java课程设计报告范例
河北科技大学
课程设计报告
学生姓名: 祝冬冬 学 号: 080702102
专业班级: 计算机科学与技术
课程名称: 基于classifier4j的文本分类
学年学期: 2 010 —2 011 学年第 2 学期
指导教师: 许云峰
2 0 1 1 年 6 月
课程设计成绩评定表

目 录 (示例)
一、 设计题目... 1
二、 设计目的... 1
三、 设计原理及方案... 1
1 使用的软件工具和环境... 1
2 需求分析与概要设计... 1
3 数据库设计(无)... 1
4 详细设计和关键问题... 3
四、 实现效果... 3
五、 设计体会... 4
一、 设计题目
基于classifier4j的文本分类
二、 设计目的
进一步巩固Java基础理论和知识,加深Java面向对象特性的理解,锻炼利用开发工具实现Java应用软件的基本技能,提高利用面向对象程序设计方法解决实际问题的能力。并运用课外知识,利用classfiler4j包来实现文本分类,对于给出的文本打分分类。
三、 设计原理及方案
1. 使用的软件工具和环境
MyEclipse、win7系统。
该课程设计以MyEclipse作为开发工具。java作为开发语言,并基于开源程序代码classifier4j。
MyEclipse是企业级工作平台(MyEclipse Enterprise Workbench ,简称MyEclipse)是对Eclipse IDE的扩展,利用它我们可以在数据库和JavaEE的开发、发布,以及应用程序服务器的整合方面极大的提高工作效率。它是功能丰富的JavaEE集成开发,包括了完备的编码、调试、测试和发布功能,完整支持HTML, Struts, JSF, CSS, Javascript, SQL, Hibernate。
在结构上,MyEclipse的特征可以被分为7类:
1. J2EE模型
2. WEB开发工具
3. EJB开发工具
4. 应用程序服务器的连接器
5. J2EE项目部署服务
6. 数据库服务
7. MyEclipse整合帮助
对于以上每一种功能上的类别,在Eclipse中都有相应的功能部件,并通过一系列的插件来实现它们。MyEclipse结构上的这种模块化,可以让我们在不影响其他模块的情况下,对任一模块进行单独的扩展和升级。
简单而言,MyEclipse是Eclipse的插件,也是一款功能强大的J2EE集成开发环境,支持代码编写、配置、测试以及除错。
2. 需求分析与概要设计
本课程设计的目的是利用classifier4j类对文本进行分类,实现文本自动分类。
文本分类一般包括了文本的表达、 分类器的选择与训练、 分类结果的评价与反馈等过程,其中文本的表达又可细分为文本预处理、索引和统计、特征抽取等步骤。文本分类系统的总体功能模块为: (1) 预处理:将原始语料格式化为同一格式,便于后续的统一处理; (2) 索引:将文档分解为基本处理单元,同时降低后续处理的开销; (3) 统计:词频统计,项(单词、概念)与分类的相关概率; (4) 特征抽取:从文档中抽取出反映文档主题的特征; (5) 分类器:分类器的训练; (6) 评价:分类器的测试结果分析。
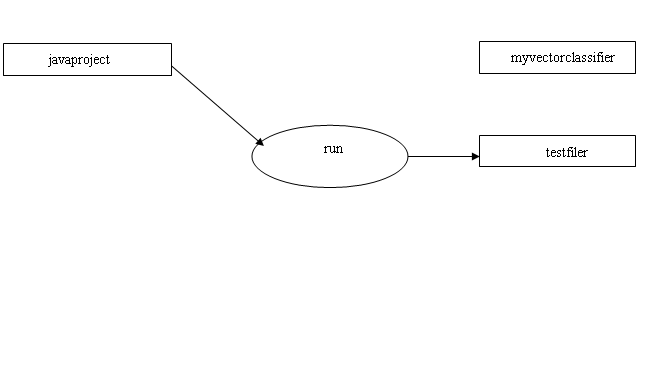
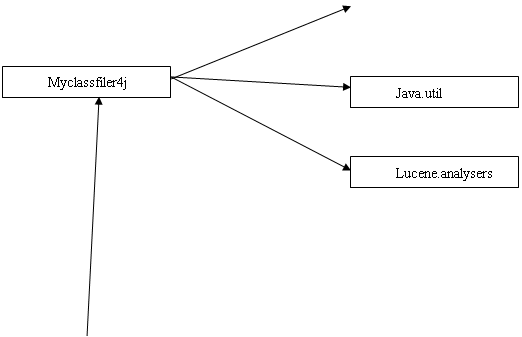
结构图:
class

Package

 Import
Import
Import
Import

图 1
各个包之间的调用如图1所示
3详细设计和关键问题
本课程设计的关键问题是怎样使用java调用各种类包以实现文本分类作用。因此无论是我们现实生活中还是从网络中,有关文本分类的应用程序很广泛。但是java调用各个实用类以及classifier4J的各种JAR包还是有一定难度。因此通过查阅、整合大量资料,我们找到了一些可以实现分类的java类和jar包。同时经过认真的修改,将其改为适合我们使用的java类。而这些类和接口则是实现classifier4J的文本分类调用的关键。通过多次实验和修改,我们已将其改成能够实现对文本类文件进行分类的java接口层和类包。
4实现效果

四.设计体会
通过这几天的java课程设计,基本上达到了预定的目标这次课程设计我做的是章节自测系统,通过这次课程设计,我从中学会了认真思考和不屈不挠的精神,遇到困难要冷静思考,认真分析才能解决问题,基本上掌握了classifier4j的使用和包之间的调用,对于老师上课讲的一些内容,又进行了复习,加强了记忆和了解。
在这次设计过程中,体现出自己单独设计模具的能力以及综合运用知识的能力,体会了学以致用、突出自己劳动成果的喜悦心情,从中发现自己平时学习的不足和薄弱环节,从而加以弥补。程设计是我们专业课程知识综合应用的实践训练,是我们迈向社会,从事职业工作前一个必不少的过程.”千里之行始于足下”,通过这次课程设计,我深深体会到这句千古名言的真正含义.我今天认真的进行课程设计,学会脚踏实地迈开这一步,就是为明天能稳健地在社会大潮中奔跑打下坚实的基础.通过和同学之间的合作,终于把课程设计弄好,我懂得了团队写作的重要性,这对我以后工作有着非常重要的作用。
由于本设计能力有限,在设计过程中难免出现错误,恳请老师们多多指教,我十分乐意接受你们的批评与指正。
附录试验程序
文件1
package myClassfiler4j;
import java.util.HashMap;
import java.util.Map;
import net.sf.classifier4J.vector.TermVector;
import net.sf.classifier4J.vector.TermVectorStorage;
public class MyHashMapTermVectorStorage implements TermVectorStorage {
private Map storage = new HashMap();
public Map getStorage() {
