数据挖掘实验报告
中科大数据挖掘实验报告
姓名 樊涛声
班级 软设一班
学号 SA15226248
实验一 K邻近算法实验
一实验内容
使用k近邻算法改进约会网站的配对效果。
海伦使用约会网址寻找适合自己的约会对象,约会网站会推荐不 同的人选。她将曾经交往过的的人总结为三种类型:
(1) 不喜欢的人
(2) 魅力一般的人
(3) 极具魅力的人
尽管发现了这些规律,但依然无法将约会网站提供的人归入恰当的分类。
使用KNN算法,更好的帮助她将匹配对 象划分到确切的分类中。
二实验要求
(1) 独立完成kNN实验,基本实现可预测的效果
(2) 实验报告
(3) 开放性:可以自己增加数据或修改算法,实 现更好的分类效果
三实验步骤
(1)数据源说明
实验给出的数据源为datingTestSet.txt,共有4列,每一列的属性分别为:① percentage of time spenting playing vedio games;② frequent flied miles earned per year;③ liters of ice cream consumed per year;④ your attitude towars this people。通过分析数据源中的数据,得到规律,从而判断一个人的前三项属性来得出划分海伦对他的态度。
(2)KNN算法原理
对未知属性的某数据集中的每个点一次执行以下操作
① 计算已知类别数据集中的每一个点和当前点的距离
② 按照距离递增依次排序
③ 选取与当前点距离最小的k个点
④ 确定k个点所在类别的出现频率
⑤ 返回k个点出现频率最高的点作为当前点的分类
(3)KNN算法实现
① 利用python实现构造分类器
首先计算欧式距离然后选取距离最小的K个点
代码如下:
def classify(inMat,dataSet,labels,k):
dataSetSize=dataSet.shape[0]
#KNN的算法核心就是欧式距离的计算,一下三行是计算待分类的点和训练集中的任一点的欧式距离
diffMat=tile(inMat,(dataSetSize,1))-dataSet
sqDiffMat=diffMat**2
distance=sqDiffMat.sum(axis=1)**0.5
#接下来是一些统计工作
sortedDistIndicies=distance.argsort()
classCount={}
for i in range(k):
labelName=labels[sortedDistIndicies[i]]
classCount[labelName]=classCount.get(labelName,0)+1;
sortedClassCount=sorted(classCount.items(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]
② 解析数据
输入文件名,将文件中的数据转化为样本矩阵,方便处理
代码如下:
def file2Mat(testFileName,parammterNumber):
fr=open(testFileName)
lines=fr.readlines()
lineNums=len(lines)
resultMat=zeros((lineNums,parammterNumber))
classLabelVector=[]
for i in range(lineNums):
line=lines[i].strip()
itemMat=line.split('\t')
resultMat[i,:]=itemMat[0:parammterNumber]
classLabelVector.append(itemMat[-1])
fr.close()
return resultMat,classLabelVector;
返回值为前三列属性被写入到resultMat二维数组中,第四列属性作为标签写入到classLableVector中
③ 归一化数据
不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影 响到数据分析的结果,为了消除指标之间的量纲影响,需要进行 数据标准化处理,使各指标处于同一数量级。
处理过程如下:
def autoNorm(dataSet):
minVals=dataSet.min(0)
maxVals=dataSet.max(0)
ranges=maxVals-minVals
normMat=zeros(shape(dataSet))
size=normMat.shape[0]
normMat=dataSet-tile(minVals,(size,1))
normMat=normMat/tile(ranges,(size,1))
return normMat,minVals,ranges
④ 测试数据
在利用KNN算法预测之前,通常只提供已有数据的90%作为训练样本,使用其余的10%数据去测试分类器。注意10%测试数据是随机选择的,采用错误率来检测分类器的性能。错误率太高说明数据源出现问题,此时需要重新考虑数据源的合理性。
def test(trainigSetFileName,testFileName):
trianingMat,classLabel=file2Mat(trainigSetFileName,3)
trianingMat,minVals,ranges=autoNorm(trianingMat)
testMat,testLabel=file2Mat(testFileName,3)
testSize=testMat.shape[0]
errorCount=0.0
for i in range(testSize):
result=classify((testMat[i]-minVals)/ranges,trianingMat,classLabel,3)
if(result!=testLabel[i]):
errorCount+=1.0
errorRate=errorCount/(float)(len(testLabel))
return errorRate;
