MiniSQL总体设计报告
MiniSQL 总体设计报告
作者:20##级计算机科学与技术专业
XXX ZZZ TTT TTTT CCC
1. 引言
1.1编写目的
为了很好的实现我们的MiniSQL,这里先对系统进行一个总体的分析与层次的设计,以便提高代码的效率与质量。
1.2项目背景
本项目由ZZZ,TTT,XXX,CCC受数据库老师陈根才任命,以课堂大程的形式来独立完成一个MiniSQL的小型系统。
本组开发人员具有数据库应用与实现的知识,并且有较好的C++基础,而且有良好的团队精神。
1.3定义
1.3.1 专门术语
C++:一种面向对象编程语言
SQL:一种访问数据库管理数据库的语言。
1.3.2 缩写
SQL: Structured Query Language(结构化查询语言)。
1.4参考资料
《数据库系统概念》 Abraham Silberschatz
Henry F.Korth
S. Sudarshan
2. 任务概述
2.1目标
设计并实现一个精简型单用户SQL引擎(DBMS)MiniSQL,允许用户通过字符界面输入SQL语句实现表的建立/删除;索引的建立/删除以及表记录的插入/删除/查找。
2.2运行环境
Pentium II或更高 ,Windows NT环境
2.3需求概述
数据类型
只要求支持三种基本数据类型:int,char(n),float,其中char(n)满足 1 <= n <= 255 。
表定义
一个表最多可以定义32个属性,各属性可以指定是否为unique;支持单属性的主键定义。
索引的建立和删除
对于表的主属性自动建立B+树索引,对于声明为unique的属性可以通过SQL语句由用户指定建立/删除B+树索引(因此,所有的B+树索引都是单属性单值的)。
查找记录
可以通过指定用and连接的多个条件进行查询,支持等值查询和区间查询。
插入和删除记录
支持每次一条记录的插入操作;支持每次一条或多条记录的删除操作。
SQL语句需求说明
MiniSQL支持标准的SQL语句格式,每一条SQL语句以分号结尾,一条SQL语句可写在一行或多行。为简化编程,要求所有的关键字都为小写。在以下语句的语法说明中,用黑体显示的部分表示语句中的原始字符串,如create就严格的表示字符串“create”,否则含有特殊的含义,如 表名 并不是表示字符串 “表名”,而是表示表的名称。
创建表语句
该语句的语法如下:
create table 表名 (
列名 类型 ,
列名 类型 ,
列名 类型 ,
primary key ( 列名 )
);
其中类型的说明见第二节“功能需求”。
若该语句执行成功,则输出执行成功信息;若失败,必须告诉用户失败的原因。
示例语句:
create table student (
sno char(8),
sname char(16) unique,
sage int,
sgender char (1),
primary key ( sno )
);
删除表语句
该语句的语法如下:
drop table 表名 ;
若该语句执行成功,则输出执行成功信息;若失败,必须告诉用户失败的原因。
示例语句:
drop table student;
创建索引语句
该语句的语法如下:
create index 索引名 on 表名 ( 列名 );
若该语句执行成功,则输出执行成功信息;若失败,必须告诉用户失败的原因。
示例语句:
create index stunameidx on student ( sname );
删除索引语句
该语句的语法如下:
drop index 索引名 ;
若该语句执行成功,则输出执行成功信息;若失败,必须告诉用户失败的原因。
示例语句:
drop index stunameidx;
选择语句
该语句的语法如下:
select * from 表名 ;
或:
select * from 表名 where 条件 ;
其中“条件”具有以下格式:列 op 值 and 列 op 值 … and 列 op 值。
op是算术比较符:= <> < > <= >=
若该语句执行成功且查询结果不为空,则按行输出查询结果,第一行为属性名,其余每一行表示一条记录;若查询结果为空,则输出信息告诉用户查询结果为空;若失败,必须告诉用户失败的原因。
示例语句:
select * from student;
select * from student where sno = ‘88888888’;
select * from student where sage > 20 and sgender = ‘F’;
插入记录语句
该语句的语法如下:
insert into 表名 values ( 值1 , 值2 , … , 值n );
若该语句执行成功,则输出执行成功信息;若失败,必须告诉用户失败的原因。
示例语句:
insert into student values (‘12345678’,’wy’,22,’M’);
删除记录语句
该语句的语法如下:
delete from 表名 ;
或:
delete from 表名 where 条件 ;
若该语句执行成功,则输出执行成功信息,其中包括删除的记录数;若失败,必须告诉用户失败的原因。
退出MiniSQL系统语句
该语句的语法如下:
quit;
执行SQL脚本文件语句
该语句的语法如下:
execfile 文件名 ;
SQL脚本文件中可以包含任意多条上述8种SQL语句,MiniSQL系统读入该文件,然后按序依次逐条执行脚本中的SQL语句。
在设计中,除了基本的需求之外,我们新增了四条语句:
创建数据库语句
CREATE DATABASE 数据库名;
删除数据库语句
DROP DATABASE 数据库名;
使用数据库语句
USE 数据库名;
显示帮助信息语句
HELP;
其中前三条用于实现数据库的创建,已有数据库的使用,以及删除不需要的数据库;这些将构成对此MiniSQL操作的引导,以及数据库使用结束后,删除不必要的数据库内容的基本命令。HELP命令是为用户提供程序的说明和对MiniSQL操作的指导。
同时对一些语句的功能进行了增强:
1.对于WHERE条件适当地做了扩充。在实验要求中规定WHERE条件具有以下格式:列 op 值 and 列 op 值 … and 列 op 值。其中op是算术比较符:= <> < > <= >=。但在具体实现时,WHERE条件具有以下格式:列 op 值/列 and/or 列 op 值/列….
