hadoop总结
Hadoop
概念:
Hadoop是一个能够对大量数据进行分布式处理的软件框架!
Hadoop的特点:
1.可靠性(Reliable):hadoop能自动地维护数据的多份副本,并且在任务失败后能自动地重新部署(redeploy)计算任务。
2.高效率(Efficient):通过分发数据,hadoop可以在数据所在的节点上并行的(parallel)处理它们,这使得处理非常的快速。
3.扩容能力(Scalable):能可靠的(reliably)存储和处理千兆字节(PB)数据。 4.成本低(Economical):可以通过普通机器组成的服务器群来分发以及处理数据。这些服务器群总计可达数千个节点。
{简单来说: 1.可靠性 (体现在它维护多个工作数据的副本,确保节点宕掉了重新进行分布式处理)
2.高效性(体现在它通过并行(计算机同时执2个或者多个处理机的一种计算方法)的方式处理数据,从而加快了数据处理速度)
3.可伸缩性(能处理PB级别的数据量)
4.廉价性 (它使用了社区服务器,因此它的成本很低,任何人都可以去用)
}
它实现了一个分布式文件系统,简称之为HDFS
? 以真实的电信详单分析程序为主线,讲解Hadoop,Hbase,Hive在大数据处理的应用场
景与过程。
? 通过此课程,你能
1. 掌握Hadoop基本知识,进行Hadoop的HDFS和MapReduce应用开发,搭建Hadoop
集群。
2. 掌握Hbase基本知识,搭建Hbase集群,Hbase的基本操作
3. 掌握数据仓库基本知识,用Hive建立数据仓库,并进行多维分析
Hadoop核心项目:HDFS(用于存储)和MapReduce(用于计算)
Hdfs:分布式文件系统
概念: Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。

内部机制就是将一个文件分割成一个或多个块(一个block块:64M),这些块被存储在一组数据节点中
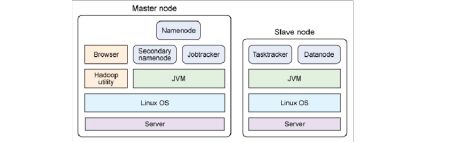
1.Hdfs的架构
? 主从结构
? 主节点,只有一个: namenode
? 从节点,有很多个: datanodes
? namenode负责:
? 接收用户操作请求
? 维护文件系统的目录结构
? 管理文件与block之间关系,block与datanode之间关系
? datanode负责:
? 存储文件
? 文件被分成block存储在磁盘上
? 为保证数据安全,文件会有多个副本
Namenode/DataNode/SecondaryNameNode分别的作用 Namenode包括:(hdfs-site.xml的dfs.name.dir属性)
① fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
② edits:操作日志文件。
③ fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中。
DataNode包括:(hdfs-site.xml的dfs.replication属性)
① 提供真实文件数据的存储服务。
② 文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是
size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。HDFS默认Block大小是64MB,以一个256MB文件,共有256/64=4个Block.
③ 不同于普通文件系统的是,HDFS中,如果一个文件小于一个数据块的大小,并不占
用整个数据块存储空间
④ Replication。多复本。默认是三个
SecondaryNameNode包括:(hdfs-site.xml的dfs.replication属性)
① HA的一个解决方案。但不支持热备。配置即可 (HA 集群(High Availability, 高可用性集群)是集群中较常见的一种,当硬件或软件系统发生故障时,运行在该集群系统上的数据不易丢失,而且能在尽可能短的时间内恢复正常运行。)
② 执行过程:从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生
成新的fsimage,在本地保存,并将其推送到NameNode,同时重置NameNode的edits. ③ 默认在安装在NameNode节点上,但这样...不安全!
