memo
Practice 1 Translate the following memos.
Memo 1

Memo 2
MEMO
To: Purchasing & Sales Supervisor
From: Manager
Re: Slembrrouck BVBA
Date: 15 January
I am very surprised that Slembrouck BVBA is not going to deliver the coffeee and the rest of the tea until the end of the month. We have now found a new supplier, so please cancel our order with them.
Practice 2 Write a memo according to the information given.
说明:假定你是销售部经理John Green, 请以John Green的名义按照下面的格式和内容给本公司其他各部门经理写一个内部通知。
主题:讨论20xx年度第三季度 (the 3rd quarter)销售计划
通告时间:20xx年6月16日
内容:本部门已制定20xx年第三季度的销售计划。将于20xx年6月19日下午1:00 在本公司会议室开会,讨论这一计划。并希望各部门经理前来参加。如不能到会,请提前告知本部门秘书。
Practice 3 Please translating the following sentences on how to write a good memo.
1.Be kind to your reader--use headings and bullets as necessary to make the memo easy to read and key points stand out.
2. Be concise--long sentences with complex construction do not belong in memos. Keep memos short and to-the-point.
3.Come to the point first--always use a bottom-line statement at the very beginning of a non-sensitive memo.
4.Remember memo format--never use a salutation or complementary closing with a memo.
5.Be coherent--limit each paragraph to only one idea. Keep your sentences flowing smoothly, and keep them short.
6.Use a business-like tone--use the first person (I or we); use short, simple words; be as informal as the situation allows; use concrete, specific words.
7.Proofread your work--always read your work (or have someone else read it) before you sent it out.
8.Identify your audience--identify the person or persons to whom you are writing. Think about what they know, who they are, what they want to see or hear, how they are situated. Clarify your audience's background, context, and environment. Never, never, never write without identifying your audience first.
第二篇:memo-446
CSAIL Computer Science and Artificial Intelligence LaboratoryMassachusetts Institute of TechnologyDynamic Cache Partitioning for Simultaneous Multithreading Systems Ed Suh, Larry Rudolph, Srini DevadasIn the proceedings of the IASTED International Conference on Parallel and Distributed Computing and Systems
2001, August Computation Structures Group Memo 446
The Stata Center, 32 Vassar Street, Cambridge, Massachusetts 02139
DynamicCachePartitioningforSimultaneousMultithreading
Systems
G.EdwardSuh,LarryRudolphandSrinivasDevadas
LaboratoryforComputerScience
MIT
Cambridge,MA02139
suh,rudolph,devadas@mit.eduemail:
ABSTRACT
Thispaperproposesadynamiccachepartitioningmethodforsimultaneousmultithreadingsystems.Wepresentageneralpartitioningschemethatcanbeappliedtoset-associativecachesatanypartitiongranularity.Further-more,inourschemethreadscanhaveoverlappingparti-tions,whichprovidesmoredegreesoffreedomwhenpar-titioningcacheswithlowassociativity.
Sincememoryreferencecharacteristicsofthreadscanchangeveryquickly,ourmethodcollectsthemiss-ratecharacteristicsofsimultaneouslyexecutingthreadsatrun-time,andpartitionsthecacheamongtheexecutingthreads.Partitionsizesarevarieddynamicallytoimprovehitrates.Trace-drivensimulationresultsshowarelativeimprove-mentintheL2hit-rateofupto40.5%overthosegener-atedbythestandardleastrecentlyusedreplacementpolicy,andIPCimprovementsofupto17%.OurresultsshowthatsmartcachemanagementandschedulingisimportantforSMTsystemstoachievehighperformance.
KEYWORDS
MemorySystem,SimultaneousMultithreading,CachePar-titioning
1.Introduction
MicroprocessorswithmultiplefunctionalunitshavelowIPC(InstructionsperCycle)rateseitherbecauseofalackofparallelism,orbecauseofahighincidenceofdatadependencies.SimultaneousMulti-Threading,[1,2,3](SMT),helpsintheformercasebut,inthelattercase,itonlyexacerbatesthestressonthememorysubsystem,es-peciallysincethestandardLRUreplacementschemetreatsallreferencesinthesameway.Thus,asinglethreadcaneasily“pollute”thecachewithitsdata,causinghighermissratesforotherthreads,andresultinginlowoverallperfor-mance.