return storage;
}
public void setStorage(Map storage) {
this.storage = storage;
}
/**
* @see net.sf.classifier4J.vector.TermVectorStorage#addTermVector(java.lang.String, net.sf.classifier4J.vector.TermVector)
*/
public void addTermVector(String category, TermVector termVector) {
storage.put(category, termVector);
}
/**
* @see net.sf.classifier4J.vector.TermVectorStorage#getTermVector(java.lang.String)
*/
public TermVector getTermVector(String category) {
return (TermVector) storage.get(category);
}
}
文件2
package myClassfiler4j;
import java.io.IOException;
import java.io.StringReader;
import java.util.ArrayList;
import java.util.List;
import net.sf.classifier4J.ITokenizer;
import org.apache.lucene.analysis.tokenattributes.TermAttribute;
import org.wltea.analyzer.lucene.IKTokenizer;
public class MyTokenizer implements ITokenizer{
private List list;
private String[] strArray;
public String[] tokenize(String input) {
list=new ArrayList<String>();
IKTokenizer tokenizer = new IKTokenizer(new StringReader(input) , true);
try {
while(tokenizer.incrementToken()){
TermAttribute termAtt = (TermAttribute) tokenizer.getAttribute(TermAttribute.class);
// strArray[i]=termAtt.toString();
// String str=termAtt.toString();
// System.out.println(str);
// str=str.substring(str.indexOf("=")+1);
String str=termAtt.term();
// System.out.println(str);
//TODO 优化中文分词
list.add(str);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
strArray=new String[list.size()];
for(int i=0;i<list.size();i++){
strArray[i]=(String) list.get(i);
}
return strArray;
}
}
文件3
package myClassfiler4j;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.Iterator;
import java.util.LinkedHashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.TreeSet;
import net.sf.classifier4J.DefaultStopWordsProvider;
import net.sf.classifier4J.DefaultTokenizer;
import net.sf.classifier4J.IStopWordProvider;
import net.sf.classifier4J.ITokenizer;
public class MyUtilities {
public static Map getWordFrequency(String input) {
return getWordFrequency(input, false);
}
public static Map getWordFrequency(String input, boolean caseSensitive) {
return getWordFrequency(input, caseSensitive, new MyTokenizer(), new DefaultStopWordsProvider());
}
/**
* Get a Map of words and Integer representing the number of each word
*
* @param input The String to get the word frequency of
* @param caseSensitive true if words should be treated as separate if they have different case
* @param tokenizer a junit.framework.TestCase#run()
* @param stopWordsProvider
* @return
*/
