最新hadoop应用总结
Hadoop 应用总结
一、 系统配置
1. 安装linux ubuntu系统
2. 安装开启openssh-server:$ sudo apt-get install openssh-server
3. 建立ssh 无密码登录
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
直接回车,完成后会在~/.ssh/生成两个文件:id_dsa 和id_dsa.pub。
这两个是成对出现,类似钥匙和锁。再把id_dsa.pub 追加到授权key 里面(当前并没有authorized_keys文件):
$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys。
完成后可以实现无密码登录本机:$ ssh localhost。
4. 关闭防火墙 $ sudo ufw disable
5. 安装jdk 1.6
6. 安装后,添加如下语句到/etc/profile 中:
export JAVA_HOME=/home/Java/jdk1.6
export JRE_HOME=/home/Java/jdk1.6/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
二、 Hadoop伪分布配置
1. 在conf/hadoop-env.sh文件中增加:export JAVA_HOME=/home/Java/jdk1.6
2. 在conf/core-site.xml文件中增加如下内容:
<!-- fs.default.name - 这是一个描述集群中NameNode结点的URI(包括协议、主机名称、端口号),集群里面的每一台机器都需要知道NameNode的地址。DataNode结点会先在NameNode上注册,这样它们的数据才可以被使用。独立的客户端程序通过这个URI跟DataNode交互,以取得文件的块列表。--> <property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value> </property>
<!— hadoop.tmp.dir是hadoop文件系统依赖的基础配置,很多路径都依赖它。
如果hdfs-site.xml中不配置namenode和datanode的存放位置,默认就放在这个路径中-->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdfs/tmp</value>
</property>
3. 在conf/hdfs-site.xml中增加如下内容: <!-- dfs.replication -它决定着 系统里面的文件块的数据备份个数。对于一个实际的应用,它 应该被设为3(这个数字并没有上限,但更多的备份可能并没有作用,而且会占用更多的空间)。少于三个的备份,可能会影响到数据的可靠性(系统故障时,也许会造成数据丢失)-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!—解决:org.apache.hadoop.security.AccessControlException:Permission
denied:user=Administrator,access=WRITE,inode="tmp":root:supergroup:rwxr-xr-x 。 因为Eclipse使用hadoop插件提交作业时,会默认以 DrWho 身份去将作业写入hdfs文件系统中,对应的也就是 HDFS 上的/user/hadoop , 由于 DrWho 用户对hadoop目录并没有写入权限,所以导致异常的发生。解决方法为:放开 hadoop 目录的权限 , 命令如下 :$ hadoop fs -chmod 777 /user/hadoop --> <property>
<name>dfs.permissions</name>
<value>false</value>
<description>
If "true", enable permission checking in HDFS. If "false", permission checking is turned off, but all other behavior is unchanged. Swit
ching from one parameter value to the other does not change the mode, owner or group of files or directories.
</description>
</property>
<!-- dfs.data.dir - 这是DataNode结点被指定要存储数据的本地文件系统
路径。DataNode结点上的这个路径没有必要完全相同,因为每台机器的环境很可能是不一样的。但如果每台机器上的这个路径都是统一配置的话,会使工作变得简单一些。默认的情况下,它的值是/temp, 这个路径只能用于测试的目的,因为,它很可能会丢失掉一些数据。所以,这个值最好还是被覆盖。 dfs.name.dir - 这是NameNode结点存储hadoop文件系统信息的本地系统路径。这个值只对NameNode有效,DataNode并不需要使用到它。上面对于/temp类型的警告,同样也适用于这里。在实际应用中,它最好被覆盖掉。--> <property>
<name>dfs.name.dir</name>
<value>/home/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdfs/data</value>
</property>
4. 在conf/mapred-site.xml中增加如下内容:
<!-- mapred.job.tracker -JobTracker的主机(或者IP)和端口。--> <property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
三、 操作命令
1. 格式化工作空间
进入bin目录,运行 ./hadoop namenode –format
2. 启动hdfs
进入hadoop目录,在bin/下面有很多启动脚本,可以根据自己的需要来启动。 * start-all.sh 启动所有的Hadoop守护。包括namenode, datanode, jobtracker, tasktrack
* stop-all.sh 停止所有的Hadoop
* start-mapred.sh 启动Map/Reduce守护。包括Jobtracker和Tasktrack * stop-mapred.sh 停止Map/Reduce守护
* start-dfs.sh 启动Hadoop DFS守护Namenode和Datanode
* stop-dfs.sh 停止DFS守护
四、 Hadoop hdfs 整合
可按如下步骤删除和更改hdfs不需要的文件:
1.
2.
3.