⑤ 使用KNN算法进行预测
如果第四步中的错误率在课接受范围内,表示可以利用此数据源进行预测。输入前三项属性之后较为准确的预测了分类。
代码如下:
def classifyPerson():
input a person , decide like or not, then update the DB
resultlist = ['not at all','little doses','large doses']
percentTats = float(raw_input('input the person\' percentage of time playing video games:'))
ffMiles = float(raw_input('flier miles in a year:'))
iceCream = float(raw_input('amount of iceCream consumed per year:'))
datingDataMat,datingLabels = file2matrix('datingTestSet.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
normPerson = (array([ffMiles,percentTats,iceCream])-minVals)/ranges
result = classify0(normPerson, normMat, datingLabels, 3)
print 'you will probably like this guy in:' ,result#resultlist[result -1]
#update the datingTestSet
print 'update dating DB'
tmp = '\t'.join([repr(ffMiles),repr(percentTats),repr(iceCream),repr(result)])+'\n'
with open('datingTestSet2.txt','a') as fr:
fr.write(tmp)
四实验结果及分析
本次实验结果截图如下:
在终端输入python KNN.py命令开始执行KNN.py,分别得到了样本测试的错误率以及输入数据后KNN算法的预测结果:
从实验结果来看,本数据集的一共检测的数据有200个,其中预测的和实际不相符的有16个,错误率为8%,在可接受范围之内。由于检测的数据集是随机选取的,因此该数据比较可信。当输入数据分别为900,40,80时,分类结果为didntlike,与数据集中给出的类似数据的分类一致。

实验二 分组实验
一实验内容
本次实验的实验内容为利用数据挖掘的聚类算法实现对DBLP合作者的数据挖掘。DBLP收录了国内外学者发表的绝大多数论文,其收录的论文按照文章类型等分类存储在DBLP.xml文件中。通过聚类算法发现频繁项集就可以很好的发掘出有哪些作者经常在一起发表论文。
二实验要求
(1) 完成对DBLP数据集的采集和预处理,能从中提取出作者以及合作者的姓名
(2) 利用聚类算法完成对合作者的挖掘
(3) 实验报告
三实验步骤
(1)从DBLP数据集中提取作者信息
首先从官网下载DBLP数据集dblp.xml.gz 解压后得到dblp.xml文件。用vim打开dblp.xml发现所有的作者信息分布在以下这些属性中:'article','inproceedings','proceedings','book','incollection','phdthesis','mastersthesis','www'。
在这里使用python自带的xml分析器解析该文件。代码如下:(其核心思想为,分析器在进入上面那些属性中的某一个时,标记flag=1,然后将author属性的内容输出到文件,退出时再标记flag = 0,最后得到authors.txt 文件)
‘’’Getauthor.py
import codecs
from xml.sax import handler, make_parser
paper_tag = ('article','inproceedings','proceedings','book',
'incollection','phdthesis','mastersthesis','www')
class mHandler(handler.ContentHandler):
def __init__(self,result):
self.result = result
self.flag = 0
def startDocument(self):
print 'Document Start'
def endDocument(self):
print 'Document End'
def startElement(self, name, attrs):
if name == 'author':
self.flag = 1
def endElement(self, name):
if name == 'author':
self.result.write(',')
self.flag = 0
if (name in paper_tag) :
self.result.write('\r\n')
def characters(self, chrs):
if self.flag:
self.result.write(chrs)
def parserDblpXml(source,result):
handler = mHandler(result)
parser = make_parser()
parser.setContentHandler(handler)
parser.parse(source)
if __name__ == '__main__':
source = codecs.open('dblp.xml','r','utf-8')
result = codecs.open('authors.txt','w','utf-8')
parserDblpXml(source,result)
result.close()
source.close()