Thispaperpresentsadynamiccachepartitioningal-gorithmthatminimizestheoverallcachemissrateforsi-multaneousmultithreadingsystems.Ratherthanrelyingonthestandardleastrecentlyused(LRU)cachereplace-mentpolicy,ouralgorithmdynamicallyallocatespartsofthecachetothemostneedythreadsusingon-lineestimates
ofindividualthreadmissrates.Thecacheisassumedtobelargeenoughtosupportmultiplecontexts,butnotlargeenoughtoholdalloftheworkingsetsofthesimultaneouslyexecutingthreads.Althougha1997studyhasshownthata256-KBL2cache,whichisreasonablesizeformodernmicroprocessors[4,5,6],islargeenoughforaparticularsetofworkloads[2],webelievethatworkloadshavebe-comemuchlargeranddiverse;multimediaprogramssuchasvideooraudioprocessingsoftwareoftenconsumehun-dredsofMBandmanySPECCPU2000benchmarksnowhavememoryfootprintslargerthan100MB[7].
Weproposeanovelcachepartitioningschemewhereinacachemisswillonlyallocateanewcacheblocktoathreadifitscurrentallocationisbelowitslimit.Toim-plementthisscheme,werequirecountersinthecachethatprovideon-lineestimatesofindividualthreadmissrates.Basedonthesecounters,wecanaugmentLRUreplace-menttobetterallocatecacheresourcestothreads,orwecanuseColumncaching[8],whichallowsthreadstobeassignedtooverlappingpartitions,topartitionthecache.Simulationshowsthatthepartitioningalgorithmcansig-ni?cantlyimproveboththemiss-rateandtheinstructionspercycle(IPC)oftheoverallworkload.
Inconventionaltime-sharedsystems,cachepartition-ingdependsnotonlyontheactivethread,butalsoonthememoryreferencepatternofinactivethreadswhichhaveruninthepast,andwillrunagaininthenearfuture.Ontheotherhand,inSMTsystems,multiplethreadsareac-tiveatthesametime,collectivelystressingthememorysystem.Sincethesethreadsveryquicklyuseupcachere-sourcesoncetheystartrunning,partitioningdependsonlyonthememoryreferencecharacteristicsofthesetofactivethreads.Thisdiffersfromtraditionaltimesharingsystemswhereonemustalsoconsiderthelengthofthetimequan-tumandthecharacteristicsoftheready,butnotexecutingthreads.Sincethememoryreferencesfromeachthreadareinterleavedverytightly,onecanconsideranSMTsystemtobeatraditionaltime-sharingsystemwithacontextswitchateachmemoryreference.1
Thispaperisorganizedasfollows.InSection2,we
1In
manysystems,eachpagefaultordiskaccesscausesacontext
switchandsodiskcachepartitioningschemesaresomewhatrelevanttoSMTcachepartitioning.
describerelatedwork.InSection3,we?rststudytheop-timalcachepartitioningproblemfortheidealcaseoffullyassociativecachesthatarepartitionableonacache-blockbasis.Wethenextendourmethodtothemorerealisticset-associativecachecase.Section4evaluatesthepartitioningmethodbysimulations.Finally,Section5concludesthepaper.
2.RelatedWork
Stone,TurekandWolf[9]investigatedtheoptimalallo-cationofcachememorybetweentwocompetingprocessesthatminimizestheoverallmiss-rateofacache.Theirstudyfocusesonthepartitioningofinstructionanddatastreams,whichcanbethoughtofasmultitaskingwithaveryshorttimequantum,andshowsthattheoptimalallocationoccursatapointwherethemiss-ratederivativesofthecompetingprocessesareequal.TheLRUreplacementpolicyappearstoproducecacheallocationsveryclosetooptimalfortheirexamples.
Inpreviouswork[10]weproposedananalyticalcachemodelformultitasking,andalsostudiedthecachepartitioningproblemfortime-sharedsystemsbasedonthemodel.Thatworkisapplicabletoanylengthoftimequan-tumratherthanjustshorttimequantum,andshowsthatthecacheperformancecanbeimprovedbypartitioningacacheintodedicatedareasforeachprocessandasharedarea.However,thepartitioningwasperformedbycollect-ingthemiss-rateinformationofeachprocessoff-line.Theworkof[10]didnotinvestigatehowtopartitionthecachememoryatrun-time.
Thi′ebaut,StoneandWolfappliedtheirtheoreticalpartitioningstudy[9]toimprovediskcachehit-ratios[11].Themodelfortightlyinterleavedstreamsisextendedtobeapplicableformorethantwoprocesses.Theyalsodescribetheproblemsinapplyingthemodelinpractice,suchasap-proximatingthemiss-ratederivative,non-monotonicmiss-ratederivatives,andupdatingthepartition.Trace-drivensimulationsfor32-MBdiskcachesshowthatthepartition-ingimprovestherelativehit-ratiosintherangeof1%to2%overtheLRUpolicy.
Ourpartitionworkdiffersfrompreviousefforts.Itworksforset-associativecacheswithmultiplethreadsandacoarse-grainedpartition,whereasThi′ebautetal.[11]onlyfocusedondiskcachesthatarefully-associativewithcacheblockgranularity.Finally,thisworkdiscussesanon-linemethodtopartitionthecache,whereasourpreviousonlycoveredpartitioningbasedonoff-linepro?ling[10].
