医学科研设计
医学科研设计
第一部分 医学科研设计概述
一、医学科学研究
医学科学研究是医学工作人员主动自觉地结合基础学科的理论和方法,借助精密仪器、对生物个体从病理、免疫、遗传等各方面探索事物(如疾病发生发展及防治效果)客观规律的创新活动。包括总结工作经验,找出存在规律,以启示同行吸取经验教训。
二、医学研究的分类
(一)根据研究目的分
1、基础研究:概括地讲是指从理论上进行探讨的研究。认识人体的生命现象、本质规律、探索疾病发生、发展的机理、药物作用机制研究等。如“肠系膜上静脉的基础解剖与临床应用研究 ”。
2、应用基础研究:发展基础研究成果,将基础研究成果转化为技术形式或者说是将理论转化为技术方法的研究。如人民医院“喉全切除后发音钮的研制及临床应用”。
3、开发研究:是指以推广和应用为目标的,对基础研究和应用研究成果进行重大的、实质性改进的创新研究。如 “海洋水色1号卫星研制”
(二)据研究内容、方法分(即是否对研究对象施加干预)
1、实验研究:研究者根据研究目的,主动的对研究对象施加干预因素,并控制干扰因素的影响,以说明干预因素效果的研究。如 “苦瓜制剂对糖尿病的疗效研究”。实验研究又可分为动物实验(以动物为研究对象的)、临床试验(以病人为研究对象的)和社区干预试验( 以社区人群为研究对象的干预试验。多在某一地区人群中进行,时间长。如地方病、糖尿病等)
2、调查研究:是研究者对研究对象不施加任何干预因素,不改变事物任何条件下,只对研究对象群体作直接观察、询问获得资料的研究方法。如癌症的影响因素调查。
3、资料分析性研究:属于对以往资料再开发、再利用的创新活动。是对以往的系统记录资料通过新的思维、重新分析得出新观点的创新研究。如“252例病毒性肝炎分析”。
(三)根据课题来源分
1、指令性课题:上级主管部门据卫生事业发展需要和下属单位人力、设备、技术水平等条件下达给的课题。如“珠心算训练开发儿童智能的脑机制研究”
2、指导性课题:上级主管部门的招标课题。如国家自然科学基金资助课题、卫生部的、国家的医学攻关课题等。
3、自选性课题:在从事本专业过程中,自选立项的课题。(遇到技术或理论上的问题,需要研究解决,或发现新苗头,结合本学科优势立项)
(四)根据调查涉及的时间分
1、回顾性调查:从现有结果回头去追究因果关系的研究。(“从果追因”)
2、现况调查:调查目前现实情况的研究
3、前瞻性调查:从现有暴露原因去追查与原因有关的结果的研究。(“由因到果”)
三、医学研究的基本程序(略懂)
(一)立题:即提出问题,亦选择确定研究题目,是研究工作最初阶段最难的第一步。
1、科研选题的基本途径:
(1)从指导性课题中选。要及时了解上级各主管部门的招标内容、题目,根据自己从事专业的条件及时拟写标书,争取立项。
(2)从以往研究中善于发现新问题(理论、技术上),再用创新思维改变方向再立项。
(3)在从事本专业过程中,善于积累资料,查阅文献,联想启发,抓新苗头,结合学科优势条件立题。
2、科研选题应掌握原则:重要、可行、科学、新颖、效益高
(二)设计:是制定科研计划的过程,写科研任务书、标书,规划科研实施方案。包括:立题,确定研究目的意义,提出需要研究、分析、解决的问题,确定研究对象、研究方法,研究指标、研究因素安排,实验误差控制,资料处理方法,人员分工,进度计划及经费预算等。
(三)观察或实验:科学分组,采用先进仪器设备熟练操作、严密观察、详细记录。
(四)统计学处理。
(五)理性总结(写论文)
第二部分 实验设计的要素
一、三个基本要素
处理因素、受试对象、实验效应
例如:“苦瓜制剂对糖尿病的疗效研究”
处理因素:苦瓜制剂 受试对象:糖尿病患者 实验效应指标:血糖值、尿糖值
(一)处理因素