public static Map getWordFrequency(String input, boolean caseSensitive, ITokenizer tokenizer, IStopWordProvider stopWordsProvider) {
String convertedInput = input;
if (!caseSensitive) {
convertedInput = input.toLowerCase();
}
// tokenize into an array of words
String[] words = tokenizer.tokenize(convertedInput);
Arrays.sort(words);
String[] uniqueWords = getUniqueWords(words);
Map result = new HashMap();
for (int i = 0; i < uniqueWords.length; i++) {
if (stopWordsProvider == null) {
// no stop word provider, so add all words
result.put(uniqueWords[i], new Integer(countWords(uniqueWords[i], words)));
} else if (isWord(uniqueWords[i]) && !stopWordsProvider.isStopWord(uniqueWords[i])) {
// add only words that are not stop words
result.put(uniqueWords[i], new Integer(countWords(uniqueWords[i], words)));
}
}
return result;
}
private static String[] findWordsWithFrequency(Map wordFrequencies, Integer frequency) {
if (wordFrequencies == null || frequency == null) {
return new String[0];
} else {
List results = new ArrayList();
Iterator it = wordFrequencies.keySet().iterator();
while (it.hasNext()) {
String word = (String) it.next();
if (frequency.equals(wordFrequencies.get(word))) {
results.add(word);
}
}
return (String[]) results.toArray(new String[results.size()]);
}
}
public static Set getMostFrequentWords(int count, Map wordFrequencies) {
Set result = new LinkedHashSet();
Integer max = (Integer) Collections.max(wordFrequencies.values());
int freq = max.intValue();
while (result.size() < count && freq > 0) {
// this is very icky
String words[] = findWordsWithFrequency(wordFrequencies, new Integer(freq));
result.addAll(Arrays.asList(words));
freq--;
}
return result;
}
private static boolean isWord(String word) {
if (word != null && !word.trim().equals("")) {
return true;
} else {
return false;
}
}
/**
* Find all unique words in an array of words
*
* @param input an array of Strings
* @return an array of all unique strings. Order is not guarenteed
*/
public static String[] getUniqueWords(String[] input) {
if (input == null) {
return new String[0];
} else {
Set result = new TreeSet();
for (int i = 0; i < input.length; i++) {
result.add(input[i]);
}
return (String[]) result.toArray(new String[result.size()]);
}
}
/**
* Count how many times a word appears in an array of words
*
* @param word The word to count
* @param words non-null array of words
*/
public static int countWords(String word, String[] words) {
// find the index of one of the items in the array.
// From the JDK docs on binarySearch:
// If the array contains multiple elements equal to the specified object, there is no guarantee which one will be found.