1.***NodeNode对DataNode的心跳和块报告的管理
namenode节点负责处理所有的块复制相关的决策。
它周期性地接受集群中数据节点的心跳和块报告。
一个心跳的到达表示这个数据节点是正常的。
一个块报告包括该数据节点上所有块的列表。
2.***HDFS中文件副本放置策略: 复制副本数为3(一般情况下)
HDFS的副本放置策略是:
第一个副本放在本地节点
第二个副本放到本地机架上的另外一个节点
第三个副本放到不同机架上的节点。
这种方式的优势:减少了机架间的写流量,从而提高了写的性能
补充:数据中心的服务器按形态:
1.塔式服务器
优点:
价格低,主板可扩展性强
缺点:
占用的机架空间大,不便于挪动
2.

机架式服务器

优点:
占用的机架空间小,单位空间可放置更多的服务器,便于机房内统一管理,服务器移动非常方便
缺点:
对机房的制冷要求较高,需要,不断的制冷散热;服务器内部空间限制,扩充性受
限制
3.刀片式服务器
优点:
集成化、高密化、主体结构具有标准化机箱(称为”刀箱“);刀箱内部可以插上多块”服务器刀片”单位,每个服务器刀片就是一个独立的服务器
缺点:
由于计算密度成倍提高,对单机柜的供电功率以及制冷方式提成更高要求
从网络设计上看,机架式服务器和刀片服务器已成为数据中心主要的服务器形态 机架服务器接入网络具备高可用性、高可扩展性
刀片服务器接入网络具备防”流量黑洞“的特性(周期性的对交换机各口进行状态检查,发现接口出现故障,就会自动shutdown其上的所有端口,刀片服务器就会把流量切换到另一个刀片交换机相连的网卡上,从而避免了”流量黑洞“)
2.可以简单的理解(用于存储) 它包括: 索引 + 数据(例如: /root /result.txt 索引就是/root/result.txt存放在NameNode中 + 数据就是索引指向DataNode所对应的数据块)
MapReduce:并行计算框架
概念:
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算
概念"Map(映射)"和"Reduce(化简)"
简单来说:
Map映射:一个映射函数就是对一些独立元素组成的概念上的列表
例如:如果在一次测试成绩的列表,我们发现每一个学生的成绩都被高估了1分,我们可以定义一个“减一“的映射函数,用来修正这个错误: 事实上,每个元素都是被独立操作的,而原始列表没有被更改,因为这里创建了一个新的列表来保存新的答案。这就是说,Map

操作是可以高度并行的,这对高性能要求的应用以及并行计算领域的需求非常有用。
Reduce简化:化简操作指的是对一个列表的元素进行适当的合并
例如:如果有人想知道班级的平均分该怎么做?我们可以定义一个“平均值“简化函数来计算得到我们想要的结果:
通过让列表中的元素跟自己的相邻的元素相加的方式把列表减半,如此递归运算直到列表只剩下一个元素,然后用这个元素除以人数,就得到了平均分。)。虽然他不如映射函数那么并行,但是因为化简总是有一个简单的答案,大规模的运算相对独立,所以化简函数在高度并行环境下也很有用。
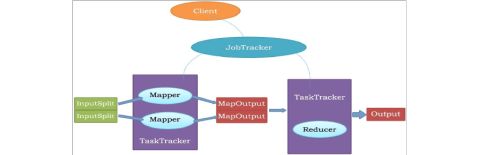
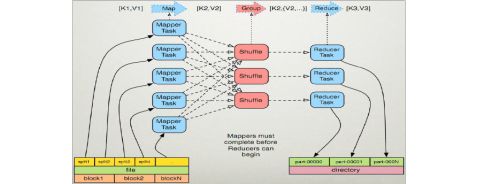
1. MapReduce的架构
? 主从结构
? 主节点,只有一个: JobTracker
? 从节点,有很多个: TaskTrackers
? JobTracker负责:
? 接收客户提交的计算任务
? 把计算任务分配给TaskTrackers执行
? 监控TaskTracker的执行情况
? TaskTrackers负责:
? 执行JobTracker分配的计算任务
JobTracker
负责接收用户提交的作业,负责启动、跟踪任务执行。
JobSubmissionProtocol是JobClient与JobTracker通信的接口。
InterTrackerProtocol是TaskTracker与JobTracker通信的接口。
TaskTrackers
负责执行任务。(二者的心跳通信是通过接口InterTrackerProtocol实现的;在TaskTracker执行过程中,通过心跳机制会不断的向JobTracker汇报自己的执行情况,供JobTracker做出决策)
JobClient
是用户作业与JobTracker交互的主要接口。
