管理统计学读后感
管理统计学读后感
最近闲暇之余,有幸得到一本清华大学出版社李金林老师的《管理统计学》,十分喜爱,这是一本十分实用的书籍,既具有系统的统计学知识,又具有超强的实践指导训练,因而能够很好地满足我们从业人员在统计学数量分析方面的需求。
一、内容简介
《管理统计学》通过以经济管理应用案例为基础的方式,将理论知识框架蕴于实际生活中的经济领域之中,将统计学理论与管理统计实践进行有机结合,围绕统计学分析的方法在生产生活中的运用所产生的各种问题展开,通过引入真实具体的案例来阐释管理统计学理论。同时书中精选了作者数年来积累的MBA教学案例以及实际工作案例,便于读者最大程度上的学以致用。此外,书中还结合实际的应用,详细阐述了通过相关应用软件解决实际问题的方法及技巧,借此来指导读者动手操作。总之,这本书读罢,顿觉是对自己在管理统计上的知识的一次全面升华。
二、知识总结
酣畅淋漓的将此书读完之后,不禁将书中内容与一个从业人员日常生活所用联系起来,回顾性的分析了并总结了一下内心感悟。从以下三个方面进行阐述。
(1)管理统计学在实际生活中的应用
管理统计学是研究如何收集、整理、分析反映社会经济管理问题的有关数据,并对研究对象进行统计分析、推断以期认识事物的规律性的一门科学。它要求管理人员要学会运用统计方法进行决策,改进工作,提高效率。没有统计分析的管理是不完善的管理。在天气预报、证券行业分析、产品寿命估计、产品抽样检验、产品库存量估计、金融保险、市场分析、市场识别、企业风险管理等方面都有着积极的应用。审计员检查一个大公司的帐目,可以通过统计方法抽取帐目样本,根据样本结果确定该公司是否有帐目不清的问题。企业经理需要考虑可能的原材料需求水平和原材料存储费用来确定原材料的进货量,因此他要做相应的调查。经济学家要评价改变销售税对社会的影响,也需要根据消费者的购买模式来进行统计学计算。 营销经理通过对样本顾客进行试销来决定是否销售一种新产品。生产经理根据检验产品样本的质量情况,决定是否对生产过程作出必要的调整……这些都是管理统计学在生产生活中的应用。
(2)管理统计学中统计数据的相关分析
要进行统计分析,前提就是要取得统计数据,一旦离开了统计数据,统计学方法也就失去了用武之地。因此,准确可靠的数据的获取也是统计学研究的重要内容。统计学数据的来源主要有以下几个方面:统计部门和政府部门公布的有关资料,如各类统计年鉴;各类经济信息中心、信息咨询机构、专业调查机构等提供的数据;各类专业期刊、报纸、书籍所提供的资料;各种会议,如博览会、展销会、交易会及专业性、学术性研讨会上交流的有关资料;从互联网或图书馆查阅到的相关资料……统计学的另一大重点就是统计数据的整理,统计数据的整理是通过对统计数据进行的加工处理使其能够满足统计分析的需要,这是介于数据收集与数据分析之间的一个必要环节,对统计学数据的分析以及其结果影响意义重大。统计数据的分析是统计学的核心内容,它是通过统计学描述和统计推断等方法探索出数据内在的数量规律性的过程。通过本书,我对统计学数据的收集、整理、分析等工作的全过程有了全面的了解,同时对统计分组的基本理论和方法进行了全面的掌握,在很大程度上将为我以后的工作起到积极的作用。
(3)数学知识在管理统计学中的作用
从小学开始,我们就开始接触数学知识,由此可见,数学知识在我们日常生活中的重要性。在现代经济社会,每个人都是一个独立的个体,每个人最在意的就是自己的潜在价值,因为每个人能够创造的价值的多少直接与自己的潜在价值有着正相关的关系,而这又与经济生活中的种种现实问题直接相关。比如作为管理者,如何通过正确辨识员工的潜在价值以给其以合适的薪金。数学知识是一切学科的基础,因此在薪金的计算过程中,通过数学知识和统计学知识的结合,利用统计学及其相关手段来解决薪酬问题才是最佳选择。此外,在现在经济条件下,信息量大大增加,各级政府部门、各大公司都需要通过大量的数据处理来获取自己需要的信息,从而对自己所管辖的范围进行合理的管理和调控,这些都建立在数学知识的运用之上。因此,充分结合统计学的专业性、数学知识的严密性,才能更好的为经济管理提供论证,才能更好的指导生活。
三、内心感悟
(1)内心思想启发
随着我国社会的快速发展,社会主义市场经济发展也越来越快,各大中小型企业也如雨后春笋般多了起来。企业的发展、市场的投资、公司的扩建等各种经济活动必然离不开各种数据的统计和分析,良好地数据管理和分析将对一个企业的发展起着至关重要的作用。如何很好的在社会主义市场经济的大环境下做好企业数据的管理和统计,在公司的发展和创新中中加大管理统计方法的运用,将会对未来我们工作的效率、发展的速度、改革的深度等产生重大的影响。
(2)创新指导方向
作为一名烟草公司统计岗位管理者,我充分意识到管理统计学的知识在我们的工作中的广泛的应用。对于我们每一个管理者而言,积极学习管理统计学知识,对于我们加强通过统计学的方法来进行科学的管理,通过统计学的结果来充分调动人的积极性、主动性和创造性有极大的帮助;与此同时,良好的管理统计学知识的运用,也能帮助我们识别良才,并做到知人善任,提高管理者领导水平,改善领导者和被领导者的关系增强企业的凝聚力。未来工作中,我们要多多运用管理统计学等相关专业知识,来帮助自己做出决策,这样也才能真正做到无论是对企业还是对社会,都能做出自己的贡献。
第二篇:管理统计学第2次
《管理统计学》作业集
第一章 导论
1-1 统计的涵义是什么?
答:统计的含义是,它是用来记载和描述一国重要政治经济事项的方法。
1-2 统计学历史上曾有哪些重要的学派?代表人物是谁?他们对统计学发展各有什么贡献?
答:1.数理统计学派,该学派的主要创始人是比利时的统计学家阿道夫·凯特勒(1796-1874年)。凯特勒在统计学发展中的主要功绩是将概率论引入社会现象的研究中,初步完成了统计学与概率论的结合。1867年,这门兼有数学和统计学双重性质的学科被命名为“数理统计学”,凯特勒因此被欧美统计学界誉为“近代统计学之父”。
2.社会统计学派,社会统计学派19世纪产生于德国,主要代表人物有乔治·蓬·梅尔(1841-1925年)和厄·恩格尔(1821-1896年)。社会统计学派对统计学发展的贡献在于:从统计学研究对象上看,它更关注社会现象总体,从研究方法看,它主要采用大量观察法,这构成了“实质性”科学的两大特点。
1-3 说明描述统计学和推断统计学的研究方法、研究内容有什么不同?两者之间有什么联系?