4. 将hadoop-core-1.0.0.jar 移动到lib目录下。 将ibexec目录下的文件移动到bin目录下。 删除除bin、lib、conf、logs之外的所有目录和文件。 如果需要修改日志存储路径,则需要在conf/hadoop-env.sh文件中增加:export HADOOP_LOG_DIR=/home/xxxx/xxxx即可。
五、 HDFS文件操作
Hadoop使用的是HDFS,能够实现的功能和我们使用的磁盘系统类似。并且支持通配符,如*。
1. 查看文件列表
查看hdfs中/user/admin/hdfs目录下的文件。
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -ls /user/admin/hdfs
查看hdfs中/user/admin/hdfs目录下的所有文件(包括子目录下的文件)。 a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -lsr /user/admin/hdfs
2. 创建文件目录
查看hdfs中/user/admin/hdfs目录下再新建一个叫做newDir的新目录。 a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -mkdir /user/admin/hdfs/newDir
3. 删除文件
删除hdfs中/user/admin/hdfs目录下一个名叫needDelete的文件
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -rm /user/admin/hdfs/needDelete
删除hdfs中/user/admin/hdfs目录以及该目录下的所有文件
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs -rmr /user/admin/hdfs
4. 上传文件
上传一个本机/home/admin/newFile的文件到hdfs中/user/admin/hdfs目录下 a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs –put /home/admin/newFile /user/admin/hdfs/
5. 下载文件
下载hdfs中/user/admin/hdfs目录下的newFile文件到本机/home/admin/newFile中
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs –get /user/admin/hdfs/newFile /home/admin/newF
ile
6. 查看文件内容
查看hdfs中/user/admin/hdfs目录下的newFile文件
a. 进入HADOOP_HOME目录。
b. 执行sh bin/hadoop fs –cat /home/admin/newFile
一、 Namenode 和 Datanode 解释
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。Namenode是一个中心服务器,负责管理文件系统的名字空间
(namespace)以及客户端对文件的访问。集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
Namenode和Datanode被设计成可以在普通的商用机器上运行。这些机器一般运行着GNU/Linux操作系统(OS)。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署Namenode或Datanode。由于采用了可移植性极强的Java语言,使得HDFS可以部署到多种类型的机器上。一个典型的部署场景是一台机器上只运行一个
Namenode实例,而集群中的其它机器分别运行一个Datanode实例。这种架构并不排斥在一台机器上运行多个Datanode,只不过这样的情况比较少见。
集群中单一Namenode的结构大大简化了系统的架构。Namenode是所有HDFS元数据的仲裁者和管理者,这样,用户数据永远不会流过Namenode。
第二篇:每周学习总结10 hadoop管理命令
1.Hadoop管理命令实践报告:
Dfsamin是一个用来获取HDFS文件系统实时状态信息的多任务工作,具有对于HDFS文件系统管理操作的功能。在拥有超级用户权限的前提下,管理员可以在终端中通过Hadoop dfsadmin对于其进行功能方法的调用。主要命令如下:
-report 主要用来获取文件系统的基本信息和统计信息
-safemode enter!leave!get!wait 安全模式的维护命令。安全模式是NameNode的一种状态。在安全模式状态下:
1) 不接受对于空间名字的更改
2) 无法对数据块进行删除以及复制操作
NameNode会在Hadoop系统启动之后自动开启安全模式,一旦当配置块满足最小百分比的副本数条件时,Hadoop系统会自动关闭安全模式。同时根据用户的需要也可以手动关闭安全模式或者选择手动开启安全模式。
-refreshNode 重新读取hosts和exclude,以实现在添加新的节点后可以使系统直接进行识别。
-finalizeUpgrade 用于终结HDFS文件系统的升级操作。DataNode会删除上一个版本的工作目录。在DataNode完成操作之后,NameNode也会执行这个操作。
-upgradeProgress status!details!force 分别实现获取当前系统升级的状态,升级状态过程中的细节,强制进行系统的升级。