负责提交作业的,负责启动、跟踪任务执行、访问任务状态和日志等。
2.可以简单理解(用于计算)
3.MapReduce(MR)的使用 我们使用mapreduce:仅仅只是通过索引,然后拼凑数据块,达到我们想要的结果而已
mapreduce可以大体拆分为 mapper + reducer 这个两个处理过程,其他的基本上我们不需要操作,它默认帮我们操作
MapReduce(MR)执行流程图
MR由两个阶段组成:
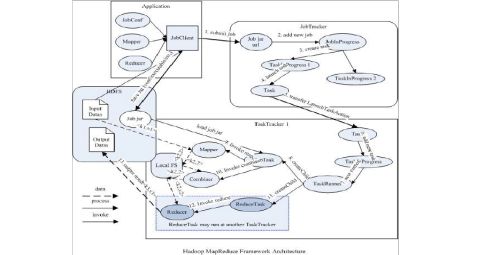
Map和Reduce,用户只需要实现map()和reduce()两个函数,即可实现分布式计算,非常简单。
1. map任务处理
1.1 读取输入文件内容,解析成key、value对。对输入文件的每一行,解析成key、value对。每一个键值对调用一次map函数。
//指定读取的文件位于哪里 FileInputFormat:
FileInputFormat是所有以文件作为数据源的InputFormat实现的基类,FileInputFormat保存作为job输入的所有文件,并实现了对输入文件计算splits的方法。至于获得记录的方法是有不同的子类——TextInputFormat进行实现的。
InputFormat 负责处理MR的输入部分.
有三个作用:
? 验证作业的输入是否规范.
? 把输入文件切分成InputSplit.
? 提供RecordReader 的实现类,把InputSplit读到Mapper中进行处理. InputSplit
◆在执行mapreduce之前,原始数据被分割成若干split,每个split作为一个map任务的输入,在map执行过程中split会被分解成一个个记录(key-value对),map会依次处理每一个记录。
◆FileInputFormat只划分比HDFS
block大的文件,所以FileInputFormat划分的结果是这个文件或者是这个文件中的一部分.
◆如果一个文件的大小比block小,将不会被划分,这也是Hadoop处理大文件的效率要比处理很多小文件的效率高的原因。
◆当Hadoop处理很多小文件(文件大小小于hdfs block大小)的时候,由于FileInputFormat不会对小文件进行划分,所以每一个小文件都会被当做一个split并分配一个map任务,导致效率底下。
例如:一个1G的文件,会被划分成16个64MB的split,并分配16个map任务处理,而10000个100kb的文件会被10000个map任务处理。
FileInputFormat.setInputPaths(job, INPUT_PATH);
//指定对输入数据进行格式化处理的类
TextInputFormat
◆TextInputformat是默认的处理类,处理普通文本文件。
◆文件中每一行作为一个记录,他将每一行在文件中的起始偏移量作为key,每一行的
内容作为value。
◆默认以\n或回车键作为一行记录。
◆TextInputFormat继承了FileInputFormat。
//job.setInputFormatClass(TextInputFormat.class);
1.2 写自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
//指定自定义的Mapper类 (这个就是我们手动继承Mapper类)
job.setMapperClass(MyMapper.class);
//指定map输出的<k,v>类型。如果<k3,v3>的类型与<k2,v2>的类型一致,那么可以省略
//job.setMapOutputKeyClass(Text.class);
//job.setMapOutputValueClass(LongWritable.class);
1.3 对输出的key、value进行分区。
//分区
Partitioner编程 1.Partitioner是partitioner的基类,如果需要定制partitioner也需要继承该类。
2. HashPartitioner是mapreduce的默认partitioner。计算方法是
which reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks,得到当前的目的reducer。
3. (例子以jar形式运行)
