《数据挖掘实训》weka实验报告
《数据挖掘实训》课程
论文(报告、案例分析)
院 系 信 息 学 院
专 业 统 计
班 级 10级统计 3 班
学生姓名 李健
学 号 2010210453
任课教师 刘 洪 伟
20##年 01月17日
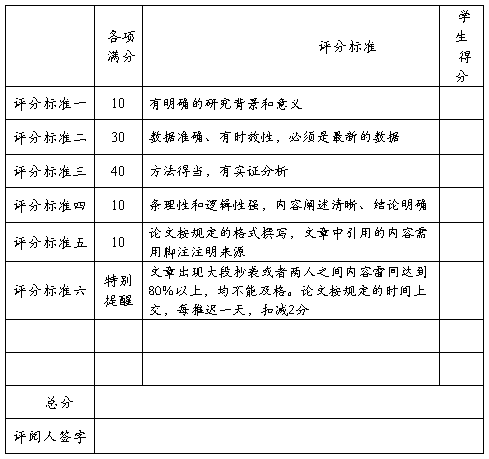
课程论文评分表
《数据挖掘实训》课程论文
选题要求:
根据公开发表统计数据,请结合数据挖掘理论与方法,撰写一篇与数据挖掘领域相关的论文。
写作要求:
(1)数据准确、有时效性,必须是最新的数据。
(2)文章必须有相应的统计方法,这些统计方法包括以前专业课中学到的任何统计方法,如参数估计、假设检验、相关与回归、多元统计等等。
(3)论文的内容必须是原创,有可靠的分析依据和明确的结论。
(4)论文按照规定的格式化撰写;
(5)字数不少于2000字。
数据挖掘(WEKA软件)实验报告
统计学 专业 学生 李健 学号 2010210453
关键词:数据挖掘;游玩;因素;WEKA
本次实验指在熟练的运用软件weka进行数据处理,其中包括数据准备,关联规则等同时了解weka的基本用法。
一、软件介绍
1简介
数据挖掘、机器学习这些字眼,在一些人看来,是门槛很高的东西。诚然,如果做算法实现甚至算法优化,确实需要很多背景知识。但事实是,绝大多数数据挖掘工程师,不需要去做算法层面的东西。他们的精力,集中在特征提取,算法选择和参数调优上。那么,一个可以方便地提供这些功能的工具,便是十分必要的了。而weka,便是数据挖掘工具中的佼佼者。
WEKA的全名是怀卡托智能分析环境(Waikato Environment forKnowledge Analysis),是由新西兰怀卡托(Waikato)大学开发的机器学习软件,纯Java技术实现的开源软件,遵循于GNU General Public License,跨平台运行,集合了大量能承担数据挖掘任务的机器学习算法,分类器实现了常用ZeroR算法、Id3算法、J4.8算法等40多个算法,聚类器实现了EM算法、SimpleKMeans算法和Cobweb算法3种算法,能对数据进行预处理、分类、回归、聚类、关联规则以及在新的交互式界面上的可视化。2oo5年8月,在第11届ACM SIGKDD国际会议上,怀卡托大学的WEKA小组荣获了数据挖掘和知识探索领域的最高服务奖,WEKA系统得到了广泛的认可,被誉为数据挖掘和机器学习历史上的里程碑,是现今最完备的数据挖掘工具之一。WEKA使用的是一种叫做arff(Attribute—Relation File Format)的数据文件结构。这种arff文件是普通的ASCII文本文件,内部结构很简单,主要是测试算法使用的轻量级的数据文件结构。arff文件可以自己建立,也可通过JDBC从Oracle和Mysql等流行数据库中获得。整个arf文件可以分为两个部分。第一部分给出了头信息(Head information),包括关系声明(Relation Declaration)和属性声明(AttributeDeclarations)。第二部分给出了数据信息(Datainformation),即数据集中给出的数据。关系声明的定义格式为:@relation<relation—name>;属性声明的定义格式为:@attribute<attribute—name><datatype>;数据信息的定义格式为独占一行的@data,后面跟着的就是数据信息。
2.安装
Weka的官方地址是http://www.cs.waikato.ac.nz/ml/weka/。点开左侧download栏,可以进入下载页面,里面有windows,mac os,linux等平台下的版本,我们以windows系统作为示例。目前稳定的版本是3.6。
如果本机没有安装java,可以选择带有jre的版本。下载后是一个exe的可执行文件,双击进行安装即可。
安装完毕,打开启动weka的快捷方式,如果可以看到下面的界面,那么恭喜,安装成功了。
共有4个应用,分别是
1)Explorer
用来进行数据实验、挖掘的环境,它提供了分类,聚类,关联规则,特征选择,数据可视化的功能。(An environment for exploring data with WEKA)
2)Experimentor
用来进行实验,对不同学习方案进行数据测试的环境。(An environment for performing experiments and conducting statistical tests between learning schemes.)
