对外汉语话题:购物
对外汉语教学设计
——购物 第一课时2014.01.04
教学内容:
1. 关于颜色的生词:白色、黄色、橙色(橘色)、红色、粉色、绿色、蓝色、紫色、棕色、灰色、黑色。
2. 关于着装的生词:帽子、牛仔帽、遮阳帽、围巾、领带、手套、皮手套、女装、旗袍、晚装、西装、棉服、羽绒服、大衣、夹克、毛衣、衬衫、T恤衫、皮带、裤子、牛仔裤、裙子、短裤、睡衣、内衣、背心、泳装、运动装、运动衫、运动裤、运动背心、(中短)袜子、长筒袜、裤袜、鞋子、高跟鞋、运动鞋、靴子、皮鞋、凉鞋、拖鞋、
3. 数量词:一顶、一个、一件、一套、一双、一副、一条。 教学重点:
1.十一个关于颜色的生词。
2. 关于着装的生词及相应的数量词组:一顶帽子、两条围巾、三双(一副)手套、四条领带、五件女装、六件旗袍、七套西装、八件棉服、九件羽绒服、十件大衣、一件夹克、一件毛衣、一件衬衫、一件T恤衫、一条皮带、一条裤子、一条牛仔裤、一条裙子、一条短裤、一套睡衣、一套(件)内衣、一套泳装、一套运动装、一双袜子、一双鞋子、一双高跟鞋、一双运动鞋、一双皮鞋、一双凉鞋、一双拖鞋。
3. 运用简单的日常会话对以上重点词汇进行操练,帮助学生记 1
忆。
教学难点:
分清衣服的类型并且准确用相应的数量词。
教学过程
1. 复习导入:
A. 问候和自我介绍。
下午好,我叫April。你叫什么名字?认识你很高兴,……
B. 复习。
我今年36岁。你多大?我的是19xx年2月22号出生,属马。你呢?你知道中国的十二生肖是什么吗?
因为我属马,今年又是马年也就是我的本命年。所以我要穿红色的东西。我要买红色的毛衣,红色的鞋子,红色的袜子。红色代表喜气,会带给我幸运。
2. 新课。
A. 学习颜色的生词
(出示红色的东西告诉学生)这就是红色。
提问:你还知道那些颜色的汉语说法?(学生回答,教师板书)学生说不出汉语的用英语说。
练习:
a. 说颜色的生词。出示色笔,让学生回答是什么颜色。
b. 游戏:抢答图片中是哪个国家的国旗并说出国旗的颜色。 c. 提问:我喜欢白色,你喜欢什么颜色?这是什么颜色?学员 2
之间互相问这些问题。你还能问什么关于颜色的问题?(启发学生提问,造句。)
d. 在中国过春节最常见到的颜色就是红色。有红春联,给孩子的红包,红衣服,各种红色装饰品。说说在德国重要的节日是什么?在国界的时候最常见的颜色是什么?
B. 学习关于着装的生词。
刚刚我说过了,今年是马年我的本命年,所以我要穿红色的东西。请给我提议些建议我可以穿红色的什么?(用汉语)说说我们日常穿的服装用汉语怎么说。和学生边讨论边学习所有关于着装的生词。同时交代给学生这些名词前面相对应的数量词。
练习:
a. 练习说数量词加颜色的短语。如:一条蓝色的牛仔裤、两双白色的短袜等等。
b. 我的大衣是黑色的,你的是什么颜色?你有蓝色的围巾吗?你有几双黑色的皮鞋?……
3. 巩固练习
游戏:听音圈出所听到的图片。(两个或三个人一组比赛) 3
第二篇:面向对外汉语教学的话题聚类研究
面向对外汉语教学的话题聚类研究
刘华
(暨南大学 华文学院/海外华语研究中心,广州 510610)
摘要:针对对外汉语教学中报刊阅读“话题课”的两个关键问题:话题聚类、话题词聚类与分级,本文描述了一个基于数据挖掘中文本分类和聚类方法的辅助软件系统。系统能将新闻语料自动按话题聚类,并自动聚类出与话题相关的词语集合。
关键词:报刊阅读 话题 语料库 文本分类 词语聚类
Studies on Topic Clustering for teaching Chinese as a second language
Liuhua
(College of Chinese Language and Culture, Jinan University, Guangzhou, 510610)
Abstract: aim at two pivotal problem in teaching Chinese as a second language: topic clustering、topic words clustering and grading, this paper describes a assistant software, which can clusters news corpora and correlative words according to topic automatically.