答:描述统计学是研究如何取得反映客观现象的数据资料,对所搜集的数据进行加工整理并通过统计图等形式显示出来,进而通过综合、概括与分析得出反映客观现象的规律性数量特性。具体内容包括统计数据的收集与整理、数据的显示方法、数据分布特征的描述与分析方法等。推断统计学是研究如何根据样本数据去推断总体数量特征的方法,它是对样本数据进行描述的基础上,对统计总体未知的数量特征做出以概率论为基础的推断和估计。具体内容包括抽样估计、假设检验、方差分析及相关和回归分析等。
描述统计学和推断统计学是现代统计学的两个组成部分。其中,描述统计学是整个统计学的基础和统计研究工作的第一步,推断统计学则是现代统计学的核心和统计工作的关键。从描述统计发展到推断统计,既是统计学发展的巨大成就,也是统计学向纵深发展和成熟的标志。由于在统计研究中获取的一般都是样本数据,仅靠描述统计无法得知总体的数量特征,因此,推断统计在现代统计中的地位和任用日益重要。但另一方面,若没有客观、准确、可靠的数据资料,再科学的推断方法也难以得出可靠的结论。可见,描述统计和推断统计相辅相成、缺一不可。
1-4 什么是统计总体和总体单位?为什么说它们是相对的?试举例说明。
答:统计总体又称“调查总体”,简称“总体”,是指客观存在的、在同一性质基础上结合起来的许多个别单位的整体。构成总体的这些个别单位成为总体单位。总体与总体单位具有相对性,随着研究任务的改变而改变。同一单位可以是总体也可以是总体单位。例如:要了解全国工业企业职工的工资收入情况,那么全部工厂是总体,各个工厂是总体单位。如果旨在了解某个企业职工的工资收入情况,则该企业就成了总体,每位职工的工资就是总体单位了。
1-5 什么是标志?什么是指标?说明它们之间有什么关系?
答:统计指标是反映现象总体数量特征的基本概念及其具体数值的总称。
二者的主要区别是:
①指标是说明总体特征的,标志是说明总体单位特征的;
②指标具有可量性,无论是数量指标还是质量指标,都能用数值表示,而标志不一定。数量标志具有可量性,品质标志不具有可量性。
标志和指标的主要联系表现在:
①指标值往往由数量标志值汇总而来;
②在一定条件下,数量标志和指标存在着变换关系。
1-6 统计总体的基本特征是(2)(单项选择题)
(1)同质性、数量性、变异性 (2)大量性、变异性、同质性
(3)数量性、具体性、综合性 (4)总体性、社会性、大量性
1-7 经济管理统计的职能是(1、2、4)(多项选择题)
(1)信息职能 (2)咨询职能 (3)决策职能
(4)监督职能 (5)预测职能
1-8 经济管理统计的主要研究方法有(2、3、4)(多项选择题)
(1)实验法 (2)大量观察法 (3)综合指标法
(4)归纳推理法 (5)分析估计法
1-9 在全市科技人员调查中(1、2、3)(多项选择题)
(1)全市所有的科技人员是总体; (2)每一位科技人员是总体单位;
(3)具有高级职称的人数是数量指标; (4)具有高级职称的人数是质量指标。
1-10 下列总体中属于有限总体的是(1、2、4)(多项选择题)
(1)全国人口总体 (2)一杯水构成的总体
(3)连续生产的产品总体 (4)职工人数总体
第二章 统计数据的调查与收集
2-1 数据的计量尺度有哪几种?不同的计量尺度各有什么特点?
(一) 定类尺度
又称类别尺度,按事物的某种属性对其进行平行的分类或分组。
(二) 定序尺度
又称顺序尺度,是对事物之间等级差别和顺序差别的一种测度。它不仅可以测度类别差,还可以测度次序差。
(三) 定距尺度
又称间隔尺度,是对事物类别或次序之间距离的测度。该尺度通常使用自然或物理单位作为计量尺度。
(四) 定比尺度
又称比率尺度,由于定比尺度有绝对零点(定比尺度中的“0”表示没有,或者是理论上的极限)。因此,不仅可以进行加减运算,还可以进行乘除运算。
2-2 统计数据有哪几种类型?不同类型的数据各有什么特点?
答:从计量尺度计量的结果看,可将统计数据分为两为两种类型:定性数据和定量数据。采用定类尺度和定序尺度计量的数据称为定性数据,它反映事物的品质特征;采用定距尺度和定比尺度计量的数据称为定量数据,它反映事物的数量特征。
2-3 说明数据和变量之间的关系。
答:可取不同值的属性(比如年龄、性别、身高、体重等)称为变量,其取值即为变量值,数据可以给变量赋值,数据是定量的。
2-4 说明调查时间和调查时限之间的区别?为什么普查中要规定统一的调查时间和调查时限?
答:调查时间有两层含义:一是调查的数据资料所属的时间。如果调查的是时点现象,要规定调查资料所属的标准时点。如我国20##年的1%人口抽样调查规定的标准时点是20##年11月1日零时。如果调查的是时期现象,则要明确规定调查现象的起止时间。二是调查时限,即调查工作的起讫时间,即收集和报送数据资料所需的时间,以保证统计数据的时效。如20##年的经济普查要求在20##年1月至5月之间进去,调查时限为5个月。
2-5 说明统计调查的组织形式有哪些?它们之间有什么区别,各自适用于什么情况?
答:统计调查的组织形式有以下几种:1.普查,普查是专门组织的、一次性的全面调查。2.统计报表,统计报表制度是依照《中华人民共和国统计法》的规定,自上而下统一布置、自下而上逐级提供基本统计数据的一种调查方式。3.抽样调查,抽样调查是一种专门组织的非全面调查。它是按照随机原则从总体中抽取一部分单位组成样本进行观察分析,以样本数量特征去推断总体数量特征的一种调查方法。4.重点调查,重点调查是在调查对象中选择一部分重点单位所进行的非全面调查。5.典型调查,典型调查是调查的目的和任务,在对调查对象全面分析的基础上,有意识地选择若干有典型意义或有代表性的单位进行深入、细致调查的一种非全面调查方式。
2-6 抽样调查和重点调查的主要区别有(2、4、5)(多项选择题)
(1)抽选调查单位的多少不同 (2)抽选调查单位的方式方法的不同
(3)取得资料的方法不同 (4)原始资料的来源不同
(5)在对调查资料使用时,所发挥的作用不同
2-7 指出下列总体中的品质标志和数量标志各有哪些?