int itemIndex = Arrays.binarySearch(words, word);
// iterate backwards until we find the first match
if (itemIndex > 0) {
while (itemIndex > 0 && words[itemIndex].equals(word)) {
itemIndex--;
}
}
// now itemIndex is one item before the start of the words
int count = 0;
while (itemIndex < words.length && itemIndex >= 0) {
if (words[itemIndex].equals(word)) {
count++;
}
itemIndex++;
if (itemIndex < words.length) {
if (!words[itemIndex].equals(word)) {
break;
}
}
}
return count;
}
/**
*
* @param input a String which may contain many sentences
* @return an array of Strings, each element containing a sentence
*/
public static String[] getSentences(String input) {
if (input == null) {
return new String[0];
} else {
// split on a ".", a "!", a "?" followed by a space or EOL
// return input.split("(\\.|!|\\?)+(\\s|\\z)");
//中文分隔符 regex = “[。?!]+(\\s)*[^”](\\s|\\z)*”
return input.split("[。?!]+(\\s)*[^”](\\s|\\z)*");
}
}
/**
* Given an inputStream, this method returns a String. New lines are
* replaced with " "
*/
public static String getString(InputStream is) throws IOException {
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
String line = "";
StringBuffer stringBuffer = new StringBuffer();
while ((line = reader.readLine()) != null) {
stringBuffer.append(line);
stringBuffer.append(" ");
}
reader.close();
return stringBuffer.toString().trim();
}
}
文件4
package myClassfiler4j;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.StringWriter;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
import net.sf.classifier4J.AbstractCategorizedTrainableClassifier;
import net.sf.classifier4J.ClassifierException;
import net.sf.classifier4J.DefaultStopWordsProvider;
import net.sf.classifier4J.IStopWordProvider;
import net.sf.classifier4J.Utilities;
import net.sf.classifier4J.vector.TermVector;
import net.sf.classifier4J.vector.TermVectorStorage;
import net.sf.classifier4J.vector.VectorUtils;
//import TrainingSample.PropertyGlobal;
/**
* 此类根据VecotrClasifier实现的的。
* @author lemon
*
*/
public class MyVectorClassifier extends AbstractCategorizedTrainableClassifier {
public static double DEFAULT_VECTORCLASSIFIER_CUTOFF = 0.80d;
public static final String MODELPATH="c:/model0";
public static final String MODELNAME="model0.dwl";
public static final int NUM_WORD=100;
private int numTermsInVector = 25;
//将文本切分成单词集合
// private ITokenizer tokenizer;
MyTokenizer tokenizer;
// IKTokenizer tokenizer = new IKTokenizer(new StringReader(t) , false);
// try {
// while(tokenizer.incrementToken()){
// TermAttribute termAtt = tokenizer.getAttribute(TermAttribute.class);
// System.out.println(termAtt.term());
// }
// } catch (IOException e) {
// // Auto-generated catch block
// e.printStackTrace();
// }
//stopword列表
private IStopWordProvider stopWordsProvider;
private TermVectorStorage storage;
public TermVectorStorage getStorage() {
return storage;
}
public void setStorage(TermVectorStorage storage) {
this.storage = storage;
}
private String pathname;
public MyVectorClassifier() {
tokenizer =new MyTokenizer();
stopWordsProvider = new DefaultStopWordsProvider();
storage = new MyHashMapTermVectorStorage();
setMatchCutoff(DEFAULT_VECTORCLASSIFIER_CUTOFF);
}
public MyVectorClassifier(TermVectorStorage storage) {
this();
this.storage=storage;
}
public double classify(String category, String input)
throws ClassifierException {
/**
* //首先由tokenizer将文本input切分成单词集合words,不接收stopword集合中的单词
* //然后通过Utilities的getWordFrequency方法获取单词频率
* // Create a map of the word frequency from the input
* Map wordFrequencies = Utilities.getWordFrequency(input, false, tokenizer, stopWordsProvider);
* //获取欲匹配类别的特征向量 TermVector tv = storage.getTermVector(category);
* if (tv == null) { return 0; } else {