按研究目的设定的,对受试对象发生作用的特定因素。一般是人为施加的因素。而参与实验过程,产生混杂效应的非研究因素则称作“非处理因素”,又称混杂因素。
研究者恰当的确定处理因素后,应注意:
1、抓实验中的主要因素研究:即处理因素不宜太多
2、处理因素应标准化:即实验的全过程做到处理因素保持不变。
3、找出非处理因素并严格控制:减少混杂效应,使处理因素的效应充分显示出来
(二)受试对象
选择十分重要,受试对象可分为人和动物两类:
1、对临床病人选择原则:尽量选择诊断明确;年龄、性别、类型、严重程度等一致或相近的;且愿意合作的,即依从性好的。如骨折愈合一例。
2、对动物选择原则是: 首先根据不同课题的研究目的和需要,注意选用种属、品系要纯的;年龄、性别、体重尽量相同或相近的;营养状况好、无疾病的;且要对研究因素反应比较敏感的;价格便宜的。
(三)实验效应
包括效应指标的选择和观察两个方面:
1、效应指标的选择:应尽量选客观指标,不用主观指标。用精确度高的仪器测量,减少系统误差,提高准确度。应尽量用特异性强灵敏度高的指标。
2、效应指标的观察:为避免研究者和受试者的主观偏性,使测量结果更能反映实际情况,应采用盲法或双盲法。
二、实验误差及控制
(一)随机(测量)误差:是由一系列偶然因素引起的不易控制的误差。
(二)系统误差(偏倚)
1、选择偏倚:即实验对象选择不当产生的偏倚。可以合理选择实验对象,随机抽样、分组、保证样本有代表性来加以控制。
2、信息偏倚:即仪器、操作、实验条件、主观因素等原因造成的偏倚。可以经常的校准仪器、实验因素标准化、专人操作等来加以控制。
3、混杂偏倚:即影响实验结果的非处理因素在组间不均衡引起的偏倚。可以按照实验设计的四项基本原则,做好设计,以排除混杂因素的干扰来加以控制。
三、实验设计的基本原则
(一)对照原则
1、对照的意义:
(1)鉴别处理因素有无效应及效应大小。
(2)通过对照组,排除非处理因素的干扰,使处理因素的效应单独显示出来。
2、对照方法:根据研究目的和内容不同而选择。
(1)空白对照:对照组不加任何处理因素的对照。如氯乙烯染毒。
(2)实验对照:安慰剂对照,给对照组施加部分非处理因素的对照。如赖氨酸面包。
(3)自身对照:即实验对照都在同批受试对象身上进行的对照,应用广。
(4)相互对照:各药物组互为对照,临床试验常用。
(5)标准对照:研究时不设对照组,与标准值,参考值范围对照的方法。不提倡用
(二)随机原则
使每个受试对象有同等机会被抽到或被分到各实验组中,消除人为偏性。另外也使受试对象在各实验组与对照组中尽量均衡一致,抵消非处理因素在组间的差别,提高效率。
(三)重复原则
多次重复实验以验证结果的真实性和可靠性,防止把偶然当做必然。
(四)均衡原则
1、均衡的意义:是使实验组与对照组的非处理因素尽可能的齐同一致,以消除或降低非处理因素的影响,提高实验的效率。
2、均衡方法:
(1)交叉均衡:在各实验组中又各设立实验和对照的方法。
(2)分层均衡:将非处理因素按不同水平分成若干层,再在每层中安排处理因素的方法。
第三部分 几种常用的科研设计方法
一、析因设计(Factorial Design)
(一)何为析因设计
析因设计是一种多因素的交叉分组设计。它不仅可检验每个因素各水平间的差异,而且可检验各因素间的交互作用。两个或多个因素如存在交互作用,表示各因素不是各自独立的,而是一个因素的水平有改变时,另一个或几个因素的效应也相应有所改变;反之,如不存在交互作用,表示各因素具有独立性,一个因素的水平有所改变时不影响其他因素的效应。
(二)析因设计的有关术语(通过下表进行理解)

1、 单独效应:其它因素水平固定时,同一因素不同水平间效应的差别。此例中,
如B因素固定在1水平时,A因素的单独效应为4
2、主效应:某一因素各水平单独效应的平均差别。此例中,