Key words: newspaper reading, topic, corpus, text classing, words clustering
在对外汉语教学中,报刊阅读是课堂教学之外的另一条有效渠道。本文针对报刊阅读“话题课”的两个关键问题:话题聚类、话题词簇聚类与分级,描述了一个基于数据挖掘中文本分类和聚类方法的辅助软件系统,并给出了相应的实验结果,结果证明该系统快速有效,对对外汉语教学的教材编写、词表建设也有较大的意义。
1问题分析与目标描述
1.1报刊阅读与话题课
报刊阅读课是为中、高级汉语水平学生开设的专门技能课,目的是培养学生阅读中文报刊、杂志的能力。目前报刊阅读课中多采用“话题课”的形式进行,教师或师生选取一个社会现象或新闻主题作为话题,在课堂上进行讨论,以锻炼学生高级阅读和成段表达的语言能力。 例如,“北语-网上北语”对“学历教育课程”中的“中国报刊语言基础”课程介绍如下: “教学内容 介绍中国报刊常用词汇、句式、结构以及相关社会文化背景知识,……每课都介绍一个相关网站,提供给学生作网上浏览;引导阅读相关主题的报刊文章;……相关主题包括中国外交、国际关系、对外贸易、中国社会状况、汉语热、能源、交通、航空航天、粮食问题、生活质量、饮食文化、毒品犯罪、艾滋病、在就业工程等。
……
教学目标 引导外国留学生由浅入深、循序渐进地阅读中国报刊文章,掌握中国新闻报道及各种报刊文体的特点,了解中国社会各方面的情况。学完本课程后,学习者能够自主搜寻并获取自己感兴趣的报刊新闻。”
1.2话题与话题词簇
1.2.1话题
人们交谈时总是从一个大家都熟悉的话题开始,然后再各自补充自己所知道的有关这个话题的新情况,这是一个从旧信息到新信息、从已知到未知的过程。话题是交际的出发点或对象,也是交际的某种范围。
话题(topic)是很难固定的,甚至很难找到一个令人满意的定义,它往往与主题(subject)密切相关(Bygate,1987,P62;BrownandYule,1983,p62),例如话题跟踪与话题识别中的“话题”。二者关系密切,话题与具体事件相关,主题则是话题的群集;事实上我们常常如此说“关于早恋这个话题我不想多说”,显然,话题和主题的区分存在一个度的问题。
话题是思想和语言交际的中心,如果思想不能紧扣话题(我们通常叫主题),就会犯“南辕
北辙”的错误,没有话题(主题)的交流是一个没有意义的交流。从这个意义上说,话题是文本内容的集中体现,是一系列文本表达对象的集中描述,也是交际交流的总纲。
在本研究中,我们将话题定义在一个宽泛的范围内,并不强调与主题的区别,指的就是文本分类的划分结果,不管划分的是概念层次高的大类,如:“体育”,还是具体专指性强的小类,如:“科技-科普生活-航空航天-火星登陆”。
1.2.2话题词簇
话题词簇指的是与某一话题紧密关联的词语群,例如,话题“非典”的话题词簇可能是:“非典、非典病毒、非典患者、非典型肺炎、传染性非典型肺炎、非典型性肺炎、非典疑似、抗击非典、抗非、防非、发热、发烧、发烧门诊、体温、冠状病毒、肺炎、疑似、病例、隔离、隔离区、果子狸、SARS、萨斯、公共卫生事件、世界卫生组织、口罩、小汤山……”
话题词簇根据其在该话题领域中的流通程度或使用频率可划分为两类:
A.描述该主题所必须的、常见的词语,我们称之为话题通用词。例如:垒球的话题通用词可能包括“球员、球队、比赛、得分、教练、手套、安打、垒……”。
B.该话题领域专用的词语,我们称之为话题术语词。例如:垒球的话题术语词可能包括“安全打、安全上垒、二垒、二垒打、后摆投球法、绕环投球法、牺牲打、正面投球法……”。
1.3报刊阅读课分析与目标描述
1.3.1报刊阅读课素材现状
目前,对外汉语教学界很多学者和教师针对报刊阅读课编写了许多教案教材。
报刊阅读课的取材通常可分为两种:
A 利用现成的教材
这一类的教材很多,往往是按话题或类别收集相关报刊杂志的文章。例如:
《中国概况》(修订版),王顺洪。教材分 14 个专题系统全面介绍中国的国土、历史、人口、民族、政治制度、经济、科技、教育、传统思想、文学、艺术、习俗、旅游、国际交往。