(1)大学生 (2)工人 (3)电视机
2-8 由( 1、2 )计量形成的数据称为定性数据。(多项选择题)
(1)定类尺度 (2)定序尺度
(3)定距尺度 (4)定比尺度
2-9 由( 3、4 )计量形成的数据称为定量数据。(多项选择题)
(1)定类尺度 (2)定序尺度
(3)定距尺度 (4)定比尺度
2-10 定序尺度可以( 1、2 )。(多项选择题)
(1)对事物分类 (2)对事物排序
(3)计算事物之间差距大小 (4)计算事物数值之间的比值
2-11 以下属于连续变量的有(1、3、4 )。(多项选择题)
(1)国土面积 (2)人口总数
(3)年龄 (4)总产值
第三章 统计数据的整理
3-1 什么是统计分组?统计分组的作用有哪些?
答:统计分组必须遵循穷尽性和互斥性两个原则。数值变量分组有单项式和组距式两种。级距式分组又有离散型与连续型、等距与异距分组之分,对于组距式分组要计算级距、组数、组中值。
3-2 什么是累计次数和累计频数?
答:累计次数和累计频率也是说明总体中各单位分布特征的指标,用以说明总体中在某一变量值水平上下总共包含的总体单位次数和频率。
3-3 某班级40名学生外语考试成绩如下(单位:分):
87 65 86 92 76 73 56 60 83 79 80 91 95 88 71
77 68 70 96 69 73 53 79 81 74 64 89 78 75 66
72 93 69 70 87 76 82 79 65 84
根据以上资料编制组距为10的分布数列,并用Excel绘制直方图。
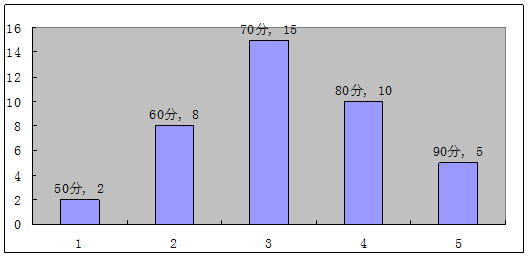
3-4 某企业50名职工月基本工资如下(单位:元):
730 950 480 650 650 490 720 740 850 750 780 700 680 780
580 740 800 820 750 600 450 450 980 500 750 740 720 780
650 680 800 550 760 820 850 740 550 580 550 550 480 700
720 720 730 700 800 650 650 680
将上述统计数据整理成组距为100的等距数列,并绘制直方图和线形图。
3-5 统计分组的作用在于(2、4、5)(多项选择题)
(1)反映总体的基本情况 (2)说明总体单位的数量特征
(3)以区分事物的本质 (4)反映总体内部的结构
(5)研究现象之间的依存关系。
3-6 按数量标志将总体单位分组形成的分布数列是(1、3、5)(多项选择题)
(1)变量数列 (2)品质数列 (3)变量分布数列
(4)品质分布数列 (5)次数分布数列
3-7 影响次数分布的要素是(1、3、4、5)(多项选择题)
(1)变量值的大小 (2)变量性质不同 (3)选择的分组标志
(4)组距与组数 (5)组限与组中值
3-8 下列分组中哪些是按数量标志分组的(1、3、4)(多项选择题)
(1)工人按计划完成程度分组 (2)学生按健康状况分组
(3)工人按产量分组 (4)职工按年龄分组
(5)企业按所有制分组
第四章 数据分布特征的描述
4-1 一组数据的分布特征可以从哪几个方面进行测定?
答:极差、平均差、方差、标准差、离散系数
4-2 说明均值、中位数和众数的特点及应用场合。
答:均值、中位数和众数各自具有不同的特点,掌握它们之间的关系和各自的不同特点,有助于在实际应用中选择合理的测度值来描述数据的集中趋势。
均值主要适合于作为数值型数据的集中趋势测试值,虽然对于数值型数据也可以计算中位数和众数,但以均值为宜。
中位数主要合适于作为顺序数据的集中趋势测试值,虽然对于顺序数据也可以使用众数,但以中位数为宜。
众数主要适合于作为分类数据的集中趋势测度值。
4-3 说明平均差、方差或标准差的适用场合。
答:平均差适用于检测统计用数据是否具有代表性。
方差适用于在根据试验设计所进行的实验中。
标准差可以当作不确定性的一种测量,标准差应用於投资上,可作为量度回报稳定性的指标。
4-4 某公司男性职员的平均年薪是6万元,女性职员的平均年薪为4.8万元。如果公司员工中80%是男性职员,20%是女性职员,求该公司职员的平均年薪,并计算年薪的方差和标准差。
答:职工平均年薪=6*0.8+4.8*0.2=5.76;方差=0.2304;标准差=0.48
4-5 某企业集团所属的四个分厂在某月生产同一规格型号的自行车,它们的产量和总成本如下表所示。

请根据上述资料计算:
(1)各分厂的单位生产成本;
(2)该企业集团的平均单位成本,并对计算方法加以说明。
答:(1)甲厂成本:3.2。乙厂成本:3.5。丙厂成本:3。丁厂成本:3.8。
(2)平均单位成本:3.0995=3.10(万元/百辆)
可以用两种计算方法来算。
4-6 某工厂12名工人完成同一工件所需的时间(分钟)为:
31 34 29 32 35 38 34 30 29 32 31 26
试计算这些数据的众数,中位数,平均数,极差,方差和标准差。
答:无众数,中位数=31.5,平均数=31.75,极差=12,
方差=9.354,标准差=3.0585,
4-7 甲、乙两家企业生产三种产品的单位成本和总成本资料如下表。试比较哪个企业的平均成本高,并分析其原因。

答:先计算出甲、乙两企业ABC三种产品的产量,再计算各企业的平均成本。
甲企业A产品的产量为2100/15=140;乙企业A产品的产量为217;
甲企业B产品的产量为150;乙企业B产品的产量为75;
甲企业C产品的产量为50;乙企业C产品的产量为50;
甲企业的平均成本为19.41;乙企业的平均成本为18.29。乙企业的平均成本低于甲企业的原因在于单件成本较低的A产品的产量较甲企业高。
4-8 甲、乙两个市场的农产品价格及成交量资料如下表所示。试比较哪个市场的平均价格高,并分析其原因。

答:先计算出甲、乙两企业ABC三种产品的产量,再计算各企业的平均成本。
甲市场A产品的销量为10000公斤;乙市场A产品的销量为16666.7公斤;
甲市场B产品的销量为20000公斤;乙市场B产品的销量为7142.9公斤;
甲市场C产品的销量为10000公斤;乙市场C产品的销量为6666.7公斤;
甲市场的平均价格为1.375元/公斤;乙市场的平均价格为1.312元/公斤。乙市场的平均价格低于甲市场的原因在于单价较低的A产品的销量较高,而甲市场则是单价较高的C产品的销量较高。
4-9 判断题:简单算术平均数是权数相等时的加权算术平均数的特例。 ( √ )
4-10 判断题:已知各级别工人的月工资水平和各组工资总额,可以采用加权算术平均法计算平均工资。 ( × )
4-11 判断题:利用组距数列计算算术平均数时,以各组的组中值代表各组的实际数据,是假定各组数据在组内为均匀分布的。 ( √ )
4-12 判断题:对于分布不对称的数据,均值比中位数更适合描述数据的集中趋势。 ( × )
4-13 当需要对不同总体或样本数据的离散程度进行比较时,则使用( 4 )。(单项选择题)
(1)极差 (2)平均差
(3)四分位差 (4)离散系数
4-14 不同总体之间的标准差不能直接对比是因为( 1、2 )。(多项选择题)
(1)平均数不一致 (2)计量单位不一致
(3)标准差不一致 (4)总体单位数不一致
第五章 时间序列分析
5-1 时期数列与时点数列有什么区别?