A的主效应=[(a2b2- a1b2)+(a2b1- a1b1)]/2=[16+4]/2=10
B的主效应=[(a1b2- a1b1)+( a2b2- a2b1)]/2 =[10+22]/2=16
3、交互效应若一个因素的单独效应随另一个因素水平的变化而变化,且变化的幅度超出随机波动的范围时,称该两因素间存在交互效应。此例中,
AB交互=[( a2b2- a1b2)-(a2b1- a1b1)]/2= (16-4)/2=6
AB交互=[( a2b2- a2b1)-(a1b2- a1b1)]/2=(22-10)/2=6
4、交互作用的均值表示方式
 表示4个处理组A1B1,A2B1 ,A1B2,A2B2对应的总体均值
表示4个处理组A1B1,A2B1 ,A1B2,A2B2对应的总体均值
 (1)存在交互效应 :
(1)存在交互效应 :
 (2)正交互(协同)作用: 表示两因素联合作用大于其单独作用之和
(2)正交互(协同)作用: 表示两因素联合作用大于其单独作用之和
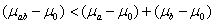 (3)负交互(拮抗)作用: 表示两因素联合作用小于其单独作用之和。
(3)负交互(拮抗)作用: 表示两因素联合作用小于其单独作用之和。
(三)实验设计方法
1、确定设计模型
2、将试验单位随机分配
(四)实验结果与分析——方差分析 (自己填上吧(*^__^*) )
1、总变异分离成组间变异和组内变异

2、将组间变异分解出主效应项和交互效应项
3、得出结论
(五)正确应用析因设计
1、 析因设计的评价
(1)析因设计比一次只考虑一个因素的实验效率高,从得到的信息来看,节省了组数和例数;
(2)当考虑的因素较多,处理组数会很大(比如4个因素各3个水平的处理数为34=81种),这时采用析因设计不是最佳选择,可选用正交设计。
(3)析因设计的优点之一是可以考虑交互作用,但有时高阶交互作用是很难解释的,实际工作中常只考虑一、二阶交互作用。
2、 析因设计与完全随机设计的区别
(1)完全随机析因设计与完全随机设计表面类似,但是其设计理念不同,方差分析方法不同。完全随机设计为单因素设计,不能分析因素间交互作用;析因设计为多因素设计,可以分析交互作用。
(2)将析因设计的资料做完全随机设计的方差分析,会掩盖交互作用,得出错误的结论。
二、正交设计(Orthogonal Design)
(一)定义
正交设计是按正交表(orthogonal layout)安排部分试验,即各因素各水平的组合方式要查正交表才能决定,根据正交表安排各因素各水平的部分组合。
1、正交设计和析因设计的不同(略懂即可)
(1)析因设计:G个处理组是各因素各水平的全面组合;
(2)正交设计:非全面试验,或称析因试验的部分实施,G个处理组是各因素各水平的部分组合。是一种高效率、快速、经济的实验设计方法 。例如,对于有A、B、C、D、E五个因素、每个因素有2个水平的试验,按析因设计共有G=25=32个处理,但用正交设计,可选1/2实施方案,即有(1/2)G=16个处理,或1/4实施方案,即有(1/4)G=8个处理。
(3)由于正交设计是析因试验的部分组合,所以正交设计只能分析各因素的主效应和低阶交互作用。因此,在正交设计时通常要根据生物学或医学专业知识,并假定“各因素间没有交互作用”(只分析有意义的主效应,以牺牲分析各因素交互作用为代价)或“只有一阶交互作用”(部分重要因素的一阶交互作用项)。
2、正交表的设计与使用(正交表是正交试验设计的主要工具)
(1)每个正交表都有一个表头符号,记作LN(mk),表示该正交表有N行k列,每一列由整数1,2,…,m组成。
(2)用表LN(mk)安排试验时,N表示试验次数;k表示最多可以安排的因素个数,m表示各因素的水平数。例如L8(27)正交设计表表示,8次试验,可以最多安排7个因素,每个因素各有2个水平。