And/or 列 op 值/列。
2.对于SELECT语句,除了能够选择所有属性以外,还可选择部分属性。如SELECT ATTR1,ATTR2,……,ATTRn FROM 表名。
3. 系统体系结构设计:
在系统的结构设计中,我们主要是按照实验设计指导书中给定的进行设计,各个模块之间的接口会在下面的模块接口设计中进一步阐述,设计结构图完全参照实验指导上的设计结构,如下:
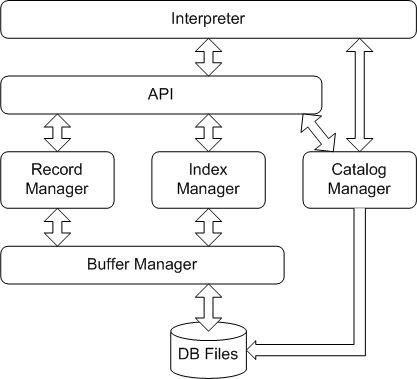
Interpreter 模块的主要功能是接受用户输入的SQL语句及其他命令语句,并检验用户输入的SQL语句及其他命令语句的格式,语法和语义的正确性。同时将符合要求的语句转化为内部形式,供API及Catalog模块使用;而对不符合要求的语句,显示其出错信息,供用户参考。SQL语句的命令解析如下图所示:

API模块是整个系统的核心,其主要功能是根据Interpreter层解释生成的命令内部形式,调用Catalog Manager提供的信息进行进一步的验证及确定执行规则,并调用Record Manager、Index Manager和Catalog Manager提供的相应接口执行各SQL语句及命令语句。
API模块实现功能根据Interpreter层解释生成的命令内部形式的语句编号分别调用Catalog Manager提供的接口进行语句的语义验证,并根据结果调用Record Manager,Index Manager提供的接口执行各语句,同时也为Record Manager 模块调用Index Manager模块的功能提供接口。概而言之,API是Interpreter模块,Record Manager模块及Catalog Manager模块进行沟通的枢纽,三者之间的交互一般都需由API模块来进行转接才能进行相互之间的功能调用。因此,虽然API模块所实现的功能十分有限,但是该模块却是整个系统的核心。
Catalog Manager负责管理数据库的所有模式信息,包括:
1. 数据库中所有表的定义信息,包括表的名称、表中字段(列)数、主键、定义在该表上的索引。
2. 表中每个字段的定义信息,包括字段类型、是否唯一等。
3. 数据库中所有索引的定义,包括所属表、索引建立在那个字段上等。
4. 数据表中的记录条数及空记录串的头记录号。
5. 数据库内已建的表的数目。
Catalog Manager还必需提供访问及操作上述信息的接口,供Interpreter和API模块使用。
为减小模块之间的耦合,Catalog模块采用直接访问磁盘文件的形式,不通过Buffer Manager,Catalog中的数据也不要求分块存储。
数据字典文件格式:  Record Manager负责管理记录表中数据的数据文件。主要功能为实现记录的插入、删除与查找操作,并对外提供相应的接口。其中记录的查找操作要求能够支持不带条件的查找和带条件的查找(包括等值查找、不等值查找和区间查找)。
Record Manager负责管理记录表中数据的数据文件。主要功能为实现记录的插入、删除与查找操作,并对外提供相应的接口。其中记录的查找操作要求能够支持不带条件的查找和带条件的查找(包括等值查找、不等值查找和区间查找)。
数据文件由一个或多个数据块组成,块大小应与缓冲区块大小相同。一个块中包含一条至多条记录,为简单起见,只要求支持定长记录的存储(一个文件中只存储一个表或索引的内容),且不要求支持记录的跨块存储。
Index manager是程序的索引部分,直接对buffer manager提供的内存索引块操作,主要是构建B+树,负责实现record manager这一模块(提供函数接口)所需要的函数。功能有:存储\删除记录的索引,查找记录在table表中的相对位置等(由buffer负责写回磁盘)。
Buffer Manager负责缓冲区的管理,主要功能有:
1. 根据需要,读取指定的数据到系统缓冲区或将缓冲区中的数据写出到文件;
2. 实现缓冲区的替换算法,当缓冲区满时选择合适的页进行替换;
3. 记录缓冲区中各页的状态,如是否被修改过等;
4. 提供缓冲区页的pin功能,及锁定缓冲区的页,不允许替换出去。
为提高磁盘I/O操作的效率,缓冲区与文件系统交互的单位是块,块的大小应为文件系统与磁盘交互单位的整数倍,一般可定为4KB或8KB。
记录管理模块(Record Manager)和索引管理模块(Index Manager)向缓冲区管理申请所要的数据,缓冲区管理器首先在缓冲区中查看数据是否存在,若存在,直接返回,否则,从磁盘中将数据读入缓冲区,然后返回。
最近最少使用(LRU)算法:用一个链表记录所有的缓冲块,每次访问到一个缓冲块就将它插入到链表的头部,这样链表尾的缓冲块就是最近最少使用的块,在需要的时候就可以替换出去。
改进:换出脏块时需要写出块,考虑优质换出非脏块。
4. 接口设计
4.1外部接口
本系统的外部接口为控制台。
使用者通过控制台的字符界面输入查询语句使用MiniSQL。输入方式为键盘输入。
4.2内部接口
本系统内部模块间采用函数调用的方式。具体描述如下。
Catalog Manager为Interpreter提供各种与创建、删除、查询表有关的函数接口,Interpreter调用相应的接口来实现用户的要求。调用时,Catalog Manager利用Record Manager与Index Manager提供的接口来进行实际的对表的读写。其中,Index Manager为Catalog Manager提供与索引创建、删除、插入相关的接口,Record Manager为Catalog Manager提供读写文件的接口。Buffer Manager为Record Manager提供查找文件的接口。
5 出错处理设计
本系统出错主要在两方面,一个是Interpreter的语法分析,另一个是后台程序的异常(比如查询的表不存在)
Interpreter方面,只检查语法错误,若出现错误则重新开始程序,并不关闭程序。
后台方面,错误采用异常的形式由Catalog Manager模块抛出,由Interpreter捕捉,然后反映到主函数里进行处理。处理方法也是重新开始程序而不终止程序。
6 设计分工
本系统的分工如下:
Interpreter模块(含原API)………………………………………………ZZZ
Catalog Manager模块 …………………………………………TTT
Record Manager模块………………………………………………………CCC ZZZ
Index Manager模块……………………………………………………………XXX
Buffer Manager模块…………………………………………………………CCC
总体设计报告…………………………………………………………………ZZZ
测试……………………………………………………………………………ALL
第二篇:第三小组总体设计报告
第三小组总体设计报告:
县级林业管理系统计划标书
一、 编写目的:
森林资源二类调查是以国有林场、自然保护区、森林公园等森林经营单位或县级行政区域为调查单位,以满足森林经营方案、总体设计、林业区划与规划设计需要而进行的森林资源调查,本小组编写的系统是为了满足县级对于森林资源数据及时进行调查、更新,以便于对于建立或更新森林资源档案,制定森林采伐限额,进行林业工程规划设计和森林资源管理,实现对于森林生态效益补偿和森林资源资产化管理,指导和规范森林科学经营。
二、 用户需求分析:
1.本系统的主要用户是县级行政区域,为了满足县级对于森林资源的管理调查需求,可实现其对于森林资源区划、调查、资源统计三部分的要求。具体可以实现小班调绘、专业调查(其中包括了对于野生经济植物调查、湿地资源调查、立地件类型调查和评价、材积表验证)最主要的是可以满足及时更新森林资源的系统数据库,以便于日后对于森林资源做出查询、数据处理、以及数据的输出。