(2)建立索引作者ID
读取步骤1中得到的authors.txt文件,将其中不同的人名按照人名出现的次序编码,存储到文件authors_index.txt中,同时将编码后的合作者列表写入authors_encoded.txt文件。代码如下:
‘’’encoded.py
import codecs
source = codecs.open('authors.txt','r','utf-8')
result = codecs.open('authors_encoded.txt','w','utf-8')
index = codecs.open('authors_index.txt','w','utf-8')
index_dic = {}
name_id = 0
## build an index_dic, key -> authorName value => [id, count]
for line in source:
name_list = line.split(',')
for name in name_list:
if not (name == '\r\n'):
if name in index_dic:
index_dic[name][1] +=1
else:
index_dic[name] = [name_id,1]
index.write(name + u'\r\n')
name_id += 1
result.write(str(index_dic[name][0]) + u',')
result.write('\r\n')
source.close()
result.close()
index.close()
(3)构建FP-Tree并得到频繁项集
FP-Tree算法的原理在这里不展开讲了,其核心思想分为2步,首先扫描数据库得到FP-Tree,然后再从树上递归生成条件模式树并上溯找到频繁项集。代码如下:
def createTree(dataSet, minSup=1): #create FP-tree from dataset but don't mine
freqDic = {}
#go over dataSet twice
for trans in dataSet:#first pass counts frequency of occurance
for item in trans:
freqDic[item] = freqDic.get(item, 0) + dataSet[trans]
headerTable = {k:v for (k,v) in freqDic.iteritems() if v >= minSup}
if len(headerTable) == 0: return None, None #if no items meet min support -->get out
for k in headerTable:
headerTable[k] = [headerTable[k], None] #reformat headerTable to use Node link
#print 'headerTable: ',headerTable
retTree = treeNode('Null Set', 1, None) #create tree
for tranSet, count in dataSet.items(): #go through dataset 2nd time
localD = {}
for item in tranSet: #put transaction items in order
if headerTable.get(item,0):
localD[item] = headerTable[item][0]
if len(localD) > 0:
orderedItems = [v[0] for v in sorted(localD.items(), key=lambda p: p[1], reverse=True)]
updateTree(orderedItems, retTree, headerTable, count)#populate tree with ordered freq itemset
return retTree, headerTable #return tree and header table
def updateTree(items, inTree, headerTable, count):
if items[0] in inTree.children:#check if orderedItems[0] in retTree.children
inTree.children[items[0]].inc(count) #incrament count
else: #add items[0] to inTree.children
inTree.children[items[0]] = treeNode(items[0], count, inTree)
if headerTable[items[0]][1] == None: #update header table
headerTable[items[0]][1] = inTree.children[items[0]]
else:
updateHeader(headerTable[items[0]][1], inTree.children[items[0]])
if len(items) > 1:#call updateTree() with remaining ordered items
updateTree(items[1::], inTree.children[items[0]], headerTable, count)
def updateHeader(nodeToTest, targetNode): #this version does not use recursion
while (nodeToTest.nodeLink != None): #Do not use recursion to traverse a linked list!