答:时期序列是由一系列时期指标值所构成的时间数列,数列中各变量值是反映现象在某一段时间内发展变动的总量或绝对水平。特征主要有1.时期序列中各指标数值可以相加,相加后的变量值表示现象在更长时期内发展过程的总量。2.时期序列中每项指标数值的大小与其对应的时期长短有直接关系。一般而言,时期愈长,变量值愈大;反之,变量值愈小。3.时期序列中的各变量值,一般通过连续登记方法获得。时点序列是由一序列时点指标所构成的时间数列,数列中各变量值是反映现象在某一时刻上的总量或水平。特征主要有:1.时点序列中各个变量值不具有可加性。各变量值相加无实际经济意义。2.时点序列中指标数值大小与时间间隔长短没有直接关系。3.时点序列中的变量值一般通过一次性登记获得。
5-2 影响时间序列变动的因素有哪些?
答:影响时间序列的因素归纳起来可分为四类:长期趋势、季节变动、循环变动及不规则变动。
5-3 什么是时间序列的长期趋势?测定长期趋势的方法有哪些?
答:将某种统计指标的数值,按时间先后顺序排到所形成的数列。时间序列预测法就是通过编制和分析时间序列,根据时间序列所反映出来的发展过程、方向和趋势,进行类推或延伸,借以预测下一段时间或以后若干年内可能达到的水平。
长期趋势测定方法:指数平滑法、季节趋势预测法、市场寿命周期预测法。
5-4 什么是季节变动?如何测定季节变动?
答:我们把客观现象由于受自然因素或生产生活条件的影响,在一年内随着季节的更换而引起的规律性变动称为季节变动。测定季节变动的步骤为:1.计算各年的销售额合计和月平均销售额;2.计算所有年份同月份的合计数和月平均数;3.计算所有年份总合计数以及总的月平均数;4.计算季节比率,即用同月的平均数与总的月平均数相对比。
5-5 定基发展速度与环比发展速度之间的关系表现为定基发展速度等于相应各环比发展速度(A )。(单选)
A.的连乘积 B. 的连乘积再减去100%
C.之和 D. 之和再减去100%
5-6 用于分析现象发展水平的指标有:(B、C、D、E)(多选题)
A.发展速度 B. 发展水平 C.平均发展水平
D. 增减量 E. 平均增减量
5-7 某企业20##年9~12月月末职工人数资料如下:

要求计算该企业第四季度的平均职工人数。
答:第四季度的平均职工人数为1460
5-8 某机械厂20##年第四季度各月产值和职工人数如下:

要求计算该季度平均劳动生产率。
解: 月平均劳动生产率(元/人)=1085.2(注意:不能直接用三个月的平均数再求平均,而是需要从总产值和总的人月数求月平均劳动生产率(元/人))
5-9 判断题:在各种时间序列中,变量值的大小都受到时间长短的影响。( × )
5-10 判断题:发展水平就是动态数列中每一项具体指标数值,它只能表现为绝对数。
( √ )
5-11 判断题:若将2000~20##年各年年末国有固定资产净值按时间先后的顺序排列,所得到的动态数列就是时点数列。 ( √ )
5-12 判断题:若逐期增长量每年相等,则其各年的环比发展速度是年年下降的。 ( √ )
5-13 判断题:若环比增长速度每年相等,则其逐期增长量也是年年相等的。 ( × )
5-14 判断题:某产品产量在一段时期内发展变化的速度,平均来说是增长的,因此该产品产量的环比增长速度也一定是年年上升的。 ( × )
第六章 统计指数
6-1 什么是统计指数?统计指数有哪些类型?
答:统计指数是分析社会经济现象数量变动的一种对比性指标。
6-2 统计指数如何分类?
答:1.按指数反映现象的范围不同分为个体指数和总指数;2.按指数的性质不同分为数量指标指数和质量指标指数;3.按指数的编制方法不同分为综合指数和平均指数;4.按指数数列选择的基期不同分为定基指数和环比指数。
6-3 什么是指数化因素和同度量因素?如何区分?
答:指数化因素,即通过指数的编制来反映其变化程度的因素。将不能一同度量的变量转化为可以一同度量的因素,叫同度量因素。
6-4 什么是指数体系的因素分析法?说明因素分析的步骤个方法。
答:指数体系的因素分析是利用指数体系,从绝对数和相对数两方面分析现象的综合变动受各影响因素变动的影响方向和程度的一种分析方法。
步骤:1.建立指数体系,将总指数分解为各构成因素指数的连乘积;2.假定其他因素不变,测定某一因素的影响方向和程度;3.相对数分析:各因素指数的连乘积等于现象变动的总指数;4.绝对数分析:各因素影响的绝对额之和等于现象综合变动的绝对额。
6-5 根据某企业1985-1990年的发展规划,工业产品产量将增加35%,劳动生产率提高30%。试问工人数应增加多少(%)?产品的增加有多大程度是依靠提高劳动生产率取得的?