3)KnowledgeFlow
功能和Explorer差不多,不过提供的接口不同,用户可以使用拖拽的方式去建立实验方案。另外,它支持增量学习。(This environment supports essentially the same functions as the Explorer but with a drag-and-drop interface. One advantage is that it supports incremental learning.)
4)SimpleCLI
简单的命令行界面。(Provides a simple command-line interface that allows direct execution of WEKA commands for operating systems that do not provide their own command line interface.)
二、实验内容
1.选用数据文件为:small_dataset中的weather.arff数据文件

2.在WEKA中点击explorer 打开文件 weather.arff
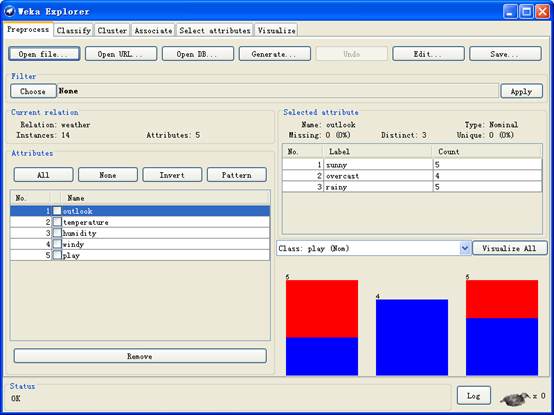
3.对数据整理分析


4.将数据分类:单机classify——在test options中 选择第一项(Use training set)——点击classifier下面的choose 按钮 选择trees中的J48



由上图可知该树有5个叶子
是否出去游玩由天气晴朗(sunny)、天气预报(overcast)以及阴雨天(rainy)因素决定
5. 关联规则
我们打算对前面的“bank-data”数据作关联规则的分析。用“Explorer”打开“bank-data-final.arff”后,切 换到“Associate”选项卡。默认关联规则分析是用Apriori算法,我们就用这个算法,但是点“Choose”右边的文本框修改默认的参数,弹 出的窗口中点“More”可以看到各参数的说明。
7.切换到“Associate”选项卡。默认关联规则分析是用Apriori算法,我们就用这个算法
1), 将经过离散化的数据存入subset example1.arff
2), 点击“Choose”旁边的文本框会弹出新窗口以修改离散化的参数。
3), 现在我们计划挖掘出支持度在10%到100%之间,并且lift值超过1.5且lift值排在前100位的那些关联规则。numRules”设为100,metrictype 由 confidence改为lift 。其他选项保持默认即可。
点击start 输出100个数据
Best rules found:
1. humidity=80.5_max 7 ==> play=no 4 conf:(0.57) < lift:(1.6)> lev:(0.11) [1] conv:(1.13)
2. play=no 5 ==> humidity=80.5_max 4 conf:(0.8) < lift:(1.6)> lev:(0.11) [1] conv:(1.25)
3. outlook=overcast 4 ==> play=yes 4 conf:(1) < lift:(1.56)> lev:(0.1) [1] conv:(1.43)
4. play=yes 9 ==> outlook=overcast 4 conf:(0.44) < lift:(1.56)> lev:(0.1) [1] conv:(1.07)
5. humidity=0_80.5 windy=FALSE 4 ==> play=yes 4 conf:(1) < lift:(1.56)> lev:(0.1) [1] conv:(1.43)
6. play=yes 9 ==> humidity=0_80.5 windy=FALSE 4 conf:(0.44) < lift:(1.56)> lev:(0.1) [1] conv:(1.07)