3、正交表的特点
(1)每一列中不同数字出现的次数相同——整齐可比性
(2)任两列不同数对出现的次数相同——均匀分散性
4、正交表的类型
(1)齐水平正交表:各因素的水平数相等。如L8(27)、L25(56 )
(2)混合水平正交表:各因素水平数不都相等。如L16(42×29 )
5、选择正交表的原则
(1)各实验因素的水平数最好相等。
当m=2时,可选L4(23)、L8(211)、L16(215)等;
当m=3时,可选L9(34)、L18(37)、L27(313)等;
当m=4时,可选L16(45)、L32(49)等。
当水平数不等时,则可选L8(4×24)、L16(42×24)、L18(2×37)等。
(2)操作简单的试验或希望得到较多的信息,可选择N较大的正交表。反之,操作复杂或成本较高的试验,可选择N较小的正交表。
(3)分析交互作用(主要是两因素之间的交互作用),选k较大的正交表。若已知因素间的交互作用很小,则选k较小的正交表。
(二)正交实验设计步骤
1、根据研究目的,确定观察指标,且观察指标应满足方差分析的条件
2、拟订观察指标所有可能的影响因素及水平数
3、根据专业确定因素间是否存在交互作用
4、确定实验次数:人、财、物时间等
5、正交表表头设计
(三)统计分析——方差分析的步骤(自己填上吧(*^__^*) )重复和不重复实验略有不同
(四)正交设计的特点
1、正交设计具有正交性,它可估计出因素的主效应及低阶交互作用。
2、正交设计的数据分析较为简单,既可直观分析,又可进行方差分析。
3、正交设计多用于各因素的水平数不多时,因为其试验次数至少是水平数的平方。
(五)正交表的灵活应用(不作要求)
三、拉丁方设计(Design of Latin Square)
(一)拉丁方设计基本概念
1、r阶/r×r拉丁方:用r个拉丁字母排成r行r列的方阵,使每行每列中每个字母都只出现一次,这样的方阵叫r阶/r×r拉丁方 。按拉丁方的字母、行、列安排处理及影响因素的试验称为拉丁方试验。
2、拉丁方设计的优缺点
(1)优点:可大大减少试验次数,尤其适合于动物实验;可以考核3个因素,也可以考核1或2个处理因素,可同时控制两个因素。
(2)缺点:要求处理数等于拉丁方的行、列数,但一般的实验不易满足;数据缺失会增加统计分析的难度。
3、拉丁方设计要求
(1)必须是三个因素,且三个因素的水平数相等
(2)处理数等于拉丁方的行、列
(3)行间、列间处理无交互作用
(4)各行、列、处理的方差齐
(二)拉丁方设计方法
1、根据研究水平数,选择基本拉丁方:3×3 或者4×4 或者5×5,根据试验要求而定;
2、拉丁方的行、列随机化:通过读取随机数字将行列加以对调;
3、随机分配处理
(1)对各因素事先编号
(2)对实验对象进行随机化处理,并对实验随机安排处理
(三)实验结果进行统计分析(见表)

其中r代表行数或者列数
(四)进行多组均数差别的多重比较
1、LSD-t检验:比较k组中某一对或几对在专业上有特殊意义的均数之间有无差别
2、SNK-q检验: 两两比较
3、Dunnet-t检验:多个试验组与一个对照组的比较
四、序贯设计(Sequential Design)
(一)序贯试验定义
序贯试验是一种边试验,边统计的方法,按照观察对象进入试验的次序,每得到一例或一个阶段的观察结果就进行一次统计分析,一旦得出拒绝H0的结论,就可停止试验,否则,根据具体情况作出继续或停止试验的决定。
(二)序贯试验适用范围
1、 适用于临床研究以避免以后的病人接受无效的治疗。
2、也用于大的、昂贵的动物实验,或以小组为单位的小动物实验。
(三)序贯试验评价
1、优点
(1)样本量为变数,适合于临床应用(可避免研究对象量过小造成的缺陷);