nodeToTest = nodeToTest.nodeLink
nodeToTest.nodeLink = targetNode
def mineTree(inTree, headerTable, minSup, preFix, freqItemList):
bigL = [v[0] for v in sorted(headerTable.items(), key=lambda p: p[1])]#(sort header table)
for basePat in bigL: #start from bottom of header table
newFreqSet = preFix.copy()
newFreqSet.add(basePat)
#print 'finalFrequent Item: ',newFreqSet #append to set
if len(newFreqSet) > 1:
freqItemList[frozenset(newFreqSet)] = headerTable[basePat][0]
condPattBases = findPrefixPath(basePat, headerTable[basePat][1])
myCondTree, myHead = createTree(condPattBases, minSup)
#print 'head from conditional tree: ', myHead
if myHead != None: #3. mine cond. FP-tree
#print 'conditional tree for: ',newFreqSet
#myCondTree.disp(1)
mineTree(myCondTree, myHead, minSup, newFreqSet, freqItemList)
四实验结果及分析
在选取频繁度为40后发现,得到的结果非常多,总共2000多,为了分析的方便,进一步提高频繁度阈值为100,此时得到了111条记录,按照合作者的共同支持度排序,部分截图如下:

统计满足支持度条件的合作者个数可以发现,经常一起合作的作者数目最多为3,故在输出文件中输出了authorA,authorB,authorC(当合作者数目为2时,authorC为空,其对应支持度和置信度为0),Sup(A,B,C)为A,B,C共同合作的次数,Sup(A)Sup(B)Sup(C)分别为A,B,C各自的写作次数,Con(A)、Con(B)、Con(C)分别表示A,B,C的置信度(即合作次数除以写作总次数)MinCon和MaxCon分别统计Con(A)、Con(B)、Con(C)的最小值和最大值(注意,当authorC为空时,其对应的置信度不加入最大最小值的统计)。
从结果中可以看出,经常在一起发表论文的大多数是两个人,少数是三个人。合作者之间的关系是双向性的,也就是说,A与B的合作程度与B与A合作的程度是一致的,因此可以直接考虑置信度。如果A和B之间的置信度相差较大有可能存在误差,即A和B合作发表论文对B来说是偶然的对A来说是经常的。
实验三 聚类实验
一实验内容
本实验研究如何评估K-means聚类算法中的最优K值,主要理论依据是《数据挖掘导论》介绍的SSE和Silhouette Coefficient系数的方法评估最优K。
实验步骤概述:
(1) 实现K-means聚类算法
(2) K值优化:
取k值范围,计算出SSE,并绘制出曲线图,观察规律。
取步骤2同样的范围,计算出Silhouette Coefficient,并绘制出曲线图,观察规律。
根据步骤2,3观察的规律,评估出最优K值,验证最优聚类。
(3) 采用K-means++算法,设置同样K值,对比聚类效果
二实验要求
(1) 独立完成聚类实验,基本实现最优聚簇
(2) 实验报告
三实验步骤
(1) Kmeans算法原理
① 从D中随机取k个元素,作为k个簇的各自的中心。
② 分别计算剩下的元素到k个簇中心的相异度,将这些元素分别划归到相异度最低的簇。
③ 根据聚类结果,重新计算K各簇各自的中心,计算方法是取各自簇所有元素各维的平均数
④ 将D中所有元素按照新的中心重新聚类
⑤ 重复第四步,知道结果不再发生变化
⑥ 将结果输出
(2) Kmeans算法实现
首先将要进行分类的数据源预处理,将其中的数据写入到矩阵中,具体代码如下:
def file2matrix(filename):
fr = open(filename)
fr.readline() # Read the first line
lines = fr.readlines()
data = []
for line in lines:
numlist = [int(i) for i in line.split('\t')]
data.append(numlist[1:])
return data
然后,将得到的数据进行Kmeans聚类,代码如下:
def kmeans(data, mincluster, maxcluster):
x = []
ssey = []
scy = []
datarandom = data[:]
fresult = open(resultfile1, 'wb')
for i in range(mincluster, maxcluster + 1):
print "\nk = %d" % i