3.PartitioningAlgorithm
Thissectionpresentsourcachepartitioningalgorithm.We
leaduptoageneralpartitioningmethodinseveralsteps.First,givenafully-associativecachethatcanbepartitionedonacache-blockbasisandknowingthemiss-rateforeachtaskasafunctionofpartitionsize,weshowhowanoptimal
partitionisobtainedbyiterativelyincreasingthepartitionsizeforthethreadthatwillbene?tthemost.Next,weshowthatitispossibletocomputethemissratefunctionson-lineusingmanyhardwarecountersforafullyassociativecache,andthatitispossibletoapproximatethemiss-ratefunctionusingfewercountersinthecaseofaset-associativecache.Theseresultsarethencombinedandappliedtothemorepracticalcaseofcoarsegrainedpartitioning.Finally,thealgorithmtoactuallyallocatecacheblockstoeachthreadisdeveloped.
3.1OptimalCachePartitioning
Givenexecutingthreadssharingacacheofblockswithpartitioningonacacheblockgranularity,theprob-lemistopartitionthecacheintodisjointsubsetsofcacheblockssoastominimizetheoverallmiss-rate.Foreachthread,themiss-rateasafunctionofpartitionsize
(thenumberofcacheblocks),isknown.Let
representthenumberofcacheblocksallocatedtothethread.Acachepartitionisspeci?edbythenumberofcacheblocks
allocatedtoeachthread,i.e.,
.Sinceitisunreasonabletorepartitionthecacheeverymemoryrefer-ence,thepartitionremains?xedoveratimeperiod,,thatislongenoughtoamortizetherepartitioningcost.
Thenumberofcachemissesforthe
threadoverisgivenbyafunctionofpartitionsize().Theop-timalpartitionfortheperiodisthesetofintegervalues
,thatminimizesthefollowingexpression:
totalmissesovertimeperiod
(1)
undertheconstraintthat.isthetotalnum-berofblocksinthecache.
Forthecasewherethenumberofmissesforeachthreadisastrictconvexfunctionofcachespace,Stone,TurekandWolf[9]notedthat?ndingtheoptimalpartition,
,fallsintothecategoryofseparableconvex
resourceallocationproblems.Thefollowing,well-known,simplegreedyalgorithmyieldsanoptimalpartition[9,12]:
1.Letthemarginalgain,,bethenumberofaddi-tionalhitsforthethread,whentheallocatedcache
blocksincreasesfromto
.2.Initialize
.
3.Increasebyonethenumberofcacheblocksassignedtothethreadthathasthemaximummarginalgaingiventhecurrentallocation.Increasebyone,whereistheindexforwhich
islargest.
4.Repeatstep3untilallcacheblocksareassigned(i.e
times).
3.2ComputingtheMarginalGain
Thecomputationofthemarginalgain,,dependsonthethemissratefortaskasafunctionofthecachepar-titionsize,,overatimeperiod,.Forafullyon-as-sociativeLRUcache,itispossibletocomputelineusingcounters.Whenataskreferencesadataiteminthecachethatisthemostrecentlyreferenceditem,thencounterfortaskisincreased.Attheendofthetimeperiod,thesecountersformthemissratefunctionforeachtask,asdescribedbelow.Thedescriptionbelowappliestothegeneralcaseofaset-associativecache.
Toperformdynamiccachepartitioning,themarginalgainsofhavingonemorecacheblockcanbeestimated
on-line.Asdiscussedintheprevioussection,
isthenumberofadditionalhitsthatthethreadcanobtainbyhavingcacheblockscomparedtothecasewhenithasblocks.AssumingtheLRUreplacementpolicyisused,representsthenumberofhitsonthemostre-centlyusedcacheblockofthe
thread,representsthenumberofhitsonthesecondmostrecentlyusedcacheblockofthethread,andsoon.
Foreachthread,asetofcounters,oneforeachasso-ciativity(way)ofthecache,ismaintained.Oneverycachehit,thecorrespondingcounterisincreased.Thatis,ifthehitisonthemostrecentlyusedcacheblockofthethread,the?rstcounterisincreasedbyone,andsoon.Thecountervaluerepresentsthenumberofadditionalhitsforthethreadbyhavingtheway.Ifweignorethedegrada-tionduetolowassociativity,thecountervaluecanalsobethoughtofasthenumberofadditionalhitsforacache
with
blockscomparedtoacachewithblocks,whereisthenumberofcachesets.Therefore,
satis?esthefollowingequation.
(2)
whererepresentsthecountervalueofthethread.
