数据挖掘weka数据分类实验报告
一、实验目的
使用数据挖掘中的分类算法,对数据集进行分类训练并测试。应用不同的分类算法,比较他们之间的不同。与此同时了解Weka平台的基本功能与使用方法。
二、实验环境
实验采用Weka 平台,数据使用Weka安装目录下data文件夹下的默认数据集iris.arff。
Weka是怀卡托智能分析系统的缩写,该系统由新西兰怀卡托大学开发。Weka使用Java写成的,并且限制在GNU通用公共证书的条件下发布。它可以运行于几乎所有操作平台,是一款免费的,非商业化的机器学习以及数据挖掘软件。Weka提供了一个统一界面,可结合预处理以及后处理方法,将许多不同的学习算法应用于任何所给的数据集,并评估由不同的学习方案所得出的结果。
三、数据预处理
Weka平台支持ARFF格式和CSV格式的数据。由于本次使用平台自带的ARFF格式数据,所以不存在格式转换的过程。实验所用的ARFF格式数据集如图1所示
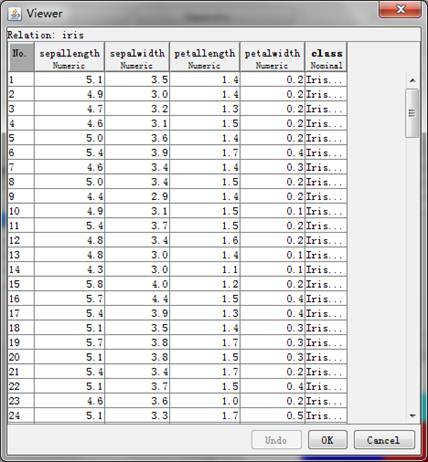
图1 ARFF格式数据集(iris.arff)
对于iris数据集,它包含了150个实例(每个分类包含50个实例),共有sepal length、sepal width、petal length、petal width和class五种属性。期中前四种属性为数值类型,class属性为分类属性,表示实例所对应的的类别。该数据集中的全部实例共可分为三类:Iris Setosa、Iris Versicolour和Iris Virginica。
实验数据集中所有的数据都是实验所需的,因此不存在属性筛选的问题。若所采用的数据集中存在大量的与实验无关的属性,则需要使用weka平台的Filter(过滤器)实现属性的筛选。
实验所需的训练集和测试集均为iris.arff。
四、实验过程及结果
应用iris数据集,分别采用LibSVM、C4.5决策树分类器和朴素贝叶斯分类器进行测试和评价,分别在训练数据上训练出分类模型,找出各个模型最优的参数值,并对三个模型进行全面评价比较,得到一个最好的分类模型以及该模型所有设置的最优参数。最后使用这些参数以及训练集和校验集数据一起构造出一个最优分类器,并利用该分类器对测试数据进行预测。