(2)节省研究对象人数,符合伦理要求(可以避免由于不切实际地增加样本量);
(3)试验周期缩短。
2、局限性:
(1)只能对一个特定的问题作出回答,不能回答几个相关问题。
(2)不适用于几个医疗机构同时进行的联合试验。
(3)只适用于单指标试验,不适用于大样本试验和慢性病疗效观察。
(四)序贯设计的分类 (自己画个图吧(*^__^*) )
(五)序贯设计的实验步骤
1、规定试验标准:包括试验的灵敏度、有效及无效的水平、第一二类错误的概率α和β
2、利用公式或工具绘出序贯试验图,即试验的边界线
3、逐一将试验结果在序贯图上绘出实验线
4、根据实验线触及不同边界做出结论:实验线触及有效线认为实验有效,触及无效线认为实验无效。
(六)序贯设计的具体实例及方法(最好自己总结一下啦~~)
五、交叉设计(Cross-over Design)
(一)定义
交叉设计是在自身配对设计的基础上发展而成的双因素设计,它可在同一病人身上观察两种或多种处理的效应。
(二)交叉设计的基本模式
(阶段一) (阶段二)


 (按纳入标准)
(按纳入标准)

(三)交叉设计的统计分析——方差分析
方差分析表

可以解决两个问题,即两种处理间和两个阶段间的差异有无统计学意义
(四)交叉设计评价
1、优点:节约样本,可控制时间因素和个体差异对处理的影响;每一个实验对象同时接受实验因素和对照因素,每个患者利益均等(符合医德)。
2、缺点:设计要求高,统计分析较复杂。
3、实验注意要素:有间歇期,病程比较长,要采用盲法。
六、临床试验(Clinical Trial)(这个部分不是重点内容)
(一)临床试验的定义
以病人为研究对象,比较临床干预措施和对照措施的效果及其临床价值的一种前瞻性研究。目的是通过应用现代临床研究方法,有效地提高病人的治愈率,降低致残率和病死率,促进病人恢复健康
(二)临床治疗试验的特点
1、由于以病人为研究对象,必须在保证病人安全的前提下进行试验,而且应符合医学伦理道德要求。
2、必须设立对照
3、人为的干预措施
4、前瞻性研究
(三)临床试验的分期(略看)
1、第一期:临床前期试验或称小规模临床试验,是初步的临床药理学及人体安全性评价试验,观察人体新药的耐受程度和药物代谢动力学。由于其数量少,无对比研究,所以得出的结论具有不确定性的弱点。
2、第二期:正式临床试验,主要评价药物疗效,要求用随机对照试验设计方案进行设计。又可分为两个阶段。第一阶段在指定的医院小规模进行,随机盲法对照临床试验,对新药有效性及安全性作出初步评价,推荐临床给药剂量。第二阶段要求在3个或3个以上指定的医院同时进行随机对照试验多中心临床试验,进一步评价有效性和安全性。
3、第三期:扩大的对比临床观察,广泛地观察新药的各种适应症、不良反应、毒性和药理作用,是对新药的治疗作用与安全性进行确认的阶段。
4、第四期:新药上市后监测,目的是考察广泛使用条件下药物的疗效和不良反应。评价使用风险以及改进给药剂量等。
※(四)临床试验设计的基本步骤和内容 (这个重点记忆一下)
1、选题:必须从先进性、科学性、可行性全面考虑,确定既有创新点又有可行性的课题。
2、选择受试对象:应根据研究的目的、要求、试验所需的病例数以及技术力量等选择不同来源的病例。包括选定诊断标准与纳入标准。
3、设置对照组并进行随机化分组
4、避免偏性的重要技巧—盲法(Blind Method)
是指按试验方案的规定,尽量不让临床试验的受试者、研究者、参与疗效和安全性评价的人员知道病人接受的是何种药物,从而避免他们对试验结果的人为干扰。
(1)非盲(open-label):受试者与研究者都了解分组情况。如干预为外科手术,生活方式的改变等。缺点是可能由此而产生偏性。