ToestimatemarginalgainsfromEquation2,assumethatisa.straightThisapproximationlineforisbetweenverysimpletocal-and
culateandyetshowsreasonableperformanceinpartition-ing.ThisisespeciallytrueinthecaseoflargeL2(level2)caches,whichonlyseememoryreferencesthatare?lteredbyL1(level1)caches,andoftenshowthemiss-ratethatisproportionaltocachesize.Tobemoreaccurate,
canbeassumedtobeaformofanpowerfunction,e.g.,
.Empiricalstudiesshowedthatthepowerfunctionoftenaccuratelyestimatesthemiss-rate[13].
Sincecharacteristicsofthreadschangedynamically,
theestimationof
shouldre?ectthechanges.Thisisachievedbygivingmoreweighttothecountervaluemea-suredinmorerecenttimeperiods.Aftereverymemoryreferences,wemultiplyeachcounterby,whichisbe-tweenand.Asaresult,theeffectofhitsinprevious
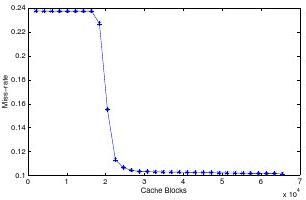
Figure1.Themiss-rateofartasafunctionofcacheblocks.
timeperiodsexponentiallydecays.
ThenumberofmissesforarealapplicationisoftennotstrictlyconvexasillustratedinFigure1.The?gureshowsthemiss-ratecurveofartfromtheSPECCPU2000benchmarksuite[7]fora32-way1-MBcache.Aslongasthemiss-ratecurveisconvex,themarginalgainfunctiondecreases,andatthenon-convexpoints,themarginalgainfunctionwillincrease.Intheory,everypossiblepartitionshouldbecomparedtoobtaintheoptimalpartitionfornon-convexmiss-ratecurves.However,non-convexcurvescanbeapproximatedbyacombinationofafewconvexcurves.Forexample,themiss-rateofartcanbeapproximatedbytwoconvexcurves,onebeforethesteepslopeandoneafterthat.Onceacurveonlyhasafewnon-convexpoints,theconvexresourceallocationalgorithmcanbeusedtoguar-anteetheoptimalsolutionfornon-convexcases.1.Foreachthread,,computethenon-convexpoints
ofitsmiss-ratecurve:
,
.
2.Executetheconvexalgorithmwithinitializedto
or,.
3.Repeatstep2forallpossibleinitializations,andchoosethepartitionthatresultsinthemaximum
.
3.3CoarseGranularityPartitioning
Sinceitisratherexpensivetocontroleachcacheblock,practicalpartitioningmechanismsperformallocationofchunksofcacheblocks,referredtoasapartitionblock.Wewillusetorefertothenumberofcacheblocksinapar-titionblock.Weallowtheallocationofonepartitionblocktomultiplethreadsandletthereplacementpolicydecidethecacheblocklevelpartition.
First,considerthenosharingcasewhereeachparti-tionblockisallocatedtoonlyonethread.Thealgorithmforcacheblockgranularitypartitioningcanbedirectlyapplied.De?nethepartitionmarginalgainas
andusethegreedyalgo-rithmtoassignonepartitionblockatatime,resultinginanoptimalpartitionwithoutsharing.However,sharingapar-titionblockisessentialtoachievehighperformancewithcoarsegranularitypartitioning.Forexample,whentherearemanymorethreadsthanpartitionblocks.Itisobviousthatthreadsmustsharepartitionblocksinordertousethecache.
Knowingthenumberofmissesforeachthreadasafunctionofcachespace,theeffectofsharingpartitionblockscanbeevaluatedoncetheallocationofthesharedblocksbytheLRUreplacementpolicyisknown.Con-siderthecasewhen
threadssharepartitionblocks.Sinceeachpartitionblockconsistsofcacheblocks,thecasecanbethoughtofasthreadsshar-ing
cacheblocks.SinceSMTsystemstightlyinterleavememoryreferencesofthethreads,thereplace-mentpolicycanbethoughtofasrandom.
De?neasthenumberofpartitionblocksthatareallocatedtothethreadexclusively,andas
thenumberofcacheblocksthatbelongstothe
thread.Sincethereplacementcanbeconsideredasrandom,thenumberofreplacementsforacertaincacheregionispro-portionaltothesizeoftheregion.
Thenumberofmissesthatreplacesthecacheblockinthesharedspacecanbeestimatedasfollows.
(3)
Undertherandomreplacement,thenumberofcacheblocksbelongingtoeachprocessforthesharedareaispro-portionaltothenumberofcacheblocksthateachprocessbringsintothesharedarea.Therefore,canbewrittenby
(4)
SinceisonboththeleftandrightsidesofEquation4,an
iterativemethodcanbeusedtoestimate
startingwithainitialvaluethatisbetween.
and
3.4PartitioningMechanisms
Forset-associativecaches,variouspartitioningmecha-nismscanbeusedtoactuallyallocatecachespacetoeachthread.OnewaytopartitionthecacheistomodifytheLRUreplacementpolicywhichhastheadvantageofcontrollingthepartitionatcacheblockgranularity,butLRUimplemen-tationscanbeexpensiveforhigh-associativitycaches.