解:
135%=130%╳Χ X=1.038 工人增加3.8%
产量的增加依靠劳动生产率提高了30%。
6-6 某商品价格发生变化,现在的100元只值原来的90元,则价格指数为( D )。(单选)
A. 10% B. 90% C. 110% D. 111%
6-7 某市工业总产值增长了10%,同期价格水平提高了3%,则该市工业生产指数为( C )。(单选)
A. 107% B. 13% C. 106.8% D. 10%
6-8 单位产品成本报告期比基期下降5%,产量增加6%,则生产费用( A )。(单选)
A. 增加 B. 降低 C. 不变 D. 很难判断
6-9 三种商品的价格指数为110%,其绝对影响为500元,则结果表明( A、C、D )。(多选)
A. 三种商品价格平均上涨10%
B. 由于价格变动使销售额增长10%
C. 由于价格上涨使居民消费支出多了500元
D. 由于价格上涨使商店多了500元销售收入
E. 报告期价格与基期价格绝对相差500元
6-10 平均数指数( A、D、E )。(多选)
A. 是个体指数的加权平均数
B. 计算总指数的一种形式
C. 就计算方法上是先综合后对比
D. 资料选择时,既可以用全面资料,也可以用非全面资料
E. 可作为综合指数的变形形式来使用
6-11 某商场20##年的销售额与20##年相比增加了16.48。这一结果可能是因为
( A、B、C、D )。 (多选)
A. 商品销售量未变,价格上涨了16.48%
B. 价格未变,销售量增长了16.48%
C. 价格上涨了4%,销售量增长了12%
D. 价格下降了4%,销售量增长了21.33%
第七章 抽样与抽样估计
7-1 什么是样本统计量?什么是总体参数?
答:样本统计量是根据样本资料计算的反映样本数量特征的变量,它的值随着样本的不同而变化,因此是一个随机变量。统计量的分布又称抽样分布。总体参数是反映总体的数量特征的数值。在抽样推断中,对一特定总体而言,参数是未知的、待估计的确定值。
7-2 什么是概率抽样?什么是非概率抽样?各有什么特点?
答:概率抽样又称随机抽样,是按随机原则抽取样本单位。非概率抽样又称非随机抽样,是从研究的目的和需要出发,根据调查者的经验或判断,从总体中有意识地抽取部分单位构成样本。
7-3 什么是简单随机抽样?什么是重复抽样和不重复抽样?它们各有什么特点?
答:简单随机抽样也称为纯随机抽样,它是对总体单位不做任何分类或排队,直接从总体中按随机原则抽取样本单位的调查方式。简单随机抽样方式简单易行,最符合随机原则,是抽样调查的基本形式。重复抽样又称有放回的抽样,即从容量为N的总体中抽取单位数为n的样本,每次被抽中的单位都再被放回总体中参与下一次抽样。这样,总体容易永远为N,每个单位在每次抽样中被抽中的机会完全一样,概率均为1/N。不重复抽样也称无放回的抽样,每次从总体中随机抽选的单位经观察后不放回到总体中,即不再参加下次抽样。采用这种方法抽样,在容易为N的总体中,每个单位被抽中的概率在各次抽样中是不同的,第一个样本单位被抽中的概率为1/N,第二个样本单位被抽中的概率是1/(N-1),依此类推。
7-4 什么是系统抽样或机械抽样?它有什么特点?
答:它是首先将总体中各单位按一定顺序排列,根据样本容量要求确定抽选间隔,然后随机确定起点,每隔一定的间隔抽取一个单位的一种抽样方式。特点是:抽出的单位在总体中是均匀分布的,且抽取样本可少于纯随机抽样;既可以用同调查项目相关的标志排队,也可以用同调查项目无关的标志排队;要防止周期性偏差,因为它会降低样本的代表性。
7-5 什么是分层抽样?它有哪几种具体抽样方法?
答:先将总体的单位按某种特征分为若干次级总体(层),然后再从每一层内进行单纯随机抽样,组成一个样本。根据在同质层内抽样方式不同,又可分为一般分层抽样和分层比例抽样,一般分层抽样是根据样品变异性大小来确定各层的样本容量,变异性大的层多抽样,变异性小的层少抽样,在事先并不知道样品变异性大小的情况下,通常多采用分层比例抽样。
7-6 什么是整群抽样?它的特点是什么?
答:整群抽样又称聚类抽样。是将总体中各单位归并成若干个互不交叉、互不重复的集合,称之为群;然后以群为抽样单位抽取样本的一种抽样方式。应用整群抽样时,要求各群有较好的代表性,即群内各单位的差异要大,群间差异要小。
特点是:整群抽样的优点是实施方便、节省经费;整群抽样的缺点是往往由于不同群之间的差异较大,由此而引起的抽样误差往往大于简单随机抽样。
7-7 什么是抽样分布、平均数抽样分布和成数抽样分布?
答:从一个总体中随机抽取容量相等的样本,根据样本资料计算某一统计量所有可能的概率分布,称为这个统计量的抽样分布。简言之,抽样分布就是样本统计量的概率分布。
7-8 说明总体分布、样本分布和抽样分布之间的关系?
答:总体密度曲线:样本容量越大,所分组数越多,各组的频率就越接近于总体在相应各组取值的概率
样本是所研究的对象.抽样是被抽出的样本.
样本分布是所研究的对象的离散情况.抽样分布是被抽出的样本的离散情况.
7-9 什么是置信度、置信区间和置信区间的界限?
答:置信度表示区间估计的可靠程度或把握程度,也即所估计的区间包含总体参数真实值的可能性大小,一般以1-a表示。
7-10 抽样平均误差反映了样本指标与总体指标之间的( D )。(单选题)
A. 实际误差 B. 调查误差
C. 可能误差范围 D. 平均误差程度
7-11 某商店每月销售大米的数量服从正态分布,均值为4500公斤,标准差300公斤。试求
1)当月大米销售量符合下面条件的概率是多少?
(1)超过4800公斤, (2)少于4000公斤, (3)在3800公斤与5000公斤之间。
2)销量最差的5%的月份的最高的销售量是多少?
3)每月销售量有30%的机会超过哪一个销售量?
解:1)超过4800公斤的概率为15.87%。
少于4000公斤的概率为4.75%。
在3800与5000公斤之间的概率为94.18%。
2)4008
3)4657.5
7-12 某商店负责供应附近1000户居民冬季的用煤。已知当地每户冬季平均用煤量为1500公斤,标准差是400公斤。该商店计划至少满足95%居民的用煤要求。问该商店在冬季来临前应准备多少煤?