(2)单盲(single-blind):一般只是受试者(病人)被盲,简单易行,但研究者产生偏性的可能性仍然存在。单盲试验仅仅可以避免来自病人主观因素的偏倚。
(3)双盲(double blind):临床试验中受试者、研究者都不知治疗分配程序,不知道哪一个病例属于试验组或对照组。双盲可避免先入为主,使偏性的可能性减少。但是对可能出现的副反应不易及时作出应急措施。
(4)三盲:在受试者、研究者,资料分析评价人员都不清楚分组情况,从而是研究结果的评价得以客观地进行。但是这种方法的操作性很困难。
5、效应指标的选择:完整性、关联性、客观性、精确性、稳定性、灵敏性
(五)诊断试验的评价基本指标(重在理解)
诊断试验(diagnostic test):是确定疾病的试验方法。在临床医学中,医学诊断对患者的诊治过程及其预后具有重要作用。
基本方法是用待评价的诊断试验和标准诊断方法(又称金标准,Gold Standard)检测相同的受验对象,并进行比较。

 1、灵敏度(sensitivity,Se)又称真阳性率,是实际患病且被诊断试验诊为患者的概率,即患者被判为阳性的概率。反映检出患者的能力,该值愈大愈好。
1、灵敏度(sensitivity,Se)又称真阳性率,是实际患病且被诊断试验诊为患者的概率,即患者被判为阳性的概率。反映检出患者的能力,该值愈大愈好。
2、特异度(specificity,Sp)又称真阴性率,是实际未患病则被诊断试验诊为非患者的概率,即非患者被判为阴性的概率,反映鉴别非患者的能力,该值愈大愈好。

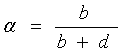 3、误诊率(mistake diagnostic rate,α)又称假阳性率,是实际未患病而被诊断试验判为患者的概率,即非患者中被判为阳性的概率,反映将非患者诊断错误的可能程度。该值愈小愈好。
3、误诊率(mistake diagnostic rate,α)又称假阳性率,是实际未患病而被诊断试验判为患者的概率,即非患者中被判为阳性的概率,反映将非患者诊断错误的可能程度。该值愈小愈好。
4、漏诊率(omission diagnostic rate,β)又称假阴性率,是实际患病而被诊断试验判为非患者的概率,即患者中被判为阴性的概率,反映将患者诊断错误的可能程度。该值愈小愈好。

第四部分 抽样方法
一、单纯随机抽样(Simple Random Sampling)
(一)定义:根据研究目的选定总体,首先对总体中所有的观察单位编号,遵循随机原则,采用不放回抽取方法,从总体中随机抽取一定数量观察单位组成样本。可采用随机数字法和抽签法
(二)优缺点
1、对所有观察单位编号,当数量大时,有难度;
2、抽样误差的计算较方便。
(三)抽样误差的估计(了解即可)

二、系统抽样(Systematic Sampling)
(一)定义:先将总体的观察单位按某顺序号等分成n个部分再从第一部分随机抽第k号观察单位,依次用相等间隔,机械地从每一部分各抽取一个观察单位组成样本。又称等距/机械抽样。
(二)优缺点
1、抽样方法简便;
2、易得到一个按比例分配的样本,抽样误差较小;
3、仍需对每个观察单位编号;
4、当观察单位按顺序有周期趋势或单调性趋势时,产生明显偏性;
(三)抽样误差:无固定的计算公式,常按单纯随机抽样方法来计算,与总体的性质和被抽样个体间的间隔有关。
三、整群抽样(Cluster Sampling)
(一)定义:先将总体划分为若干个“群”组,每个群包括若干个观察单位,再随机抽取n个群,被抽到的各群的全部观察单位则组成样本。
(二)优缺点
1、在较大规模的现场调查中,易组织,较节省。
2、若各群间的差异较大,该抽样方法的误差较大。
(三)关于抽样误差:无固定计算公式。
四、分层抽样(Stratified Sampling)