Ontheotherhand,therearemechanismsthatoperateatcoarsegranularity.Pagecoloring[14]canrestrictvirtualaddresstophysicaladdressmapping,andasaresultre-strictcachesetsthateachthreaduses.ColumnCaching[8]canpartitionthecachespacebyrestrictingcachecolumns
(ways)thateachthreadcanreplace.However,itisrela-tivelyexpensivetochangethepartitioninthesemecha-nisms,andthemechanismssupportalimitednumberof
partitionblocks.Inthissection,wedescribethemodi?edLRUmechanismandcolumncachingtobeusedinourex-periments.
3.4.1Modi?edLRUReplacement
InadditiontoLRUinformation,thereplacementdecisiondependsonthenumberofcacheblocksthatbelongstoeachthread().Onamiss,theLRUcacheblockofthethread()thatcausedthemissischosentobereplacedifitsactu-allyallocation()islargerthanthedesiredone().Otherwise,theLRUcacheblockofanotherover-allocatedthreadischosen.Forset-associativecaches,theremaybenocacheblockofthedesiredthreadintheset,sotheLRUcacheblockofarandomlychosenthreadisreplaced.
3.4.2ColumnCaching
Columncachingisamechanismthatallowspartitioningofacacheatcolumnor“way”granularity.Astandardcacheconsidersallcacheblocksinasetascandidatesforreplace-ment.Asaresult,aprocess’datacanoccupyanycacheblock.Columncaching,ontheotherhand,restrictsthere-placementtoasub-setofcacheblocks,whichessentiallypartitionsthecache.
Columncachingspeci?esreplacementcandidacyus-ingabitvectorinwhichabitindicatesifthecorrespondingcolumnisacandidateforreplacement.ALRUreplace-mentunitismodi?edsothatitreplacestheLRUcacheblockfromthecandidatesspeci?edbyabitvector.Eachpartitionableunithasabitvector.Sincelookupispreciselythesameasforastandardcache,columncachingincursnoperformancepenaltyduringlookup.
4.ExperimentalResults
Thissectionpresentstheresultsofatrace-drivensimula-tionsysteminordertounderstandthequantitativeeffectsofourcacheallocationscheme.Thesimulationsconcentrateonan8-wayset-associativeL2cachewith32-Byteblocksandvarythesizeofthecacheoverarangeof256KBto4MB.Duetolargespaceandlonglatency,ourschemeismorelikelytobeusefulforanL2cache,andsothatisthefocusofoursimulations.Wenoteinpassing,thatwebe-lieveourapproachwillworkonL1cachesaswell.
Threedifferentsetsofbenchmarksaresimulated,seeTable1.The?rstset(Mix-1)hastwothreads,artandmcfbothfromSPECCPU2000.Thesecondset(Mix-2)hasthreethreads,vpr,bzip2andiu.Finally,thethirdset(Mix-3)hasfourthreads,twocopiesofartandtwocopiesofmcf,eachwithadifferentphaseofthebench-mark.
NameThreadDescription
Mix-1artImageRecognition/NeuralNetworkmcfCombinatorialOptimization
Mix-2
vprFPGACircuitPlacementandRoutingbzip2Compression
iuImageUnderstanding
Mix-3
art1ImageRecognition/NeuralNetworkart2mcf1CombinatorialOptimization
mcf2
Table1.Thebenchmarksetssimulated.AllbuttheImageUnderstandingbenchmarkarefromSPECCPU-2000.
4.1Hit-rateComparison
Thesimulationscomparetheoverallhit-rateofastandardLRUreplacementpolicyandtheoverallhit-rateofacachemanagedbyourpartitioningalgorithm.Thepartitionisupdatedeverytwohundredthousandmemoryreferences
(
),andtheweightingfactorissetas.Thesevalueshavebeenarbitarilyselected;morecarefullyselectedvaluesofandarelikelytogivebetterresults.Thehit-ratesareaveragedover?ftymillionmemoryrefer-encesandshownforvariouscachesizes(seeTable2).
ThesimulationresultsshowthatthepartitioningcanimprovetheL2cachehit-ratesigni?cantly:forcachesizesbetween1MBto2MB,partitioningimprovedthehit-rateupto40%relativetothehit-ratefromthestandardLRUreplacementpolicy.Forsmallcaches,suchas256-KBand512-KBcaches,partitioningdoesnotseemtohelp.Weconjecturethatthesizeofthetotalworkloadsistoolargecomparedtothecachesize.Attheotherextreme,partition-ingcannotimprovethecacheperformanceifthecacheislargeenoughtoholdalltheworkloads.Therangeofcachesizesforwhichpartitioningcanimproveperformancede-pendsonboththenumberofsimultaneousthreadsandthecharacteristicsofthethreads.ConsideringthatSMTsystemsusuallysupporteightsimultaneousthreads,cachepartitioningcanimprovetheperformanceofcachesintherangeofuptotensofMB.