* //按照类别特征向量中的单词获取输入单词集合中的词频
* //如果没有匹配记录,返回0(参见generateTermValuesVector方法)
* int[] inputValues = generateTermValuesVector(tv.getTerms(), wordFrequencies);
* //计算类别特征向量与输入特征向量的cosine距离,作为input对category类的匹配程度
* return VectorUtils.cosineOfVectors(inputValues, tv.getValues()); }
*/
//这个Map存放的是input中词的频率单词
Map wordFrequencies=MyUtilities.getWordFrequency(input);
TermVector tv=storage.getTermVector(category);
if (tv == null) {
return 0;
} else {
int[] inputValues = generateTermValuesVector(tv.getTerms(), wordFrequencies);
return VectorUtils.cosineOfVectors(inputValues, tv.getValues());
}
}
//得到fatherclass的名称
private String filename(String filename){
int start=filename.lastIndexOf("\\");
if(start<=0)
start=filename.lastIndexOf("/");
return filename.substring(start+1);
}
/**
* 读取训练
*/
public void setTrainSet(String pathTrain){
String fatherclass=null;
//得到训练文件所在的位置
File dir=new File(pathTrain);
//得到在训练文件下的所有的文件
File[] files=dir.listFiles();
for(int i=0;i<files.length;i++){
File f=files[i];
if(f.isDirectory()){
System.out.println(f.getAbsolutePath());
fatherclass=filename(f.getAbsolutePath());
System.out.println(fatherclass);
String subTrain=pathTrain+"/"+f.getAbsoluteFile().getName();
//得到子训练文件的文件对象
File File_subTrain=new File(subTrain);
//得到训练文件的文件对象txt文件。
File[] files_txt=File_subTrain.listFiles();
for(int j=0;j<files_txt.length;j++){
String file_txt_path=subTrain+"/"+files_txt[j].getAbsoluteFile().getName();
train(file_txt_path,fatherclass);
}
}
else{ //当不是二级分类时
train(f.toString(),null);
// System.out.println(f.toString());
}
}
setModel(storage,null);
}
/**
* 训练方法,主要负责,训练穿过来的文本,并且加入到Map中,并写入model文件。
* @param filepath
*/
private void train(String filepath,String fatherclass){
// MySummariser ms=new MySummariser();
StringWriter sw=new StringWriter();
File file=new File(filepath);
// String category=filepath.substring(filepath.lastIndexOf("/"),filepath.lastIndexOf("."));
// System.out.println(filepath.lastIndexOf("\\"));
// System.out.println(filepath.lastIndexOf("."));
// System.out.println(filepath);
int start=filepath.lastIndexOf("\\")+1;
if(start<=0)
start=filepath.lastIndexOf("/")+1;
int end=filepath.lastIndexOf(".");
// System.out.println(start+" "+end);
String category=filepath.substring(start,end);
//下面的到分类的父亲类
// String fatherclass=null;
// start=filepath.indexOf("/");
// if(start<=0){
// start=filepath.indexOf("\\");
// }
// if(start>0){
// fatherclass=filepath.substring(start);
// }
//
//
// if(fatherclass.indexOf("/")>0||fatherclass.indexOf("\\")>0){
// fatherclass=
//
// }
String input=null;
try {
FileReader fread=new FileReader(file);
BufferedReader br=new BufferedReader(fread,512);
do{
input=br.readLine();
sw.append(input);
}while(input==null);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
input=new String(sw.toString().getBytes(),"utf-8");
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//上面的代码是读取文件内容,下面代码是提取出现频率最大的词放入到TermVector
// get the frequency of each word in the input
Map wordFrequencies = MyUtilities.getWordFrequency(input);
// now create a set of the X most frequent words
Set mostFrequentWords = MyUtilities.getMostFrequentWords(NUM_WORD, wordFrequencies);
Object[] array=mostFrequentWords.toArray();
// tv=new TermVector(mostFrequentWords.),mostFrequentWords.size());
String[] terms = (String[]) mostFrequentWords.toArray(new String[mostFrequentWords.size()]);
Arrays.sort(terms);
int[] values = generateTermValuesVector(terms, wordFrequencies);
TermVector tv = new TermVector(terms, values);
if(fatherclass==null)
storage.addTermVector(category, tv);
else
storage.addTermVector(fatherclass+"/"+category, tv);
System.out.println(category);
// System.out.println(ms.summarise(input, 3));
}
/**
* 设置类模式,实现的功能的:写入模式到硬盘,其中包括:创建文件,写入文件。
*/