《当代话题》选定如下几个专题:中外交往中国社会、经济政策社会进步、城市建设民风、民俗的演变婚姻观、家庭观妇女地位、儿童教育老年人的生活消费观念公共道德社会生活、人际交往环境及动物保护健身、美容情趣爱好,每个主题包括两到三个子话题。
《中文报刊阅读教程》(德文注释),周上之等编著。课文均选自原版中文报刊,以新闻报道为主,内容涉及当今中国政治、民主法制、经济生活、文化教育、家庭婚姻、医疗卫生、环境保护等社会生活各个方面。
《报纸上的中国——中文报纸阅读教程》(上、下),王海龙编著。教材的选文涵盖了包括中国内地、香港、台湾以及世界各地的华文报纸。
《新编汉语报刊阅读教程》(初、中级本),吴丽君等编著。课文均选自 1998、1999、2000 年国内有代表性的报刊,内容涉及政治、经济、军事、外交、文化、娱乐等方面,包括新闻报道、人物专访、时事评论、特写、通讯等类型。
《话说今日中国——高级教程》,刘谦功编著。教材以话题为线索编排,共有 20 个话题,内容选取当今中国的热门话题。
其他如[《报刊阅读教程》,彭瑞情等编著,北京语言文化大学出版社,1999.01]、[《高级汉语口语──话题交际》(重印),章纪孝,北京语言文化大学出版社,1995-1-1 ]、[《话题口语》郑国雄等,北京语言文化大学出版社,2002]、[《报刊语言教程》,白崇乾等,北京语言文化大学出版社,1999-03]、[《话说今日中国》,刘谦功,北京语言文化大学出版社,1999-05]
这种做法的缺陷是素材更新太慢,内容陈旧,落后于时代的发展,特别是在网络时代的高速发展,不能及时反映当前时事热点和社会发展状况;素材可能由于编写者的主观因素而偏向某些话题,没有考虑学生的话题兴趣,不能真正照顾学生的需求和主动性;进而影响词汇教学。
F 一种是随时现场取材,以近期甚至当天的报刊为材料,及时生鲜;或者根据学生感兴趣
的话题,从网站上搜索与之相关的最新资料、背景知识以及相关内容,作为教学材料。
这种做法的优点显而易见,但真正实现起来,特别是当希望电子备课、批量备课时,有较大难度。很多老师试图通过个人的努力来改变这种现状,但这需要花费大量的精力和时间,而且各自为政,存在大量的重复劳动;并且报刊新闻更新很快,往往辛辛苦苦收集的素材过段时间就失去了实效性,而且社会变化很快,新事物、新话题层出不穷,网络上的信息铺天盖地,单凭手工操作,很难保证教学素材的时效性。
1.3.2报刊阅读课词汇情况
语言是发展的,词汇更是发展最活跃的部分。报刊新闻因为其特有的实效性,其中反映的词汇发展情况尤为明显。滞后的教学素材和手段显然降低了词汇教学的效果。
报刊阅读课一般面向的是高年级学生,他们已经具备一定的汉语能力,但是相对于信息量高、文化性强、词汇量大的报刊文本来说,还是不够的。就词汇来说,前期学的基本上都是生活中的常见词,而报刊新闻有很多与该新闻话题相关的领域词(该话题领域的词),有的甚至是该领域的术语。虽然报刊阅读课可能并不要求学生完全掌握,但我们还是希望该话题领域中最基本、最常用的那些词汇能为学生掌握,以后他们遇到相同话题时就能基本进行阅读,而那些话题领域性太强的术语可以作为阅读课的背景知识为学生了解即可。
因此,如何根据话题确定话题词簇是一个关键问题。
1.3.3目标描述
综上所述,我们可以看到,目前报刊阅读课素材的关键问题在于如何快速准确地获得相关话题聚类后的文章集合;词汇方面则集中在如何自动获取话题词簇,如何区分开话题通用词和话题术语词。
具体来说,以上问题(目标)描述如下:
1.3.2.1话题聚类:
所谓“相关主题的报刊文章”,指的就是与某一话题相关的同类文章,相当于网页的“同主题文章”或“相关链接”,因此,这一个问题也就是报刊语料的话题聚类。师生共同选择一个感兴趣的话题后,利用现成的分类语料库或语料采集软件应该能够即时获得该话题的相关文集语料。
本质上,这是一个文本分类和聚类的问题。
1.3.2.2词语聚类:
话题词簇指的是与某一话题紧密关联的词语群,因此,如何按照话题聚集该领域的相关词语,并根据其领域流通度(领域使用频率)划分话题通用词和话题术语词是该问题的核心。实际上,该问题又可分为两个子问题:
A:话题词语聚类
B:话题词语分级
2系统实现及结果分析
2.1话题聚类
话题聚类本质上是一个文本分类的问题。文本分类属于有指导的机器学习,它利用预定义的文本类别和训练文本学习到分类模型,从而确定新文本的类别。一般包括动态的自动聚类和静态的自动归类。根据分类知识获取方法的不同,可以有两大类:基于知识的和基于统计的。基于知识的方法主要依赖领域专家知识,需要领域专家预先编制大量的推理规则作为分类知识,优点是分类体系细致合理,分类正确率较高,适用于专业领域的知识组织和管理;但实现比较复杂,开发费用相当昂贵,领域性太强,不易移植,管理和扩展费用很高,难以保证一致性和准确性。基于统计的方法是文本分类应用最多的方法,它忽略文本的语义结构,仅将文本作为互不相关的特征项集合来看待,利用加权特征项构成向量表示文本,利用词频或词频进一步计算的信息对文本特征进行加权。基于统计的分类系统实现起来比较简单,分类快捷,来源于真实文本,可信度高,准确度能够满足一般应用的要求。
我们已经构建了一个超大规模的分类语料库,分类后的语料库共60万个文件,约6亿字。分类主题层级最多为4级,如“科技_电脑_软件_操作系统”,总共类目两百多个,小类具体到某个
主题(话题),如“体育-运动会-奥运会”。大类15类,包括:国际新闻、国内新闻、社会新闻、军事新闻、经济、科技、体育、教育、娱乐、旅游、汽车、文艺、游戏、房产、生活男女。
在此基础上,我们已经实现了一个层级多标记、自适应的文本分类系统。系统不仅可以完成上面所说的层级分类(244个),能为类目交叉的文本标记上多个类目名称,如一篇“房市”的文章,可能在分类系统中会同时标记上“经济_行业经济_房市”、“房地产_房市”两个标记,在约3万篇测试集上(共15个大类,244个小类),取得了91%以上的准确率和召回率。而且还能够根据用户需求,动态增加用户自定义的类目主题(话题),在系统原有基本类目主题的基础上,动态更新,成为一个活的系统。例如,用户自定义的“不良信息”主题的分类准确率近90%。(分类语料库及自动分类系统详情另文介绍)。
2.2词汇聚类
2.2.1利用特征提取方法进行词汇聚类
在文本自动分类中,关键的一个技术是特征提取。特征提取的步骤包括:词语切分,词频统计,加权计算和特征选择(二者通常结合在一起进行)。
词语切分一般采用最大匹配法,文本切词后要进行词语的词频统计,词频统计也是其它权重计算和特征选择的基础。权重计算和特征选择有很多计算公式,如信息增益、期望交叉熵、文本证据权等,其中最著名的是TFIDF公式。
基于TFIDF的公式本质上反映了词语区分文档内容属性(类别、话题)的能力,一个词语(如虚词“的”、“我们”、“在” ……)在整个文档集出现的范围越广,在文档集的所有类别的语料中散布的越均匀,其区分文档属性的能力越低,不能作为某一个类别的领域词语。另一方面,一个词语(如“射门”、“教练”……)在某些特定类的文档集(如“体育”)中出现的频度越高,在其它类文档集(如“经济”、“军事”……)中出现的频度越低,说明它在区分该类文档集的内容属性(“体育”类)方面的能力越强,它们可以作为“体育”类别中的领域词语。因此,在计算词语在某一类(如“体育”)中的TFIDF值之后,将其按倒序排列,那些具有强话题区别能力的词语会排在最前面,如“比赛”、“球队”……;而每一话题中皆均匀出现的词语(话题区别能力弱的词语)将会排在后面,如虚词“的”、“我们”、“在” ……。根据此原理,我们可以通过计算词语的TFIDF值来将某一特定话题(如“体育”)中的特征词(如“射门”、“球队”……)抽取出来,从而达到词语的按话题聚类的目的。
后来有很多人对TFIDF进行了改进,如[Roberto Basils,1999]提出的TF*IWF*IWF公式;[陈克利,2003]对TF*IDF和TF*IWF*IWFF公式进行了分析并作了一些改进,提出了一个新公式: w(wi,cj)?