Theresultsalsodemonstratethatthebenchmarksetshavelargefootprints.Forallbenchmarksets,thehit-rateimprovesby10%to20%asthecachesizedoubles.Thisimpliesthatthesebenchmarksneedalargecache,andthereforeexecutingbenchmarkssimultaneouslycandegradethememorysystemperformancesigni?cantly.
4.2EffectofPartitioningonIPC
Althoughimprovingthehit-rateofthecachealsoimprovestheperformanceofthesystem,modernsuperscalarproces-sorscanhidememorylatencybyexecutingotherinstruc-tionsthatarenotdependentonmissedmemoryreferences.Therefore,theeffectofcachepartitioningonthesystem
SizeL1L2
Part.L2
Abs.
Rel.
(MB)%Hits
%Hits
%Hits
%Imprv.
%Imprv.
art+mcf0.215.615.3-0.2-1.5
0.517.216.4-0.8
-4.6171.926.236.910.6
40.4250.051.11.12.2476.775.0-1.6-2.2vpr+bzip2+iu0.222.922.1-0.8-3.60.527.528.20.6
2.5195.433.535.82.3
7.0259.666.36.611.2481.381.50.20.2art1+mcf1+art2+mcf2
0.212.012.60.65.30.514.214.30.1
0.7171.516.919.02.1
12.5226.634.98.231.04
50.551.30.7
1.5
Table2.Hit-rateComparisonbetweenthestandardLRUandtheparti-tionedLRU.
performance,andinparticularonIPC(InstructionsPerCy-cle),isevaluatedbasedonentiresystemsimulations.
ThesimulationresultsinthissectionareproducedbySimpleScalartoolset[15].SimpleScalarisacycle-accurateprocessorsimulatorthatsupportsout-of-orderis-sueandexecution.Ourprocessormodelforthesimula-tionscanfetchandcommit4instructionsatatime,andhas4ALUsand1multiplierforintegersand?oatingpointsrespectively.Tobeconsistentwiththetrace-drivensimula-tions,32-KB8-wayL1cacheswithvarioussizesof8-wayL2cachesaresimulated.L2accesslatencyis6cyclesandmainmemorylatencyis16cycles.
Figure2(a)showstheIPCoftwobenchmarks(artandmcf)asafunctionofL2cachesize.EachbenchmarkissimulatedseparatelyandisallocatedallsystemresourcesincludingalloftheL2cache.L1cachesareassumedtobe32-KB8-wayforallcases.ForvariousL2cachesizes,IPCisestimatedasafunctionoftheL2hit-rate(Figure2(b)).
The?guresillustratetwothings.First,theIPCofartisverysensitivetothecachesize.TheIPCalmostdoublesiftheL2cachesizeisincreasedfrom1MBto4MB.Second,theIPCsofthesetwobenchmarksarerela-tivelylowconsideringthereare10functionalunits(5forinteger,5for?oatingpointinstructions).Sincetheutiliza-tionsofthefunctionalunitsaresolow,executingthesetwobenchmarkssimultaneouslywillnotcausemanycon?ictsinfunctionalresources.
WhenexecutingthethreadssimultaneouslytheIPCvaluesareapproximatedfromFigure2(b)andthehit-ratesareestimatedfromthetrace-drivensimulations(ofthepre-vioussubsection).Forexample,thehit-ratesofartand
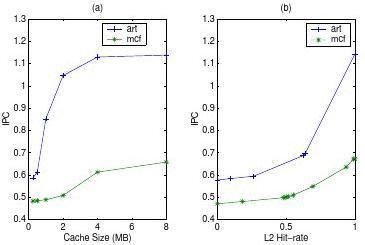
Figure2.IPCofartandmcfunder32-KB8wayL1cachesandvarioussize8-wayL2caches.(a)IPCasafunctionofcachesize.(b)IPCasafunctionofL2hit-rate.
mcfare25.79%and26.63%,respectively,iftwothreadsexecutesimultaneouslywitha32-KB8-wayL1cacheanda1-MB8-wayL2cache,fromtrace-drivensimulation.FromFigure2(b)theIPCofeachthreadforthegivenhit-ratescanbeestimatedas0.594and0.486.Assumingnoresourcecon?icts,theIPCwithSMTcanbeapproximatedasthesum,1.08.ThisapproximationboundsthemaximumIPCthatcanbeachievedbySMT.