public void setModel(TermVectorStorage tvs,String starinPath){
// public void setModel(String classpath) 原先的定义
// String modelname=null;
// //得到Model路径
// int start=pathModel.indexOf("\\")+1;
// if(start<=0)
// start=pathModel.indexOf("/")+1;
// pathModel=pathModel.substring(start);
//// System.out.println(pathModel);
//
// start=pathModel.indexOf("\\");
// if(start<=0)
// start=pathModel.indexOf("/");
// pathModel=pathModel.substring(start);
//// System.out.println(pathModel);
//
// pathModel="c:/model"+pathModel;
//// System.out.println(pathModel);
//
// int end=pathModel.lastIndexOf("\\");
// if(end<=0)
// end=pathModel.lastIndexOf("/");
//// System.out.println(end);
// modelname=pathModel.substring(end+1);
// pathModel=pathModel.substring(0,end);
//
//
// System.out.println(modelname);
//// System.out.println(pathModel);
//
//
MyHashMapTermVectorStorage myStorage=(MyHashMapTermVectorStorage) tvs;
int size=myStorage.getStorage().size();
Set keySet=myStorage.getStorage().keySet();
Iterator it=keySet.iterator();
String classpath=null;
if(starinPath==null){
classpath=MODELPATH;
}else{
classpath =starinPath;
}
File file_txt=new File(classpath+"/"+MODELNAME);
FileWriter fw=null;
try {
fw=new FileWriter(file_txt);
} catch (IOException e1) {
// TODO Auto-generated catch block
e1.printStackTrace();
}
while(it.hasNext()){
String modelclass=(String) it.next();
File file=new File(classpath);
if(!file.isDirectory()){
System.out.println(file.mkdirs());
}
if(!file_txt.isFile()){
try {
if(file_txt.createNewFile()){
BufferedWriter wb=new BufferedWriter(fw);
wb.newLine();
wb.write(modelclass+"="+myStorage.toString());
wb.close();
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
else{
try {
// fw = new FileWriter(file_txt);
BufferedWriter wb=new BufferedWriter(fw);
wb.append(modelclass+"="+myStorage.getTermVector(modelclass).toString());
wb.newLine();
wb.flush();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
public TermVectorStorage getModel(String modelpath){
TermVector tv=null;
if(modelpath==null){
modelpath=MODELPATH+"/"+MODELNAME;
}
File file=new File(modelpath);
FileReader fread;
try {
fread = new FileReader(file);
BufferedReader br=new BufferedReader(fread,512);
String line=null;
String keyword=null;
String value=null;
do{
line=br.readLine();
if(line==null)
break;
int start=line.indexOf("=");
// System.out.println("start:"+start);
if(start>0)
{
keyword=line.substring(0,start);
line=line.substring(start+1);
List<String> list_String=new ArrayList<String>();
List<Integer> list_Integer=new ArrayList<Integer>();
while(line.indexOf("[")>0){
String key=line.substring(line.indexOf("[")+1,line.indexOf(","));
key=key.trim();
line=line.substring(line.indexOf(",")+1);
String value1=line.substring(0,line.indexOf("]"));
value1=value1.trim();
Integer value_int=new Integer(value1);
list_String.add(key);
list_Integer.add(value_int);
}
String[] array_str=new String[list_String.size()];
for(int i=0;i<list_String.size();i++){
array_str[i]=list_String.get(i);
}
int[] array_int=new int[list_Integer.size()];
for(int i=0;i<list_Integer.size();i++){
array_int[i]=list_Integer.get(i);
}
tv=new TermVector((String[]) array_str,array_int);
storage.addTermVector(keyword, tv);
}
}while(line!=null);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// System.out.println(storage.getTermVector("电气机械及器材制造业").toString());
return storage;
}
public TermVectorStorage getModel(){
return getModel(null);
}
// private void writeFile(String path,String modelname,String key,Map StoreMap){
//
// File file=new File(path);
// if(!file.isFile()){
// System.out.println(file.mkdirs());
// }
// File file_txt=new File(path+"/"+modelname);
// if(!file_txt.isFile()){
// try {
//
// if(file_txt.createNewFile()){