//job.setPartitionerClass(HashPartitioner.class);
//job.setNumReduceTasks(1);
1.4 对不同分区的数据,按照key进行排序、分组。相同key的value放到一个集合中。 //TODO 排序、分组
排序和分组
1.在map和reduce阶段进行排序时,比较的是k2。v2是不参与排序比较的。如果要想让v2也进行排序,需要把k2和v2组装成新的类,作为k2,才能参与比较。
2.分组时也是按照k2进行比较的。
1.5 (可选)分组后的数据进行归约。
// TODO (可选)归约
Combiner编程(如果求平均数就有问题勒,归约总体数量就会减少) 每一个map可能会产生大量的输出,combiner的作用就是在map端对输出先做一次合并,以减少传输到reducer的数据量。
combiner最基本是实现本地key的归并,combiner具有类似本地的reduce功能。
如果不用combiner,那么,所有的结果都是reduce完成,效率会相对低下。使用combiner,先完成的map会在本地聚合,提升速度。
注意:Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。
job.setCombinerClass(MyReducer.class);
2.reduce任务处理
2.1 对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点。
2.2 对多个map任务的输出进行合并、排序。写reduce函数自己的逻辑,对输入的key、value处理,转换成新的key、value输出。
//指定自定义的Reducer类 (这个就是我们手动继承Reducer类)
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
2.3 把reduce的输出保存到文件中。
//指定输出的路径
FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));
//指定输出的格式化类
//job.setOutputFormatClass(TextOutputFormat.class);
//把作业提交给JobTracker运行
job.waitForCompletion(true); 可以看出我们具体要操作的很少,也就是两个类
MyMapper类就是截取我们需要的文本第一行有用的字段
MyReducer类就是最后汇总我们统计的结果
这就是默认的处理方案
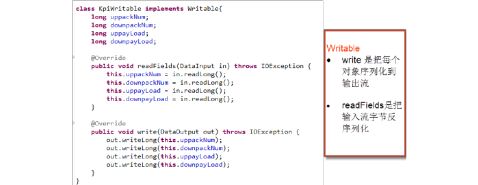
4.序列化概念(自定义writeable类)
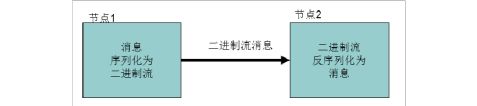
? 序列化(Serialization)是指把结构化对象转化为字节流。
? 反序列化(Deserialization)是序列化的逆过程。即把字节流转回结构化对象。 ? Java序列化(java.io.Serializable)
Hadoop序列化的特点
? 序列化格式特点:
1. 紧凑:高效使用存储空间。
2. 快速:读写数据的额外开销小
3. 可扩展:可透明地读取老格式的数据
4. 互操作:支持多语言的交互
Hadoop的序列化格式:Writable(需要实现writable接口)
Hadoop序列化的作用
? 序列化在分布式环境的两大作用:进程间通信,永久存储。
? Hadoop节点间通信。
String Test Text一般认为它等价于java.lang.String的Writable。针对UTF-8序列。 例:
Text test = new Text("test");
实现Writeable接口进行序列化操作
1.需要自定义类就实现writeable接口就行
2.需要自定义带有比较器的类如下:
① 实现WritableComparable.
② Java值对象的比较:一般需要重写toString(),hashCode(), equals()方法
例子:实现writeable接口
Shuffle对MapReduce性能调优:
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方

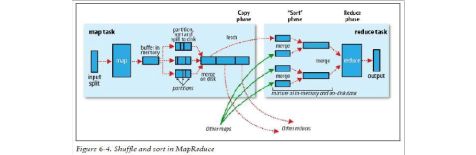
1.