Table3summarizestheapproximatedIPCforSMTwithaL2cachemanagedbythestandardLRUreplace-mentpolicyandonewithaL2cachemanagedbyourpar-titioningalgorithm.TheabsoluteimprovementinthetableistheIPCofthepartitionedcasesubtractedbytheIPCofthestandardLRUcase.TherelativeimprovementistheimprovementrelativetotheIPCofthestandardLRU,andiscalculatedbydividingtheabsoluteimprovementbytheIPCofthestandardLRU.Thetableshowsthattheparti-tioningalgorithmimprovesIPCforallcachesizesupto17%.
TheexperimentresultsalsoshowthatSMTshouldmanagecachescarefully.Inthecaseoffourthreadswitha2-MBcache,SMTcanachievetheoverallIPCof2.160fromTable3.However,ifyouonlyconsideronethread(art1),itsIPCisonly0.594whereasitcanachieveanIPCof1.04alone(Figure2).Theperformanceofasinglethreadissigni?cantlydegradedbysharingcaches.More-over,theperformancedegradationbycacheinterferencewillbecomeevenmoresevereasthelatencytothemainmemoryincreases.Thisproblemcanbesolvedbysmartpartitioningofcachememoryforsomecases.Ifthecacheistoosmall,webelievethatthethreadschedulingshouldbechanged.
5.Conclusion
LowIPCcanbeattributedtotwofactors,datadependencyandmemorylatency.SMTmitigatesthe?rstfactorbutnotthesecond.WehavediscoveredthatSMTonlyexacer-batestheproblemwhentheexecutingthreadsrequirelargecaches.Thatis,whenmultipleexecutingthreadsinterfereinthecache,evenSMTcannotutilizeallthefunctionalunitsbecausenotallrequireddataispresentinthemem-ory.
Wehavestudiedonemethodtoreducecacheinterfer-enceamongsimultaneouslyexecutingthreads.Ouron-linecachepartitioningalgorithmestimatesthemiss-ratechar-acteristicsofeachthreadatrun-time,anddynamicallypar-titionsthecacheamongthethreadsthatareexecutingsi-multaneously.Thealgorithmestimatesthemarginalgainsasafunctionofcachesizeandusesasearchalgorithmto?ndthepartitionthatminimizesthetotalnumberofmisses.
Thehardwareoverheadforthemodi?cationspro-posedinthispaperareminimal.Asmallnumberofad-ditionalcountersisrequired.Thecountersareupdatedoncachehits,however,theyarenotonthecriticalpathandsoasmallbuffercanabsorbanyburstiness.Toactuallypartitionthecache,wecanmodifytheLRUreplacementhardwareinasimplewaytotakethevaluesofthecoun-tersintoaccount.Or,wecanusecolumncachingwhichrequiresasmallnumberofadditionalbitsintheTLBen-tries,andasmallamountofoff-critical-pathcircuitrythatisinvokedonlyduringacachemiss.
Thepartitioningalgorithmhasbeenimplementedinatrace-drivencachesimulator.Thesimulationresultsshowthatpartitioningcanimprovethecacheperformanceno-ticeablyoverthestandardLRUreplacementpolicyforacertainrangeofcachesizeforgiventhreads.Usingafull-systemsimulator,theeffectofpartitioningontheinstruc-tionspercycle(IPC)hasalsobeenstudied.Theprelimi-naryresultsshowthatwecanalsoexpectIPCimprovementusingthepartitioningalgorithm.WhilewehavenotusedafullSMTsimulatortogenerateIPCnumbers,thelargeimprovementsobtainedinhitratesleadustobelievethatsigni?cantIPCimprovementswillbeobtainedusingafullSMTsimulator,oronrealhardware.
Thesimulationresultshaveshownthatourpartition-ingalgorithmcansolvetheproblemofthreadinterferenceincachesforarangeofcachesizes.However,partition-ingalonecannotimprovetheperformanceifcachesaretoosmallfortheworkloads.Therefore,threadsthatexecutesi-multaneouslyshouldbeselectedcarefullyconsideringtheirmemoryreferencebehavior.Cache-awarejobschedulingisasubjectofourongoingwork.
EvenwithoutSMT,onecanviewanapplicationasmultiplethreadsexecutingsimultaneouslywhereeachthreadhasmemoryreferencestoaparticulardatastruc-ture.Therefore,theresultofthisinvestigationcanalsobeexploitedbycompilersforaprocessorwithmultiplefunc-tionalunitsandsomecachepartitioningcontrol.