(一)定义:先将总体按某种特征分成若干层,再从每一层内随机抽取一定数量的观察单位,合起来组成样本。
1、按比例分配:按总体各层观察单位数的多少分配。

2、 最优分配:按各层观察单位数多少及其变异大小分配。


(二)优缺点
1、在一定程度上控制了抽样误差,尤其是最优分配法;
2、应尽量使层内差别小而层间差别大,以提高效率;
3、事先应了解各层的总体含量,最优分配还应了解标准差。
五、样本含量的估计(了解即可,公式不需要记忆)
(一)先决条件
1、容许误差,预计样本统计量与相应总体参数的最大相差控制在什么范围。常取可信区间长度一半。
2、所调查总体标准差,若不了解,须通过预试验的标准差S或前人的资料作出估计;
3、第一类错误的概率;
4、对有限总体抽样时,还须了解总体观察单位数。
(二)计算公式

第五部分 调查设计
一、调查(survey)的概念
(一)定义:深入实际,了解情况,即采用问卷或结构式访问的方法,有目的地、直接从某社会群体或其样本收集资料,并通过对资料的分析来认识社会现象及其规律的研究方式。比起试验设计来讲,调查设计较为被动。
(二)调查研究分类(略懂即可)
1、按调查的范围可分为全面调查和非全面调查,非全面调查又包括抽样调查和典型调查。
2、按调查涉及的时间划分为病例—对照研究和队列研究。
3、按抽取样本的方式划分可分为概率抽样调查与非概率抽样调查。
二、调查内容与步骤
(一)明确调查目的和指标
(二)确定调查对象和观察单位
(三)确定调查方法和搜集原始资料的方式:可以通过直接观察法、采访法等
(四)确定调查项目和调查表:确定调查项目、分析项目以及项目形式(开放还是闭锁)
(五)估计样本含量:利用经验法、查表法和统计计算法进行估计
(六)制订调查的组织计划
(七)调查的整理与分析计划
(八)调查的质量控制
三、调查表设计(略看,不作为重点内容)
(一)调查表的组成部分:标题、说明、被访者基本情况、调查主要内容、编码、作业证明的记载
(二)调查表设计应考虑的问题
1、调查表的作用:在收集数据时,如果用调查表调查是最好的方法,可决定使用调查表;
2、表中每一种问题有一明确的目的,需明确要调查什么内容
3、最大限度的保证信息质量;
4、问题流畅:当从一个问题转到另一个问题时,注意逻辑关系、用词和语气,如从一般到个别、容易到困难等。
5、尊重应答者的尊严和隐私
6、采用一些保密方法
(三)调查表的考评
1、效度(validity)考评【重在理解】
效度即调查表的有效性和正确性,即正确度。意指调查表确实测定了它打算测定的特征(而不是其他特征)以及测定的程度。效度越高,说明调查表的结果越能显示其所测对象的真正特征。
(1)内容效度(content validity):也称内在效度(intrinsic validity),是指调查表在多大程度上表示了所测特征的范畴,即调查表是否包含足够的条目来反映所测内容。
(2)结构效度(construct validity):也称构思效度或特征效度(trait validity),说明调查表的构造是否符合有关的理论构想和框架,也就是检验调查表是否真正测量了所提出的理论构思。因而结构效度是最重要的效度指标之一。
(3)标准关联效度(criterion-related validity):也称效表效度(criterion validity),是调查表得分与某种外部标准(效标)之间的关联程度,常用测量得分与效度标准之间的相关系数表示。外部标准指该调查表以外的另一些客观指标或人们熟知的另一种调查表。
2、信度(reliability)考评【心理学量表常用】
信度指调查表测量结果的可靠性、稳定性和一致性,亦即精确度。一般认为信度反映测量中偶然误差引起的变异程度。
(1)重测信度(test-retest reliability):在实际调查中,重测信度一般用两次测定间的相关系数表示。