7. outlook=rainy 5 ==> temperature=0_74.5 4 conf:(0.8) < lift:(1.4)> lev:(0.08) [1] conv:(1.07)
8. temperature=0_74.5 8 ==> outlook=rainy 4 conf:(0.5) < lift:(1.4)> lev:(0.08) [1] conv:(1.03)
9. humidity=0_80.5 7 ==> play=yes 6 conf:(0.86) < lift:(1.33)> lev:(0.11) [1] conv:(1.25)
10. play=yes 9 ==> humidity=0_80.5 6 conf:(0.67) < lift:(1.33)> lev:(0.11) [1] conv:(1.13)
三、总结:
通过实践周的学习,我们不仅继续学习了R还学习了Weka软件的应用。使我重新学习了一下数据挖掘的相关概念、知识和软件的应用,理解了数据挖掘的用途和使用步骤。在此过程中学会了运用各个模块的分析方法。通过本次实训操作,也认识到了数据挖掘对大量的数据进行探索后,能揭示出其中隐藏着的规律性内容,并且由此进一步形成模型化的分析方法。可以建立整体或某个业务过程局部的不同类型的模型,可以描述发展的现状和规律性,而且可以用来预测当条件变化后可能发生的状况。经过这一系列的系统学习,我们不仅能研究有关花种问题,同时更能处理好其他相关类问题的研究。
参考文献
[1] 数据挖掘教程
[2] 韩家炜. 数据挖掘概念与技术:机械工业出版社,2012
第二篇:(电子商务)weka实验
项 目 列 表







-
数据挖掘WEKA实验报告
数据挖掘WAKA实验报告数据挖掘WAKA实验报告1数据挖掘WAKA实验报告一WEKA软件简介在我所从事的证券行业中存在着海量的信息…
-
《数据挖掘实训》weka实验报告
论文报告案例分析院系信息学院专业统计班级10级统计3班学生姓名李健学号20xx210453任课教师刘洪伟20xx年01月17日课程…
-
数据挖掘实验报告 Weka的数据聚类分析
甘肃政法学院本科生实验报告2姓名学院计算机科学学院专业信息管理与信息系统班级实验课程名称数据挖掘实验日期指导教师及职称实验成绩开课…
-
数据挖掘weka数据分类实验报告
一实验目的使用数据挖掘中的分类算法对数据集进行分类训练并测试应用不同的分类算法比较他们之间的不同与此同时了解Weka平台的基本功能…
-
weka实验报告
数据挖掘实验报告基于weka的数据分类分析实验报告姓名学号1实验基本内容本实验的基本内容是通过使用weka中的三种常见分类方法朴素…
-
数据挖掘WEKA实验报告
数据挖掘WAKA实验报告数据挖掘WAKA实验报告1数据挖掘WAKA实验报告一WEKA软件简介在我所从事的证券行业中存在着海量的信息…
-
数据挖掘实验报告 Weka的数据聚类分析
甘肃政法学院本科生实验报告2姓名学院计算机科学学院专业信息管理与信息系统班级实验课程名称数据挖掘实验日期指导教师及职称实验成绩开课…
-
weka实验报告
数据挖掘实验报告基于weka的数据分类分析实验报告姓名学号1实验基本内容本实验的基本内容是通过使用weka中的三种常见分类方法朴素…
-
数据挖掘weka数据分类实验报告
一实验目的使用数据挖掘中的分类算法对数据集进行分类训练并测试应用不同的分类算法比较他们之间的不同与此同时了解Weka平台的基本功能…
-
WEKA数据挖掘实验报告
WEKA实验报告一数据集实验采用Wisconsin医学院的WilliamHWolberg博士提供的乳腺癌的数据样本所有数据来自真实…
-
weka实验报告
DWampDM课程实验报告班级信管111姓名陈丽华学号20xx08071131一实验目的验证二实验内容一聚类分析1数据准备1数据文…