CacheSize(MB)0.250.5120.250.5124
LRU
Hit-rate(%)artmcf8.810.325.763.76.4/6.77.3/7.69.3/10.125.1/25.563.9/63.6Partition
IPCHit-rate(%)
artmcfart+mcf
20.41.0648.020.522.21.06714.517.826.61.08061.619.540.31.18976.833.1
art1+mcf1+art2+mcf2
16.4/15.22.1236.5/3.529.8/11.319.5/18.22.1287.7/4.630.7/15.222.1/21.42.1349.1/32.431.1/13.528.1/25.12.16057.2/73.232.0/16.041.7/41.22.38273.9/86.749.5/26.6
IPC
Abs.Improv.(%)0.0010.0030.0870.1580.0030.0030.0270.3070.404
Rel.Improv.(%)0.090.288.0613.290.140.141.2714.2116.96
1.0651.0701.1671.3472.1262.1312.1612.4562.786
Table3.IPCComparisonbetweenthestandardLRUandthepartitionedLRUstrategyforthecaseofexecutingartandmcfsimultaneously.
Acknowledgements
FundingforthisworkisprovidedinpartbytheDefenseAdvancedResearchProjectsAgencyundertheAirForceResearchLabcontractF30602-99-2-0511,titled“Mal-leableCachesforData-IntensiveComputing”.ThanksalsotoEnochPeserico,DerekChiou,DavidChenandVinsonLeefortheircomments.
[8]D.T.Chiou.ExtendingtheReachofMicroproces-sors:ColumnandCuriousCaching.PhDthesis,MassachusettsInstituteofTechnology,1999.[9]H.S.Stone,J.Turek,andJ.L.Wolf.Optimalpar-titioningofcachememory.IEEETransactionsonComputers,41(9),September1992.[10]G.E.Suh,S.Devadas,andL.Rudolph.Analytical
CacheModelswithApplicationtoCachePartition-internationalconferenceonSuper-ing.Inthe
computing,2001.
References
[1]D.M.Tullsen,S.J.Eggers,andH.M.Levy.Simul-taneousmultithreading:Maximizingon-chipparal-lelism.In22ndAnnualInternationalSymposiumonComputerArchitecture,1995.[2]J.L.Lo,J.S.Emer,H.M.Levy,R.L.Stamm,D.M.
Tullsen,andS.J.Eggers.Convertingthread-levelpar-allelismtoinstruction-levelparallelismviasimultane-ousmultithreading.ACMTransactionsonComputerSystems,15,1997.[3]S.J.Eggers,J.S.Emer,H.M.Levy,J.L.Lo,R.L.
Stamm,andD.M.Tullsen.Simultaneousmulti-threading:Aplatformfornext-generationprocessors.IEEEMicro,17(5),1997.[4]C.Freeburn.ThehewlettpackardPA-RISC8500pro-cessor.Technicalreport,HewlettPackardLaborato-ries,October1998.[5]Compaq.Compaqalphastationfamily.
[6]MIPSTechnologies,Inc.MIPSR10000Microproces-sorUser’sManual,1996.[7]J.L.Henning.SPECCPU2000:MeasuringCPUper-formanceinthenewmillennium.IEEEComputer,July2000.
[11]D.Thi′ebaut,H.S.Stone,andJ.L.Wolf.Improving
diskcachehit-ratiosthroughcachepartitioning.IEEETransactionsonComputers,41(6),June1992.[12]B.Fox.Discreteoptimizationviamarginalanalysis.
ManagementScience,13,1966.[13]C.K.Chow.Determiningtheoptimumcapacityofa
cachememory.IBMTech.DisclosureBull.,1975.[14]B.K.Bershad,B.J.Chen,D.Lee,andT.H.Romer.
Avoidingcon?ictmissesdynamicallyinlargedirect-mappedcaches.InASPLOSVI,1994.[15]D.BurgerandT.M.Austin.Thesimplescalartool
set,version2.0.Technicalreport,UniversityofWisconsin-MadisonComputerScienceDepartment,1997.
-
memo范文
Memo范文1说明性memoMemorandumToAllemployeesofCarsonBankFromRobertDicki…
- memo范文
-
memo写作
样题YouaretheManagingDirectorofacompanywhoseprofitshaverecentlyincr…
-
Memo范文 知名商务英语专家 Memo格式
SituationFloydJonesistheproprietorofthefirmforwhichyouworkMrJoneswantstoacq…
-
memo参考范文
Memosampleletters1告知信息类例题YouareamanageratanauditorscalledGoldinga…
-
memo写作
样题YouaretheManagingDirectorofacompanywhoseprofitshaverecentlyincr…
-
memo范文
Memo范文1说明性memoMemorandumToAllemployeesofCarsonBankFromRobertDicki…
-
memo备忘录
重庆森博国际教育沙坪坝三峡广场新华书店旁立海大厦25楼MEMO1引入memo2memo的定义Amemoisashortoffici…
-
memo,message
MemotofromdatesubjectbodyI商务便函的内容与特点商务便函memorandum简写Memo是同一商业组织内部…
-
english memo
HandoutMemosSample1MEMOToFromDateSubjectKatherineChuRegionalManagerStephenY…