ssetempold = 0
ssetemp = 0
numgroupold = []
x.append(i)
fresult.write(str(i) + ':\n') # Write to the file
for k in range(0, kcount): #
random.shuffle(datarandom) #
group = []
numgroup = []
for j in range(0, i):
g = []
group.append(g)
g = []
numgroup.append(g)
ssetemp = cal(data, datarandom[0: i], group, numgroup)
if(k == 0):
ssetempold = ssetemp
numgroupold = numgroup
elif(ssetempold > ssetemp):
ssetempold = ssetemp
numgroupold = numgroup
print "-",
# Write to the file
#
count = 0
for groupmember in numgroupold:
count += 1
fresult.write("\n")
fresult.write("-"*500)
fresult.write("\nGroup-%d(%d) " % (count, len(groupmember)))
for num in groupmember:
fresult.write(" %s" % str(num))
fresult.write("\n")
fresult.write("-"*500)
fresult.write("\n")
fresult.write("\n")
ssey.append(ssetempold)
# Calculate silhouette coefficient
for i in range(0, len(numgroupold)):
s = []
for j in range(0, len(numgroupold[i])):
temp = []
for k in range(0, len(numgroupold)):
temp.append(caldistancefromarray(numgroupold[i][j], numgroupold[k]))
a = temp[i] / len(numgroupold[i])
sorted = tile(temp, 1).argsort()
if(sorted[0] == i):
d = 1
else:
d = 0
while(d < len(sorted)):
if(temp[sorted[d]] > 0):
b = temp[sorted[d]] / len(numgroupold[sorted[d]])
break
else:
d += 1
if(d == len(sorted)):
s.append(0)
continue
c = (b-a)/max(a, b)
# print "size1 = %d i = %d j = %d sorted[0]=%d sorted[1]=%d a = %s b = %s c = %s" % (len(numgroup[i]),i, j, sorted[0], sorted[1], str(a), str(b), str(c))
s.append(c)
scy.append(tile(s, 1).sum(axis=0)/len(s))
fresult.close()
plt.subplot(211)
plt.plot(x, ssey)
plt.ylabel('SSE')
# plt.show()
plt.subplot(212)
plt.ylabel('SC')
plt.xlabel('k')
plt.plot(x, scy)
plt.show()
(3)Kmeans++算法原理
k-means++算法选择初始seeds的基本思想就是:初始的聚类中心之间的相互距离要尽可能的远。具体步骤如下:
从输入的数据点集合中随机选择一个点作为第一个聚类中心
对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x)
选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大
重复2和3直到k个聚类中心被选出来
利用这k个初始的聚类中心来运行标准的k-means算法
(4)Kmeans++算法实现
代码如下:
def kmeansplus(data,mincluster,maxcluster):
x = []
ssey = []
scy = []
fresult = open(resultfile2,'wb')
for i in range(mincluster, maxcluster+1):
print "\nk = %d" % i
ssetempold = 0
ssetemp = 0
numgroupold = []
x.append(i)
fresult.write(str(i) + ':\n')
group = []
numgroup = []
masslist = getmasslist(data,i)
for j in range(0, i):
g = []