(2)分半信度(split-half reliability):是在一次测量后将条目分为等价的两部分,分别计算两部分的得分,并以其相关系数作为信度指标。
(3)内部一致性信度(Internal consistent reliability):是分半信度的推广。它无需将条目分成两部分,而是以条目之间的联系程度对信度做出评估。
3、可接受性(acceptability)【略看】
可接受性是指被测定者对调查表的接受程度,要有以下几个特征:
(1)简单性,条目少容易理解。
(2)内容为被测者所熟悉,认为有意义(与其生活及健康相关)。
(3)容易填写,看完简短的“填表说明”后即知如何完成。
(4)完成调查表所需的时间较少。一般认为5~30分钟为宜。
四、随机应答技术(Randomized Response Techniques RRT)【仅供了解,最多选择或填空】
(一)定义:随机化回答是指在调查中使用特定的随机化装置,使得被调查者以预定的概率来回答敏感性问题。这一技术的宗旨就是最大限度地为被调查者保守秘密,从而取得被调查者的信任。
(二)随机化应答模型
1、沃纳模型:1965年由Warner提出的,其设计思想是向被调查者显示两个与敏感性问题(具有特征A)有关,但完全对立的问题,让调查者按预定的概率从中选一个回答,调查者无权过问被调查者回答的是哪一个问题,从而起到了为被调查者保密的效果。
2、西蒙斯模型:1967年由西蒙斯提出的,其基本思想仍以沃纳模型为基础,但有一些改进,它将沃纳模型中与敏感性问题相对的具有特征A的问题改为一个与敏感性问题不相关的其它问题。
3、“随机变量和”回答模型
(三)随机应答技术的步骤
1.向应答者提出一对问题:可以设置两个问题相关联或者无关联;
2.设置一个随机装置进行调查;
3.根据概率理论进行计算。
-
医学科研论文的一般格式
医学科研论文的一般格式科技成果不是论文但论文却是反应科技成果的一种重要形式是研究者运用逻辑思维对其研究成果所作的一种表述表述的方法…
-
医学科研设计与论文写作
科研选题原则1科学性原则2先进性原则方法提高资料搜集的准确性和可靠性盲法分类普查抽样调查单纯随机抽样系统署名凡参与了研究的实质性工…
-
医学科研课题设计与论文撰写
医学科研课题设计与论文撰写txt51自信是永不枯竭的源泉自信是奔腾不息的波涛自信是急流奋进的渠道自信是真正的成功之母医学科研课题设…
-
医学科研设计与论文写作---06年精华版
红色均为历年考题一医学科研的程序1科研选题原则06年考试的简答题1科学性原则2先进性原则3可行性原则4创新性原则原始创新在所研究领…
-
第十四章 临床医学科研设计与论文的撰写
第十四章临床医学科研设计与论文的撰写撰写临床医学科研设计书研究论文和医学文献综述是临床医师和研究人员的一项基本功也是工作总结和交流…
- 广东省医学科研基金项目结题报告书_50215
-
广东省医学科研基金项目结题报告书
佛山市医学科学技术研究计划课题结题报告书项目编号项目负责人项目名称填报单位章本报告一式二份双面打印经区卫生局或单位市直审核后报市卫…
-
广东省医学科研基金项目结题报告书
附件1广州市医药卫生科技项目中止报告书项目编号项目负责人项目名称填报单位章下一页本报告一式三份双面打印经主管单位审核后报市卫生局
-
医学科研项目申请书
重庆市卫生局医学科学技术研究项目申请书项目或课题名称项目类别重点项目面上项目申报单位协作单位项目或课题负责人研究起止年限地址邮编联…
-
广东省医学科研基金项目结题报告书
附件2江门市医学科学技术研究计划课题结题报告书项目编号项目负责人项目名称填报单位章报告一式三份双面打印经区卫生局或单位市直审核后报…
- 广东省医学科研基金项目结题报告书