解:1) 2156吨
2)900-820=80
7-13 某地居民月收入服从正态分布,均值为900元,标准差为500元。当地政府计划实行一项社会保障计划,对月收入最低的5%的居民提供补贴。问享受补贴的标准应定为多少?
答:享受补贴的标准应定为6.24年
7-14 某厂所生产的一种电器产品的寿命服从正态分布,均值是10年,标准差为2年。工厂计划规定在保修期内遇有故障可免费换新。厂方要求免费换新的产品数控制在3%以内,问保修年限应定为多长?
解: 根据n=30时的情形,可计算出σ=500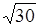 /0.675,由此计算出n=60时的Z=0.9545,结论是概率为0.663。
/0.675,由此计算出n=60时的Z=0.9545,结论是概率为0.663。
7-15 从某一总体中抽取n=30的随机样本,已知样本均值与总体均值之差在±500以内的概率是0.5036。问当样本大小为60时,样本均值与总体均值之差在±500以内的概率是多少?
解:根据两样本均值差的抽样分布的结论,两样本的均值差服从均值为零方差为0.5的正态分布。则结论是0.6744.
7-16 求总体N(20,3)的容量分别为10、15的两独立样本均值差的绝对值大于0.3的概率。
解:可以计算得到Z=0.86,结论是概率为0.61。
7-17 某总体中具有某种特征的个体的成数是0.40。如从该总体中抽取n=200的随机样本,并以样本成数来估计总体成数。问样本成数与总体成数之差在±0.03以内的概率是多少?
7-17 设总体X~N(1,4),求P(0≤X≤2)与 ,其中
,其中 为样本容量是16的样本均值。
为样本容量是16的样本均值。
解:随机变量在[0,2]之间的概率为0.3417。样本均值在[0,2]之间的概率为0.95。
7-18 在总体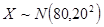 中随机抽取一个容量为100的样本,问样本平均值与总体均值的差的绝对值大于3的概率是多少?
中随机抽取一个容量为100的样本,问样本平均值与总体均值的差的绝对值大于3的概率是多少?
解:0.1336
7-19 对某机器生产的滚动轴承随机抽取196个样本,测得直径的均值为0.826厘米,样本标准差0.042厘米,求这批轴承均值的95%与99%的置信区间。
解:当1-α=95%时α=0.05,Z=1.96, 置信度为95%的置信区间为[0.820, 0.831]
当1-α=99%时α=0.01,Z=2.33, 置信度为99%的置信区间为[0.818, 0.834]
7-20 设正态总体的方差 为已知,问要抽取的样本容量n应为多大,才能使总体均值
为已知,问要抽取的样本容量n应为多大,才能使总体均值 的置信度为0.95的置信区间的长不大于L。
的置信度为0.95的置信区间的长不大于L。
解: 根据题意,有
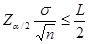 ,因此
,因此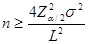 =
=
7-21 有人在估计总体均值时要求在置信度为99%的条件下保证样本平均数与总体均值之间的误差不超过标准差的25%。问应抽取多少样本?
解: 
第八章 假设检验与方差分析
8-1 什么是假设检验?其具体的步骤有哪些?
答:假设检验是先对总体参数提出某种假设,然后利用样本信息判断假设是否成立的过程。假设检验的一般步骤为:1.确定适当的原假设和备择假设;2.选择用来决定是否拒绝原假设的检验统计量;3.确定检验的显著性水平a;4.用显著性水平来确定拒绝原假设Ho的检验统计量的临界值和拒绝域;5.根据样本数据,计算检验统计量的值;6.可以将统计量的值与临界值进行比较,并做出决策:若统计量的值落在拒绝域内,拒绝原假设Ho,否则不拒绝原假设Ho;或者根据第5步的检验统计量的值计算P值,根据P值来确定是否拒绝Ho。
8-2 假设检验中显著性水平的含义是什么?它与置信度水平有何不同?
答:显著性水平是人们事先指定的犯第Ⅰ类错误的最大允许值。置信度越高,显著性水平越低,代表假设的可靠性越高,越好。
8-3 举例说明在指定的显著性水平下,假设检验的接受区域和拒绝区域分别指什么?
答:显著性水平是在进行假设检验时事先确定一个可允许的作为判断界限的小概率标准。检验中,依据显著性水平大小把概率划分为二个区间,小于给定标准的概率区间称为拒绝区间,大于这个标准则为接受区间。事件属于接受区间,原假设成立而无显著性差异;事件属于拒绝区间,拒绝原假设而认为有显著性差异。
8-4 假设检验可能出现的结果有哪几种?第I类错误和第II类错误各是什么?
答:第I类错误,又称弃真错误,即当原假设为真时却拒绝原假设。犯第I类错误的概率通常记为a。第II类错误,又称取伪错误,即当原假设为假时却没有拒绝原假设。第II类错误的概率通常记为β。
8-5 什么是单边假设检验?什么是左侧检验?什么是右侧检验?各在什么条件下使用?
答: 单侧检验。这种检验只注意估计值是否偏高或偏低。如只注意偏低,则临界值在左侧,称左侧检验;如只注意偏高,则临界值在右侧,称右侧检验。
8-6 什么是双边假设检验?在什么条件下使用?
答:双侧检验。如果检验的目的是检验抽样的样本统计量与假设参数的差数是否过大(无论是正方向还是负方向),就把风险平分在右侧和左侧。对所研究问题只需要判断有无显著差异或要求同时主要总体参数偏大或偏小的情况下使用。
8-7 某灯泡厂生产的灯泡的平均寿命是1120小时,现从一批新生产的灯泡中抽取8个样本,测得其平均寿命为1070小时,样本方差 =
=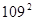 (
( ),试检验灯泡的平均寿命有无变化(
),试检验灯泡的平均寿命有无变化( =0.05和=0.01)?
=0.05和=0.01)?