1、LibSVM分类
Weka 平台内部没有集成libSVM分类器,要使用该分类器,需要下载libsvm.jar并导入到Weka中。
用“Explorer”打开数据集“iris.arff”,并在Explorer中将功能面板切换到“Classify”。点“Choose”按钮选择“functions(weka.classifiers.functions.LibSVM)”,选择LibSVM分类算法。
在Test Options 面板中选择Cross-Validatioin folds=10,即十折交叉验证。然后点击“start”按钮:
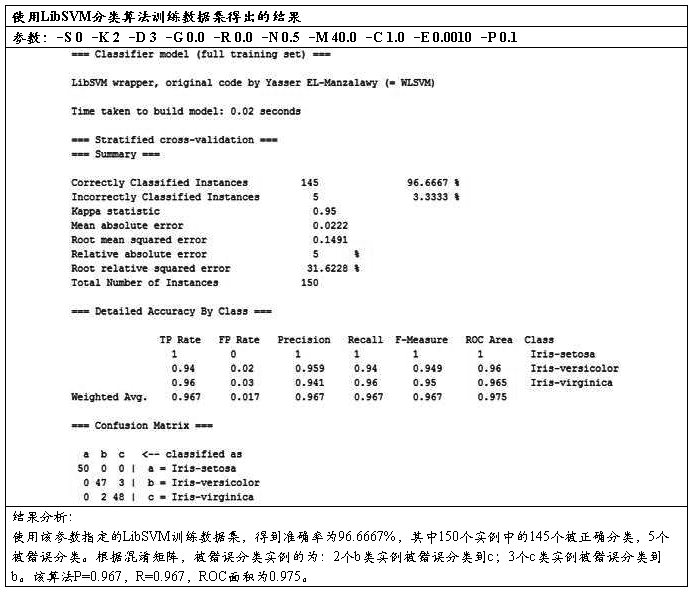
将模型应用于测试集:
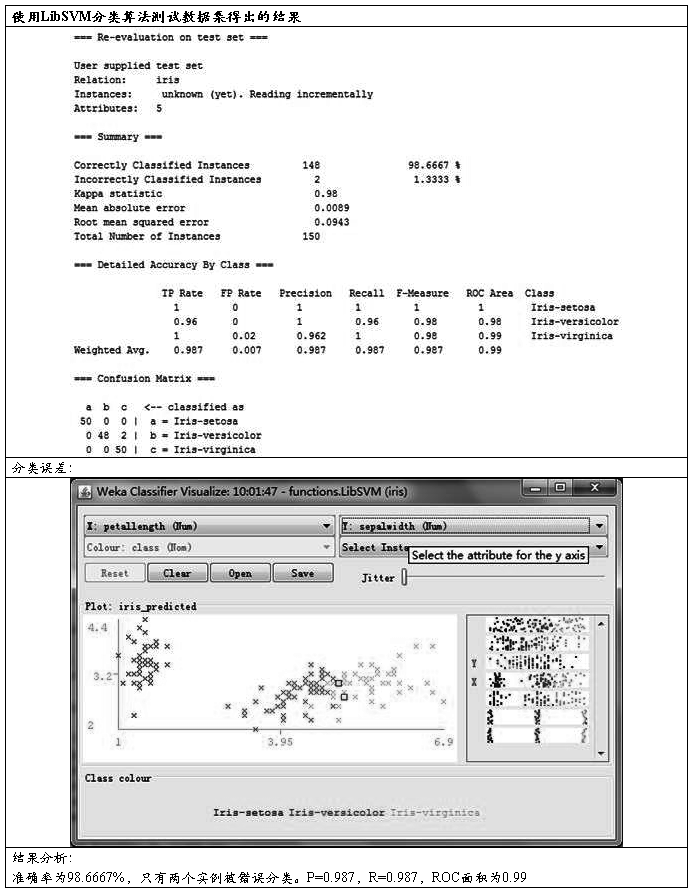
2、C4.5决策树分类器
依然使用十折交叉验证,训练集和测试集相同。

将模型应用于测试集:

3、朴素贝叶斯分类器
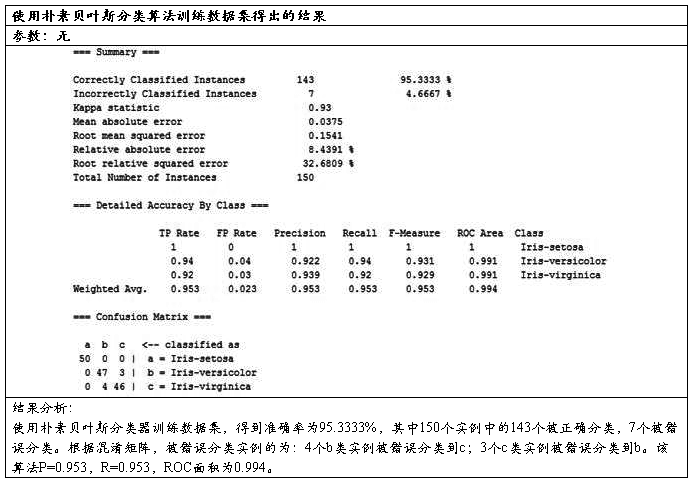
将模型应用于测试集:
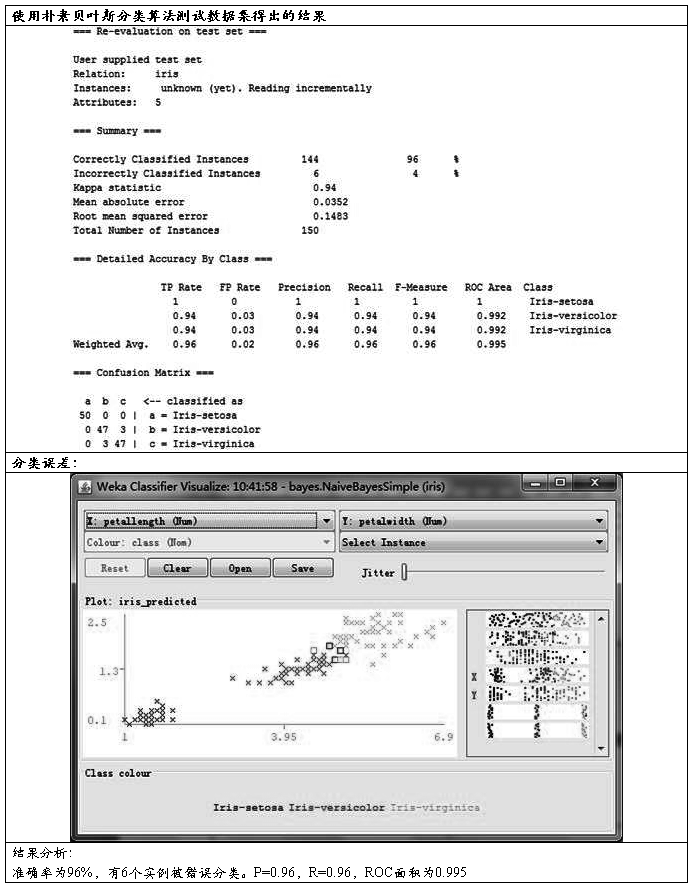
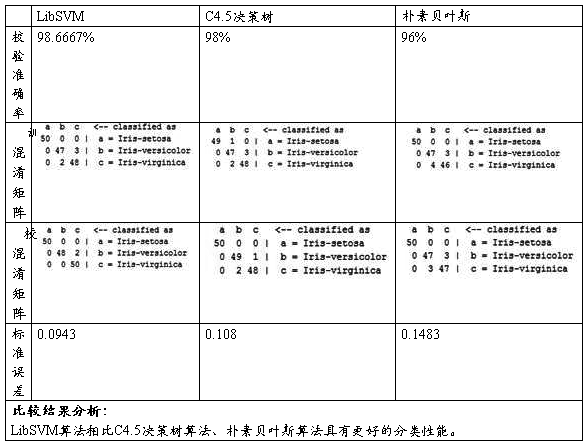
4、三种分类算法比较:
五、实验总结
通过本次实验,我对Weka平台有了比较完整和深入的认识,掌握了使用Weka平台进行数据挖掘的方法,包括数据预处理、分类、聚类、关联分析等。通过实验,对数据挖掘本身也有了比较直观的认识。
第二篇:数据挖掘实验报告 Weka的数据聚类分析
甘肃政法学院
本科生实验报告
(2)
姓名:
学院:计算机科学学院
专业:信息管理与信息系统
班级:
实验课程名称:数据挖掘
实验日期:
指导教师及职称:
实验成绩:
开课时间:20##—2014 学年 一 学期
甘肃政法学院实验管理中心印制

-
数据挖掘WEKA实验报告