每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb
属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容写到(spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
2. 写磁盘前,要partition,sort。如果有combiner,combine排序后数据。
3. 等最后记录写完,合并全部溢出写文件为一个分区且排序的文件。
1. Reducer通过Http方式得到输出文件的分区。
2. TaskTracker为分区文件运行Reduce任务。复制阶段把Map输出复制到Reducer的内
存或磁盘。一个Map任务完成,Reduce就开始复制输出。
3. 排序阶段合并map输出。然后走Reduce阶段。
不过对于mapreduce如果默认分区得到的结果,也就是全部称为shuffle过程
//1.3 分区 job.setPartitionerClass(KpiPartitioner.class); //设置多个reduce任务进行并行处理,加快处理速度 job.setNumReduceTasks(2); //1.4 TODO排序、分组
job.setGroupingComparatorClass(CombineGroupingComparator.class); //1.5 TODO规约
job.setCombinerClass(MyReducer.class); shuffle就是combine,partition,combine的组合
第一个是map端的combine,是在map本地把同key的放在一起成列表
第二个是partition分割,把键值对按照key对应分配到reduce
第三个是reduce端的combine,把同key的再合并得到最后的reduce输入
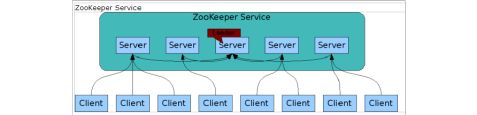
Zookeeper Zookeeper是高有效和可靠的协同工作系统
最好部署3,5,7个节点。部署的越多,可靠性就越高,当然最好是部署奇数个,偶数个是不可以的,但是zookeeper集群是以宕机个数过半才会让整个集群宕机的,所以奇数个集群更佳
Zookeeper能够用来:
1、leader选举(zk集群中,从follower中随机选取一个作为leader)
2、配置信息维护(提供主节点更新,替他从节点共享)
3、确保事务的一致性(在一个分布式的环境中,确保文件写入的一致性等)
在大数据时代分布式处理的已经成为潮流,而Hadoop是一种应用十分广泛的分布式处理框架。但在Hadoop的使用中,Namenode的单点失败问题一直困扰着框架的使用者。本文提出了一种利用Zookeeper对Namenode进行冗余备份协同工作的处理方法,避免了Namenode单点失败造成的服务不可用与文件丢失问题。
冗余备份 就是多准备一份或几份,以备不时之需。例如冗余备份服务器,就是2
台服务器互为备份,一台故障了,另一台立刻接替。
-
hadoop认识总结
一对hadoop的基本认识Hadoop是一个分布式系统基础技术框架由Apache基金会所开发利用hadoop软件开发用户可以在不了…
-
Hadoop学习总结
Hadoop学习总结一背景随着信息时代脚步的加快各类数据信息越来越多海量数据的来源列举如下纽约证券交易所每天产生1TB的交易数据F…
-
hadoop总结
Hadoop概念Hadoop是一个能够对大量数据进行分布式处理的软件框架Hadoop的特点1可靠性Reliablehadoop能自…
-
hadoop原理_自己的总结
用户提交给hadoopclient的command指定了输入路径输出路径如下所示cmdquotHADOOPHOMEbinhadoo…
-
最新hadoop应用总结
Hadoop应用总结一系统配置1安装linuxubuntu系统2安装开启opensshserversudoaptgetinstal…
-
Hadoop常见错误总结
Hadoop常见错误总结20xx-12-3013:55错误1:bin/hadoopdfs不能正常启动,持续提示:INFOipc.C…
-
hadoop常见启动问题总结
Hadoop节点问题总结1.hadoop主节点意外关机重启后hadoop不能启动.Hadoopnamenode由于某些原因关机重启…
-
Hadoop的调度器总结
Hadoop的调度器总结随着MapReduce的流行,其开源实现Hadoop也变得越来越受推崇。在Hadoop系统中,有一个组件非…
-
hadoop认识总结
一对hadoop的基本认识Hadoop是一个分布式系统基础技术框架由Apache基金会所开发利用hadoop软件开发用户可以在不了…
-
Hadoop学习总结
Hadoop学习总结一背景随着信息时代脚步的加快各类数据信息越来越多海量数据的来源列举如下纽约证券交易所每天产生1TB的交易数据F…