解: 设样本所代表总体的均值为μ
形成原假设μ=1120,则备择假设μ≠1120
因n=8<30,计算检验统计量t=(1120-1070)/(109/2.83)=1.30
根据α=0.05,自由度为7,查表得到t’=2.365, 接受原假设,可以认为μ=1120
根据α=0.01,自由度为7,查表得到t’=3.499, 也接受原假设,可以认为μ=1120
8-8 为降低贷款风险,某银行内部规定要求平均每笔贷款数额不能超过120万元。随着经济发展,贷款规模有增大趋势。现从一个n=144的样本测得平均贷款额为128.1万元,S=45万元,用=0.01的显著水平检验贷款的平均规模是否明显超过120万元。
解:形成假设:
原假设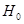 :μ≤120,则备择假设
:μ≤120,则备择假设 :μ>120
:μ>120
由于n=144,可以认为样本均值服从正态分布,Z=2.33
则原假设的接受区域为:(—∞,128.74],现在样本均值128.1落在接受区内,结论是未超过原规定。
8-9 正常人的脉搏平均为72次/分,今对某种疾病患者10人测得其脉搏为54 63 65 77 70 64 69 72 62 71(次/分)设患者的脉搏次数服从正态分布,试在显著性水平=0.05下检验患者与正常人在脉搏上有无显著差异?
解:形成假设:
原假设:μ=72,则备择假设:μ≠72
从观察数据得到样本均值66.7,样本标准差为6.46
由于小样本,用t检验:t=2.262
原假设的接受区为[67.3, 76.7],样本均值落在拒绝区,因此与正常人有明显差别。
8-10 从A市的16名学生测得其智商的平均值为107,样本标准差为10,而B市的16名学生测得智商的平均值为112,标准差为8,问在下这两组学生的智商有无显著差别?
解: 形成原假设: ,则备择假设:
,则备择假设: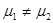
( )的均值为零,标准差可用计算
)的均值为零,标准差可用计算 的公式计算:=82,
的公式计算:=82,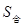 =9.055
=9.055
设检验的显著性水平为0.10,则t=1.697,原假设的接受区间为[-5.43, 5.43]
现两样本均值差为5,正好落在接受区内,故认为无差异。
8-11 用简单随机重复抽样方法选取样本时,如果要使抽样平均误差降低50%,则样本容量需要扩大到原来的( C )。(单选题)
A. 2倍 B.3倍 C.4倍 D.5倍
8-12 某产品规定的标准寿命为1300小时,甲厂称其产品超过此规定。随机选取甲厂100件产品,测得均值为1345小时,已知标准差为300小时,计算得到样本均值大于等于1345的概率是0.067,则在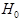 :μ=1300,
:μ=1300,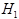 :μ>1300的情况下,有(A )成立。(单选题)
:μ>1300的情况下,有(A )成立。(单选题)
A. 若=0.05,则接受 B. 若=0.05,则接受
C. 若=0.10,则接受 D. 若=0.10,则拒绝
8-13 某种新型建材单位面积的平均抗压力服从正态分布,均值为5000公斤,标准差为120公斤。公司每次对50块这种新型建材的样本进行检验以决定这批建材的平均抗压力是否小于5000公斤。公司规定样本均值如小于4970就算不合格,求这种规定下犯第一类错误的概率。
解:根据题意容量为50的样本的标准差为17.14。
Z=(5000-4970)/17.14=1.77,查正态分布表,得到α=3.84%。这就是犯第一类错误的概率。
8-14 把学生随机地分为三组,一组采用程序化教育,一组采用录音教育,一组采用电视教育。然后测定各组学生对所学知识掌握的程度,所得分数如下:
教育方法 学生成绩
程序化 2,3,1,9,3,6,9,1,15
录音 2,9,15,6,9,12,9,13,9
电视 9,12,6,12,15,15,6,9,15
检验各种教育效果是否具有显著的差异(=0.05)?
解:用SPSS作方差分析,得到SSTR=14 .3 SSE=406.2 F=4.322 p=0.025
则在显著性水平为5%时,拒绝原假设,即不同教育方法的教学效果之间有明显的差异。
8-15 对于某一种疾病有三种治疗方法。下表是患这种疾病的人在三种不同的治疗条件下康复速度的记录。问不同的治疗方法对康复速度有无显著影响(=0.05)?
治疗方法 康复天数
A 3,8,6,9,7,4,9
B 7,6,9,5,5,6,5
C 4,3,5,2,6,3,2
解: 用SPSS作方差分析,得到SSTR=36 .857 SSE=64.286 F=5.502 p=0.014
则在显著性水平为5%时,拒绝原假设,即不同的医疗方法对康复效果的影响有明显的差异。
8-16 某电视台为了检验广告播放时间对观众收视人数的影响,对本台4个时间的收视人数进行了调查。对所得资料经计算机处理后得到如下表格。请在=0.10的显著性水平下检验广告播放时间对观众收视人数的影响是否显著。

解:形成假设(略)。
根据题目可以得到:SSTR=367 SSE=294 K-1=3 N=20
MSTR=122.3 MSE=18.375
可以计算得到F=6.66。 =2.46<6.66=F
=2.46<6.66=F
因此拒绝原假设,即不同播放时间对观众收视人数的影响差异是显著的。
8-17 为了对五个不同工厂生产的某种型号的电池的寿命进行评价,各抽取5个样品共得到25个样本进行试验。对试验结果做方差分析结果如下表。试在显著性水平为0.05的条件下,检验各厂家生产的电池寿命有无显著差异。

解:形成假设(略)。
根据题目可以得到:SSTR=259 SSE=156 K-1=4 N=25
MSTR=64.75 MSE=7.8 F=8.30
根据显著性水平0.05,查表得到的F临界值是2.80<8.30,
结论:不同工厂生产某型号电池的寿命有明显差异。
第九章 相关与回归分析
9-1 什么是相关关系?相关关系与函数关系之间有什么差异?两者有何联系?
答:相关关系是指某一现象与另一个或多个有联系的现象之间在数量上存在着一定的依存关系,但不是确定和严格的函数关系。函数关系与相关关系虽然是两种不同类型的变量依存关系,但是它们之间并无严格的界限。由于测量误差等原因,确定性关系在实际中往往通过相关关系表现出来;反之,当令人们对事物的内部规律了解得更深刻的时候,相关关系又可能转化为确定性的函数关系。
9-2 相关关系是如何恩类的?
答:1.按相关关系涉及的因素多少划分,可以分为单相关和复相关。2.按现象之间相关关系的方向划分,可以划分为正相关和负相关。3.按现象之间相关关系的程度分,可以分为完全相关、不完全相关和不相关。4.按现象之间相关关系的表现形式分,可分分为线性相关和非线性相关。
9-3 判断现象之间有无相关关系的方法有哪些?
答:判断现象之间有无相关关系的方法有:1.相关表;2.相关图;3.相关系数。
9-4 如何根据相关系数大小来测定相关关系的密切程度?
