schwarz criterion -186.8767 F-statistic 1.711008 Prob(F-statistic) Unweighted Statistics
0.984351 Mean dependent var 0.982473 S.D. dependent var 339.6042 Sum squared resid
Durbin-Watson stat
0.391785
8、自相关性的检验与修正
对修正完异方差后的模型的自相关性检验:对样本量为30、3个解释变量的模型、10%显著水平,查DW统计表可知,dl=1.006,du=1.421,模型中4-du>DW=1.711008>du,模型中是不存在自相关。
所以最终模型为:
Yi=403.6726+0.274527X2i+0.792824 (X3)^2-36.10786X5i
t=(3.507585) (27.67023) (5.137128) (-4.531667)
R2=0.999111 R2=0.999004 F=9361.397 DW=1.711008
四、结果分析
在以上得出的模型中我们得出:β2=0.274527,表示当其他条件不变的情况下,人均GDP每增加1元,居民消费水平增加0.274527元。β3=0.792824,表示当其他条件不变的情况下,城市人口比重在原先为X的情况下每增加1个百分比,居民消费水平增0.792824*(2X+1)。β4=-36.10786,表示当其他条件不变的情况下,通货膨胀率没增加一个百分点,居民当期消费水平减少36.10786元。
1、由以上我们可以看出,尽管影响消费的因素有很多,但是真正影响还是居民的收入(城镇人口比例也会相对程度上影响收入)。所以我们小组对于如何提高我国居民消费情况的建议:重点在于着力提高居民收入,调整国民收入分配结构,提高居民收入占国民收入的比重,大力增强居民的消费能力。
2、在合理范围内,促进城市化进程,同时刺激居民消费倾向。从以上模型中,我们可以发现城镇化水平能很大的促进我国居民消费水平。我们建议,应该从我国国情出发,在合理的范围内,加快农民的市民化进程,让农民变成市民,让农村消费变成城市消费。当然在加快农民市民化时应该最终实现城乡居民身份统一、机会均等、权利平等,而不是牺牲农民的利益。
3、在合理的范围内,控制通货膨胀率。
【参考文献】
[1]凯恩斯;《就业、利息和货币通论》
[2]金三林;《收入分配和城市化对我国居民消费的影响》;2010
[3]王克华;《城镇居民资产变动对消费需求影响的实证研究》;2009
-
20xx年中国居民营养与健康状况调查报告
20xx年中国居民营养与健康状况调查报告关键词中国居民营养与健康状况调查报告中国居民营养与健康现状20xx年10月12日中华人民共…
-
《中国居民营养与健康状况》调查报告
中国居民营养与健康现状20xx年10月12日中华人民共和国卫生部中华人民共和国科学技术部中华人民共和国国家统计局第一部分背景一调查…
-
《中国居民营养与慢性病状况报告(20xx年)》
中国居民营养与慢性病状况报告20xx年一我国居民膳食营养与体格发育状况一是膳食能量供给充足体格发育与营养状况总体改善十年间居民膳食…
-
中国居民营养与健康现状报告
中国居民营养与健康现状报告在卫生部公布的20xx年中国居民营养与健康现状报告中显示中国的超重和肥胖人口已达26亿高血压人口16亿血…
-
中国居民营养与健康现状
中国居民营养与健康现状20xx年10月12日中华人民共和国卫生部中华人民共和国科学技术部中华人民共和国国家统计局第一部分背景一调查…
-
20xx年度财务科工作总结
根据20xx年度年初工作方案,在所领导的正确领导下,同事们的大力支持下,20xx年度财务科各项工作进展顺利,较好的完成了20xx年…
-
青蓝工程师傅总结
葛丽霞为了切实发挥骨干教师的模范带头和辐射作用,加速青年教师的专业成长,提高整体教育教学水平,增强实施新课程的能力,我校本学期在教…
-
【文艺部】5月工作总结
文艺部5月份工作总结时光飞逝,日月如梭,眨眼间,紧张而又忙碌的半学期又即将结束了。这半学期来,我们文艺部在学生会的大家庭中成长着,…
-
高一数学公式总结
一、三角公式以及恒等变换?两角的和与差公式:Sin??????Sin?Cos??Cos?Sin?,S(???)Sin??????S…
-
青蓝工程师傅总结
本人和王老师师徒结对已经一年多了,与其说是我在努力践行着作为师傅应尽的责任,不如说是我和徒弟互相切磋,共同提高。尽管我们的工作多而…