其中,?pjij?pi2N(wi)?pij??)??pij?log(??jTij2 pijTij=ij,Lij是类Cj含有的所有词的次数之和,是词i在类Cj出现的次数;
,m为类别数;N(wi)是出现wi的训练文本数,N是总训练文本数;n>=1。
2.2.2词语聚类实现
具体实现步骤如下:
Step1:双向最大切分。切分底表对特征提取至关重要,如果需要提取的特征词不在底表中,则无法提取出该特征词,我们的底表包含三十二万词条,含领域词语二十五万(关于切分底表的详细情况和切分结果对比的试验数据另文介绍。)
Step2:统计词次。统计时根据位置动态加权。
Step3:权重计算。按照[陈克利,2003]的公式计算每个词在类中的权重,n(n>=1)参数主要用来调节词频的影响,当n取值小时,倾向于词频大的词;当n取值大时,则词频的影响减弱,pi??pjij
倾向于词频小的词。
Step4:特征选择。通过设定阈值来确定不同文档类所对应的特征向量。
2.2.3词语聚类结果分析
上文(1.3.2.1节)列举了话题词簇中两个关键性的问题: A:话题词语聚类 B:话题词语分级
第一个问题已经解决,第二个问题是个再选择问题,上面已经提到可以通过改变n的取值来调节词频的影响,当n取值小时,倾向于词频大的词,即可获得话题内最基本、普通的词语(话题通用词);当n取值大时,则词频的影响减弱,倾向于词频小的词,可获得专业性很强的学科术语(话题术语词),因此这个问题也可以得到很好的解决。
我们分别对n取1、2、3、4、5、6不同的值,然后与该类未作权重计算的频率进行对比,观察权重计算及n值对特征提取的影响(限于篇幅,只列举了n为1、3、6时的情况)。下表在财经领域对五种待对比的分表中各取前30个词,按降序排列。频率这一列指只对财经领域分词后统计词频得到的分表(前30个),未做权重计算;差集指n=6时的词簇减n=3时的词簇后的余集。
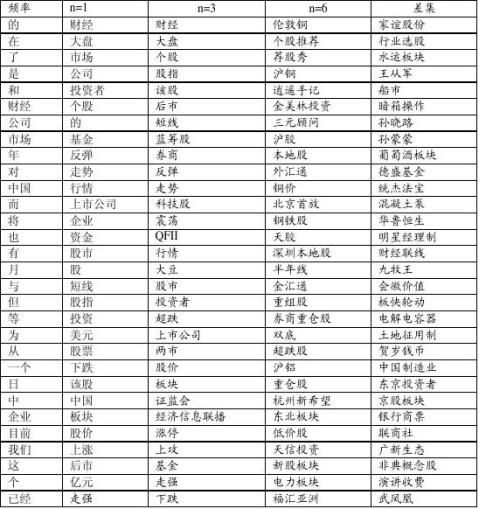
高频常用词。通过对n取不同值时词语的观察,权重计算时n取值对词语的领域流通度(或领域使用频率)的影响显而易见,n取1时,区别度基本可以,基本上为财经领域中常用的词语,只出现了如:的、中国这样的词语;随着n值的加大(n=6),经济领域中高区别度的词语大量出现,
很多基本上都是经济领域中独有的词语,如:半年线、金汇通、重组股、券商、重仓股、双底、超跌股、外汇通等。差集中的词也是区别度很高的词语,并且能够补充n=3时领域通用词中没有出现的词语。
以经济类为例,词语聚类的准确率如下:从32万词语中,当取自动聚类结果(n=3)的前2000个词条时准确率为95.8%,3000时95.6%,4000时95.3%,5000时94.7%。
利用上述方法,我们系统地构建了一个大规模的领域词语的知识库,包含与分类主题对应的领域词语表(即话题词簇)共两百多个。这些分类主题包括大的类别(如“体育”、“科技”等)和细致的话题(如“科技-科普生活-非典”),例如:
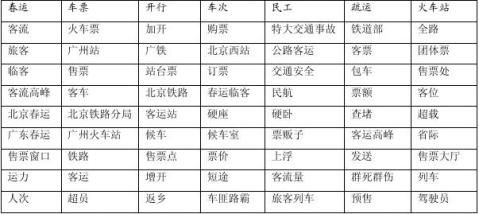
词簇(特征提取及词汇聚类详情另文介绍)。
3结语
综上所述,本文描述了一个基于数据挖掘中文本分类和聚类方法的对外汉语教学辅助软件系统。在具体的对外汉语教学中,该系统主要用于以下几个方面:
对外汉语教学的教材编写:目前,对外汉语教材,特别是报刊阅读课的教材,都是人工收集报刊或网站上的相关主题的文章编辑而成,人力物力耗费较大,而且更新很慢。使用该系统,教材编写专家可以快速及时地获得按话题分好类的文章,大大节省了人力和时间。
教学词语按话题聚类分级:利用本系统提供的文本特征提取方法可以快速自动聚类出与话题相关的词语集合,并将词语按流通度分级,有利于教师选择与话题相关的词语集合进行教学。
词表建设:目前,对外汉语教学和测评用的词表,对所有国家和所有专业领域都是一样的。而实际上,不同国家的学生需要不同的词表(国别化对外汉语教学,甘瑞瑗,2004),不同专业领域也需要不同的领域词表,例如,正在进行的HSK商务(文秘、旅游等)就需要构建相应的词表。
-
关于对外汉语专业开题报告
关于对外汉语专业开题报告11选题背景笔者在上海外国语大学国际交流学院教书的过程中时常会遇到一些因儿化而引起的小问题比如学生会问为什…
-
对外汉语开题报告
开题报告院系文学院专业对外汉语题目对外汉语教材建设1本课题的研究现状整个对外汉语教材的发展可分做三个阶段150年代到70年代纯结构…
-
对外汉语毕业论文 开题
北华大学文学院毕业论文开题报告课题名称对外汉语教学词汇教学技巧研究专业对外汉语学科课程与教学论姓名张晶091班29号指导教师曲鸿雁…
- 对外汉语本科生开题报告格式
-
对外汉语教学研究毕业论文开题报告
本科生毕业论文开题报告企业经营沙盘模拟实战课程报告一、本课题研究的目的和意义文化教学是对外汉语教学的重要组成部分,掌握汉语的文化因…
-
工作总结范例
一、办公室的日常管理工作。办公室对我来说是一个全新的工作领域。作为办公室的负责人,自己清醒地认识到,办公室是总经理室直接领导下的综…
-
我区商贸工作总结
按照年初全市经济和商贸工作会议精神以及我区经济工作总体安排,我们把发展第三产业作为全区经济工作的重点,使辖区第三产业得到平稳发展,…
-
体育课期末总结
时间过的真快,不知不觉间一个学期已经快要过去了,体育课也开始接近尾声,除了几节理论课之外,我们基本上已经没有了在室外上体育课的机会…
-
公司优秀事例学习总结
公司优秀个人、团体事迹学习总结坚守岗位,敬忠职守,团结奉献,顾全大局,这不仅是作为员工的优良职操,更是公司“蚂蚁精神”的实质。而我…
-
二次根式知识点总结大全
二次根式【知识回顾1.二次根式:式子a(a≥0)叫做二次根式。2.最简二次根式:必须同时满足下列条件:⑴被开方数中;⑵被开方数中;…