// FileWriter fw=new FileWriter(file_txt);
// BufferedWriter wb=new BufferedWriter(fw);
//
//
// }
// } catch (IOException e) {
// // TODO Auto-generated catch block
// e.printStackTrace();
// }
//
// }
// }
/**
* @see net.sf.classifier4J.ICategorisedClassifier#isMatch(java.lang.String, java.lang.String)
*/
public boolean isMatch(String category, String input) throws ClassifierException {
return (getMatchCutoff() < classify(category, input));
}
/**
* @see net.sf.classifier4J.ITrainable#teachMatch(java.lang.String, java.lang.String)
*/
public void teachMatch(String category, String input) throws ClassifierException {
// Create a map of the word frequency from the input
Map wordFrequencies = Utilities.getWordFrequency(input, false, tokenizer, stopWordsProvider);
// get the numTermsInVector most used words in the input
Set mostFrequentWords = Utilities.getMostFrequentWords(numTermsInVector, wordFrequencies);
String[] terms = (String[]) mostFrequentWords.toArray(new String[mostFrequentWords.size()]);
Arrays.sort(terms);
int[] values = generateTermValuesVector(terms, wordFrequencies);
TermVector tv = new TermVector(terms, values);
storage.addTermVector(category, tv);
return;
}
/**
* @see net.sf.classifier4J.ITrainable#teachNonMatch(java.lang.String, java.lang.String)
*/
public void teachNonMatch(String category, String input) throws ClassifierException {
return; // this is not required for the VectorClassifier
}
/**
* @param terms
* @param wordFrequencies
* @return
*/
protected int[] generateTermValuesVector(String[] terms, Map wordFrequencies) {
int[] result = new int[terms.length];
for (int i = 0; i < terms.length; i++) {
Integer value = (Integer)wordFrequencies.get(terms[i]);
if (value == null) {
result[i] = 0;
} else {
result[i] = value.intValue();
}
}
return result;
}
}
文件5
package run;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
import myClassfiler4j.MyHashMapTermVectorStorage;
import myClassfiler4j.MyVectorClassifier;
import net.sf.classifier4J.ClassifierException;
import org.junit.Test;
public class Testfiler {
@Test
public void test(){
MyVectorClassifier mvcf=new MyVectorClassifier();
mvcf.getModel();
try {
MyHashMapTermVectorStorage mt=(MyHashMapTermVectorStorage)mvcf.getStorage();
HashMap map=(HashMap)mt.getStorage();
Set set=map.keySet();
Iterator it=set.iterator();
// for(mvcf.)
int i=0;
System.out.println(" 分类结果是:");
String s=" 这个疗养院,坐落在以“天下第一汤”而享誉中外的"+
" 昆明安宁温泉,疗养自然条件的优越在国内首屈一指。近"+
" "+
" 老年病学和康复学的医疗队伍。还先后建成了拥有近40"+
"0个床位的门诊、理疗和康复大楼,配备了自动化程度较"+
"高的治疗、疗养和康复的技术设施。国家有关部门最近";
while(it.hasNext()){
// System.out.println(i++);
String classfity=(String)it.next();
System.out.println(" 此文本是"+"“"+classfity+"”"+ "的概率是:"+Math.rint(mvcf.classify(classfity,s)*100)+"%");
}
} catch (ClassifierException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} }}
-
java课程设计报告范例
河北科技大学课程设计报告学生姓名祝冬冬学号专业班级计算机科学与技术课程名称学年学期指导教师2011年6月课程设计成绩评定表目录示例…
-
Java课程设计报告模板
Java程序设计课程设计报告20xx20xx年度第1学期Hannio塔专业学生姓名班级学号指导教师完成日期计算机科学技术网络工程马…
-
Java课程设计报告
安阳工学院计算机学院JAVA课程设计报告蜘蛛纸牌游戏专业班级09级网络工程2班学生姓名李瑞琳学生学号20xx03060016小组成…
-
java课程设计报告
黄淮学院JAVA课程设计报告题目:《日记本的设计与实现》课程设计学院:信息工程学院姓名:学号:专业:软件工程班级:软工1101B班…
-
java课程设计报告书
java程序设计与应用开发Java课程设计报告书题目学籍管理系统班级数媒学号姓名教师20xx年12月24日1java程序设计与应用…
-
shao软件综合课程设计报告1
软件综合课程设计报告题目名称在线员工信息管理班级计0813学生学号20xx25501322学生姓名王绍辉同组学生学号同组学生姓名指…
-
javaEE课程设计报告
课程设计课程名称JAVAEENET课程设计设计题目校园超市商品信息管理系统学院信息工程与自动化学院专业计算机科学与技术年级20xx…
-
javaEE课程设计
桂电编号基于J2EE的开发技术课程设计报告题目桂林市一零八医院导航网站系别计算机科学与工程学院专业信息管理与信息系统学生姓名学号指…
-
JavaEE课程设计任务书new
JavaEE与中间件课程设计任务书辽宁工程技术大学软件学院软件工程系一设计目的JavaEE课程设计是对所学JavaEE与中间件课程…
-
javaee课程设计
一系统设计思想科学技术的飞速发展使计算机应用已经涉及到人们生活的各个方面通过医疗门诊查询系统患者不必到医院去排队只需要一台连接上互…
-
Java课程设计报告模板
Java程序设计课程设计报告20xx20xx年度第1学期Hannio塔专业学生姓名班级学号指导教师完成日期计算机科学技术网络工程马…