答:相关系数用希腊字母γ表示,γ值的范围在-1和+1之间。
γ>0为正相关,γ<0为负相关。γ=0表示不相关;
γ的绝对值越大,相关程度越高。
9-5 什么是线性相关和非线性相关?各举一例说明。
答:用变量表述现象时,研究现象所涉及的变量有两个,两个变量之间的地位是平等的,两个变量之间关系大致呈现为线性相关。例如,居民收入与支出之间的关系,就近似地表现为直线形式。又如人的身高和体重之间的数量关系等。
9-6 什么是回归分析?说明回归分析与相关关系之间的区别和联系。
答:回归分析是指对具有相关关系的现象,根据其相关形式,选择一个合适的数学模型(称为回归方程式),用来近似地描述变量间的平均变化关系的一种统计分析方法。
区别:1.相关分析所研究的两个变量是对等关系;回归分析所研究的两个变量不是对等关系,必须根据研究目的,先确定其中一个是自变量,另一个是因变量。2.对变量X和Y来说,相关分析只能计算出一个反映两个变量间相关关系密切程度的相关系数,而且计算中改变X和Y的地位不影响相关系数的数值;回归分析有时可以根据研究目的不同分别建立两个不同的回归方程:一个是以X为自变量,Y为因变量,建立Y对X的回归方程;一个是以Y为自变量,X为因变量,建立X对Y的回归方程。3.相关分析对资料的要求是两个变量都必须是随机变量;而回归分析对资料的要求是自变量是可以控制的变量(给定的变量),因变量是随机变量。
联系:1.相关分析是回归分析的基础和前提。如果没有定性说明现象间是否存在相关关系,没有对相关关系的密切程度做出定量判断,就不能进行回归分析。2.回归分析是相关分析的深入和继续。仅仅说明现象间具有密切的相关关系是不够的,只有进行了回归分析,拟合了回归方程,才有可能进行有关的分析和回归预测,相关分析才有实际的意义。因此,如果仅有回归分析而缺少相关分析,将会因为缺乏必要的基础和前提而影响回归分析的可靠性;如果仅有相关分析而缺少回归分析,就会降低相关分析的实际应用价值。只有把两者相结合起来,才能达到统计分析的目的。
9-7 零售商为了解每周的广告费与销售额之间的关系,记录了如下统计资料:
广告费X(万) 40 20 25 20 30 50 40 20 50 40 25 50
销售额Y(百万) 385 400 395 365 475 440 490 420 560 525 480 510
画出散点图,计算变量Y对X的相关系数,用最小二乘法计算出Y对X的一元线性回归方程,并在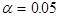 的条件下检验方程的有效性。
的条件下检验方程的有效性。
解:得到回归方程:y=343.706+3.221*X
R=0.635 作方差分析得到F=6.751 p=0.027
则在显著性水平为0.05的条件下,方程有效。
9-8 设对某产品的价格P与供给量S的一组观察数据如下表,据此确定随机变量S对价格P的回归方程,并在的条件下检验方程的有效性。
价格P(百元) 2 3 4 5 6 8 10 12 14 16
供给量S(吨) 15 20 25 30 35 45 60 80 80 110
解:得到回归方程:y=127.381+13.952*X
R=0.878 作方差分析得到F=26.786 p=0.01
则在显著性水平为0.05的条件下,方程有效。
9-9 依据下列统计资料,对某一企业的利润水平和它的广告费用之间的线性相关关系进行解释,得出回归方程,并在的条件下检验方程的有效性。
广告费用(万元) 10 10 8 8 8 12 12 12 11 11
利润(万元) 100 150 200 180 250 300 280 310 320 300
解:得到回归方程:y=-24.766+25.859*X
R=0.568 作方差分析得到F=3.807 p=0.087
则在显著性水平为0.05的条件下,方程无效。
9-10 随机抽取某城市居民的12个家庭,调查收入与支出的的情况,得到家庭月收入(单位:元)的数据如下表。试判断支出与收入间是否存在线性相关关系?求支出与收入间的线性回归方程,并在 的条件下检验方程的有效性。
的条件下检验方程的有效性。
收入 820,930,1050,1300,1440,1500,1600,1800,2000,2700,3000,4000
支出 750,850,920,1050,1220,1200,1300,1450,1560,2000,2000,2400
解:
设收入为自变量X,支出为因变量Y,用SPSS可得:
y=404.979+0.535X
R=0.987 方差分析F=364.854 p=000 所以回归方程有效
-
统计学学习感想
统计学学后感在经历了一个学期的学习之后,我们对《统计学》的学习也来到了最后的阶段。在这一个学期的学习中,有很多感想,也有很多收获。…
-
管理统计学读后感
管理统计学读后感最近闲暇之余有幸得到一本清华大学出版社李金林老师的管理统计学十分喜爱这是一本十分实用的书籍既具有系统的统计学知识又…
-
《统计陷阱》读后感
统计陷阱统计陷阱本书是美国著名的统计学家达菜尔哈夫的名著该书自19xx年出版至今多次重印并被译成多国文字是一本影响深远的经典性著作…
-
用统计学的眼光看世界-读《统计与真理》有感
用统计的眼光看世界读统计与真理有感用统计学的眼光看世界读统计与真理有感宇宙与其说是由逻辑不如说是由统计的概率来支配的题记1应用数理…
-
统计学感想
本人系福州大学统计学专业的一名学生于20xx年6月27日7月8日到福建省统计局科研所认识实习在两周的时间里我所做的每一项工作都是以…
-
《管理学》读后感
管理学读后感国本093班20xx0501118石硕硕这学期我读了尤利群的管理学写下了我的体会希望我写的一些感受能够让更多的同学认真…
-
罗宾斯管理学读后感
罗宾斯管理学读后感斯蒂芬P罗宾斯博士是美国著名的管理学教授组织行为学的权威他在亚利桑那大学获得博士学位罗宾斯博士的实践经验丰富学识…
-
每天学点管理学读后感
每天学点管理学读后感管理学是系统研究管理活动的基本规律和一般方法的科学它是人类近代史上发展最迅速对社会经济发展影响最大的一门学科自…
-
企业管理学读后感
读ltlt企业管理学gtgt有感这学期我们会计班跟财管班开了企业管理这门课这门课的内容较管理学来讲更细一些他是对于企业这个管理对象…
-
非人力资源经理的人力资源管理读后感
非人力资源经理的人力资源管理读后感通常人们认为人力资源管理主要是人资部的事情在读了非人力资源经理的人力资源管理后我感受颇深让我对管…
-
趣味管理学读后感
趣味管理学读后感李石华的《趣味管理学》是一本比较有趣的管理学著作,他把管理知识和故事结合得巧妙,赋予管理学以趣味。将枯燥的管理学方…