group.append(g)
g = []
numgroup.append(g)
ssetemp = cal(data, masslist, group, numgroup)
numgroupold = numgroup
count = 0
for groupmember in numgroupold:
count += 1
fresult.write("\n")
fresult.write("-"*500)
fresult.write("\nGroup-%d(%d) " % (count, len(groupmember)))
for num in groupmember:
fresult.write(" %s" % str(num))
fresult.write("\n")
fresult.write("-"*500)
fresult.write("\n")
fresult.write("\n")
ssey.append(ssetemp)
# Calculate silhouette coefficient
for i in range(0, len(numgroupold)):
s = []
for j in range(0, len(numgroupold[i])):
temp = []
for k in range(0, len(numgroupold)):
temp.append(caldistancefromarray(numgroupold[i][j], numgroupold[k]))
a = temp[i] / len(numgroupold[i])
sorted = tile(temp, 1).argsort()
if(sorted[0] == i):
d = 1
else:
d = 0
while(d < len(sorted)):
if(temp[sorted[d]] > 0):
b = temp[sorted[d]] / len(numgroupold[sorted[d]])
break
else:
d += 1
if(d == len(sorted)):
s.append(0)
continue
c = (b-a)/max(a, b)
# print "size1 = %d i = %d j = %d sorted[0]=%d sorted[1]=%d a = %s b = %s c = %s" % (len(numgroup[i]),i, j, sorted[0], sorted[1], str(a), str(b), str(c))
s.append(c)
scy.append(tile(s, 1).sum(axis=0)/len(s))
fresult.close()
plt.subplot(211)
plt.plot(x, ssey)
plt.ylabel('SSE')
# plt.show()
plt.subplot(212)
plt.ylabel('SC')
plt.xlabel('k')
plt.plot(x, scy)
plt.show()
四实验结果及分析
(1)Kmeans算法运行结果如图所示
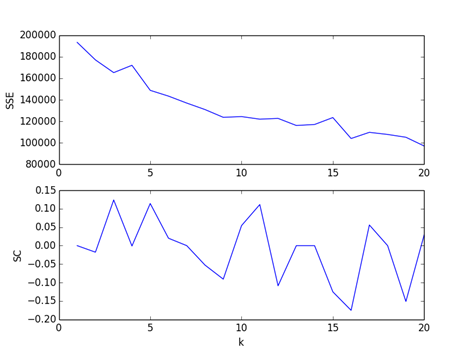
其中的SSE表示簇内的点到其他所有点的平均距离,SC表示轮廓系数,处于-1到1之间,值越大表示聚类效果越好。SC的计算方法是计算簇内一点到簇内其他所有点的平均距离,除以这个点到其他簇的点的最大距离,计算出所有点的平均值即为轮廓系数。大致可以看出当k取3的时候轮廓系数最大,聚类效果最好。
(2)Kmeans++算法运行结果

从图中可以看出聚类效果最明显的是8,与kmenas稍有不同
-
数据挖掘实验报告
数据挖掘实验报告K最临近分类算法学号311062202姓名汪文娟一数据源说明1数据理解选择第二包数据IrisDataSet共有15…
- 数据挖掘实验报告
-
数据挖掘实验报告4
甘肃政法学院本科生实验报告四姓名贾燚学院计算机科学学院专业信息管理与信息系统班级10级信管班实验课程名称数据仓库与数据挖掘实验日期…
-
数据挖掘实验报告
数据挖掘实验报告药物研究专业学号姓名时间20xx1208数据挖掘实验报告药物分析一实验目的1学习数据挖掘的理论知识理解数据挖掘的目…
-
数据挖掘实验报告
计算机科学与技术系数据挖掘实验报告姓名学号授课教师完成时间1数据挖掘实验报告评分2目录1数据挖掘综述411什么是数据挖掘412数据…
-
数据挖掘实验报告
数据挖掘实验报告一实验名称有线电视服务销售CampR树二实验目的1学习和了解数据挖掘的基础知识学会使用SPSSClementine…
-
数据挖掘实验报告4
甘肃政法学院本科生实验报告四姓名贾燚学院计算机科学学院专业信息管理与信息系统班级10级信管班实验课程名称数据仓库与数据挖掘实验日期…
-
《数据挖掘实训》weka实验报告
论文报告案例分析院系信息学院专业统计班级10级统计3班学生姓名李健学号20xx210453任课教师刘洪伟20xx年01月17日课程…
-
数据挖掘实验报告
计算机科学与技术系数据挖掘实验报告姓名学号授课教师完成时间1数据挖掘实验报告评分2目录1数据挖掘综述411什么是数据挖掘412数据…
-
数据挖掘实验报告
数据挖掘实验报告K最临近分类算法学号311062202姓名汪文娟一数据源说明1数据理解选择第二包数据IrisDataSet共有15…