-metasave filename 将hadoop系统中的管理节点的数据结构中的主要部分保存到hadoop.log.dir文件中提前预设好的属性中指定的的对应文件名的目录上。
在此文件中的主要内容如下:
1) 管理节点接收到的数据节点的正常工作的心跳
2) 被复制的数据块的等待状态
3) 被复制的数据块的执行状态
4) 确定要被删除的数据块的等待状态
-setQuota <quota> <dirname>…<dirname> 主要用作为每个指定路径下的文件目录设
定指定的配额。目的是为了强制设定文件目录的名字的字节数。如果出现以下情况将会对Hadoop系统报出错误信息:
1) 文件目录的名字不是一个正整数
2) 当前的操作用户不具有管理员权限
3) 文件目录不存在或者此路径指向的是一个文件而非目录
4) 当设定好的目录生效时会超出新设定的配额
-clrQuota <dirname>….<dirname> 为每个已经分配好的指定路径上的文件目录清除已经设定好的配额。当出现以下情况将会对Hadoop系统报出错误信息:
1) 此目录指定的目录不存在或者该目录为一个文件
2) 当前的操作用户不具有管理员权限
另外一种情况为如果此文件目录如果先前没有设定配额,则使用此操作不会向系统报错
-help [cmd] 显示对于在参数中给定的命令相关的帮主信息,如果在参数中没有给出指定的命令,将会显示出所有命令的帮主信息。
1.1 文件系统验证
在Hadoop系统中提供了一个用于验证HDFS文件系统中的文件是否可以完整读取的的验证命令fsck。主要用于检测文件是否在数据节点的文件中丢失,以及检测对于副本本身的要求过高还是过低。
1.1.1 Fsck的工作机理
Fsck是一款基于Hadoop的SHELL编程命令,通过参数来指定检查的文件以。
Fsck会递归检查整个HDFS文件系统的命名空间,首先从文件系统的root目录开始检测然后检测可以找到的所有文件,并且在验证完毕后对于这个查找到的文件进行一个标记。FSCK对于一个文件的检测主要从可用性和一致性入手。
下面为Fsck的输出属性图:
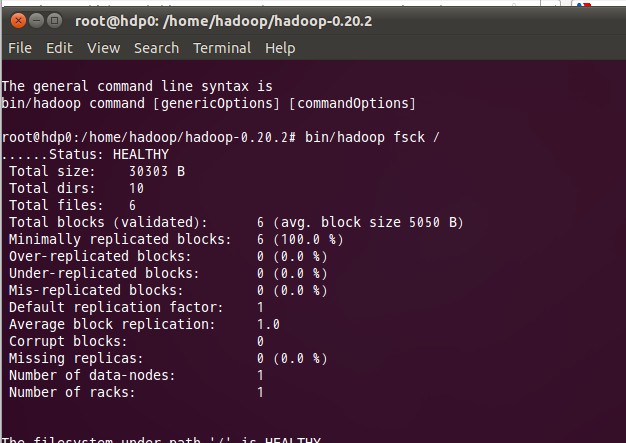
1.1.2 Fsck输出参数说明:
(1)Over-replicated blocks:用来标识所拥有的副本块数已经超出自身所属文件的副本数配额限定的文件。HDFS文件系统在出现这种情况后系统会根据自身副本删除机制对多余的副本进行删除。
(2)Under-replicated blocks: 用来标识所拥有的副本块数未达到自身所属文件的副本数要求的文件。HDFS文件系统在出现这种情况后系统会根据自身副本创建机制自动创建副本直到到达文件要求的副本数。可以通过执行dfsadmin –metasave SHELL命令来获取当前正在被复制的块的信息。
(3)Misrepilcated blocks:用来标识云存储系统中不符合存储位置策略的块。比如说副本因子为3,则代表至少拥有2个副本不在同一个机架上。而如果出现了一个数据块的3个副本都在同一个机架上则此块将被标识。HDFS系统不会自动处理这种标识,需要我们手动设这副本因子的个数。
(4)Corrupt blocks:用来标识所有副本不可用的数据块,只要数据块的副本可用,它就不会被标识。Namenode将会使用没有被Corrupt blocks标识的数据块来进行复制。以达到目标值。
(5)Missing replicas:用来标识机群中没有副本存在的数据块。Corrupt blocks 和Missing replicas是普遍受到最多关注的输出参数。出现以上标识则表明出现了数据不一致性和可用性的问题。
HDFS系统在遇见以上2种问题后可以通过使用如下SHELL脚本命令进行处理。
-move 将被标识的文件放入HDFS文件系统的/lost+found文件夹中。
-delete 将被标识的文件直接进行删除。
-
hadoop认识总结
一对hadoop的基本认识Hadoop是一个分布式系统基础技术框架由Apache基金会所开发利用hadoop软件开发用户可以在不了…
-
Hadoop学习总结
Hadoop学习总结一背景随着信息时代脚步的加快各类数据信息越来越多海量数据的来源列举如下纽约证券交易所每天产生1TB的交易数据F…
-
hadoop总结
Hadoop概念Hadoop是一个能够对大量数据进行分布式处理的软件框架Hadoop的特点1可靠性Reliablehadoop能自…
-
hadoop原理_自己的总结
用户提交给hadoopclient的command指定了输入路径输出路径如下所示cmdquotHADOOPHOMEbinhadoo…
-
最新hadoop应用总结
Hadoop应用总结一系统配置1安装linuxubuntu系统2安装开启opensshserversudoaptgetinstal…
-
Hadoop常见错误总结
Hadoop常见错误总结20xx-12-3013:55错误1:bin/hadoopdfs不能正常启动,持续提示:INFOipc.C…
-
hadoop常见启动问题总结
Hadoop节点问题总结1.hadoop主节点意外关机重启后hadoop不能启动.Hadoopnamenode由于某些原因关机重启…
-
Hadoop的调度器总结
Hadoop的调度器总结随着MapReduce的流行,其开源实现Hadoop也变得越来越受推崇。在Hadoop系统中,有一个组件非…
-
hadoop认识总结
一对hadoop的基本认识Hadoop是一个分布式系统基础技术框架由Apache基金会所开发利用hadoop软件开发用户可以在不了…
-
Hadoop学习总结
Hadoop学习总结一背景随着信息时代脚步的加快各类数据信息越来越多海量数据的来源列举如下纽约证券交易所每天产生1TB的交易数据F…