数据挖掘WAKA实验报告数据挖掘WAKA实验报告1数据挖掘WAKA实验报告一WEKA软件简介在我所从事的证券行业中存在着海量的信息…
-
《数据挖掘实训》weka实验报告
论文报告案例分析院系信息学院专业统计班级10级统计3班学生姓名李健学号20xx210453任课教师刘洪伟20xx年01月17日课程…
-
数据挖掘weka数据分类实验报告
一实验目的使用数据挖掘中的分类算法对数据集进行分类训练并测试应用不同的分类算法比较他们之间的不同与此同时了解Weka平台的基本功能…
-
weka实验报告
数据挖掘实验报告基于weka的数据分类分析实验报告姓名学号1实验基本内容本实验的基本内容是通过使用weka中的三种常见分类方法朴素…
-
WEKA数据挖掘实验报告
WEKA实验报告一数据集实验采用Wisconsin医学院的WilliamHWolberg博士提供的乳腺癌的数据样本所有数据来自真实…
-
《数据挖掘实训》weka实验报告
论文报告案例分析院系信息学院专业统计班级10级统计3班学生姓名李健学号20xx210453任课教师刘洪伟20xx年01月17日课程…
-
数据挖掘WEKA实验报告
数据挖掘WAKA实验报告数据挖掘WAKA实验报告1数据挖掘WAKA实验报告一WEKA软件简介在我所从事的证券行业中存在着海量的信息…
-
数据挖掘实验报告 Weka的数据聚类分析
甘肃政法学院本科生实验报告2姓名学院计算机科学学院专业信息管理与信息系统班级实验课程名称数据挖掘实验日期指导教师及职称实验成绩开课…
-
weka实验报告
数据挖掘实验报告基于weka的数据分类分析实验报告姓名学号1实验基本内容本实验的基本内容是通过使用weka中的三种常见分类方法朴素…
-
WEKA数据挖掘实验报告
WEKA实验报告一数据集实验采用Wisconsin医学院的WilliamHWolberg博士提供的乳腺癌的数据样本所有数据来自真实…
-
weka实验报告
DWampDM课程实验报告班级信管111姓名陈丽华学号20xx08071131一实验目的验证二实验内容一聚类分析1数据准备1数据文…