2.系统设计原则:开放性、灵活性、可靠性、安全性、可扩张性、可管理性。
三、 系统功能概述:
1. 实现对于森林资源的数据管理。
2. 对于数据库中的内容进行逻辑查错功能。
3. 对于森林资源数据进行查询统。
4. 关于森林资源的图形管理。
四、 系统功能分析:
森林数据管理:
数据管理分为数据录入、导入导出数据、面积平差、材积表维护、林龄、龄级、林组表维护。
这一系统功能,实现了小班面积自动求积、小班面积与林权颁证面积平差计算、属性数据录入、自动计算各树种的林龄、龄级、林组以及各类资源蓄积等功能。同时,可以利用测量与计算,进行全站仪、GPS、经纬仪、软盘仪等工具,进行测量结果的计算、从而实现图形制作的过程,把技术人员从繁杂的计算和绘图中解脱出来。
逻辑查错功能:
设置新的查错条件,可以根据林业属性字段,定义符合林业规范的逻辑表达式,对林业数据按小班、局域性和全局性三种模式检查,并进行修改功能,从而保证了数据的正确性。
逻辑查错功能在小班卡片录入时亦可进行设置。同时,可以通过小班卡片,查询小班在图上的地理位置,检查区划的合理生性,提高了小班数据的录入精度。
查询统计:
系统查询功能分为点查询、线查询、面查询、高级查询(透视表查询)和统计表查询五种方式,为用户提供林业管理的工具。
各查询具备不同的适用性,可以通过这一系列的查询方式,达到对林业信息的调用与了解。如通过点(GPS定位)查询,可以了解该地方的经纬度(坐标)、资源情况、周边环境情况,从而给护林防火、森林盗伐、森林病虫害等提供了决策依据;利用线查询,可以达到护林防火道路规划、交通公路建设、输电线路架设等给森林资源带来的正面或负面影响,给工程规划、环境评估提供了简便快捷的工具;面查询工具给水库规划、国家基本建设规划等一系统的面域规划所影响的森林资源蓄积和物种提供了简单的查询工具;透视表查询是给最终数据管理人员提供一个查询自建报表的工具,可以进行多行、多列、多条件地统计查询,减少了自建报表的统计环节。同时,所有的查询功能都可图表交互式查询,从而体现了林业管理落实到山头地块的目的。
报表统计功能:
二类资源调查系统集成了二类资源调查报表格式,一旦数据录入完成,即可进行《各类土地面积统计表》、《各类蓄积株数统计表》、《木材林有林地、疏林地面积蓄积统计表》等报表进行统计。
为适应规程规范的需要,本报表模块若不能满足统计需要,用户可以利用透视表工具,结合Excel进行报表自建,方便快速地完成各类统计工作。
图形管理:
包括林相图、基本图两个模板,用户可以利用添加等高线层、小班层、林班层等图层方式,完成林相图、基本图制作。系统定制了林业常用的图例、线型,完全可以满足林业制图的需要,考虑到用户自定义图标,系统提供了图标、线型的制作工具可以方便即时地完成。充分表达了图形所反映的地形地物特征。
用户可以根据自定义图,按照系统提供的图形操作步骤,完成其他林业图式制作。如森林资源现状图,土地资源利用图、坡耕地图等林业专题图。各图层建立的特点与同类软件一样,按分层对图形进行管理。
本系统图形制作是根据DEM数据进行操作,在用户没有DEM数据的前提下,可以利用地形图矢量等高线,形成DEM数据。通过按经纬度(或高斯坐标)进行扫描图图幅定位,然后根据底图进行等高线、河流、道路、地物、标注等图层编辑,从而完成地理信息录入。根据二类资源调查外业规划草图扫描成位图后,从而实现了图纸清绘在计算机内实现。一旦图纸完成、属性数据录入与检查,即可根据林业图式规程范进行林业图形编辑与排版。
系统内置的图框,可以按60×60图幅、也可以按A0至A4的成图模式进行成图。图例、图框、图标等图形编制格式,即是模块化,也可自定义化,从而达到称心如意的绘图效果。
自定义图功能:是给用户提供初始化图纸的工具。
三维分析:三维管理系统是林业GIS信息管理系统的可视化化模块,可以利用GPS、RS、DRS进 行数据处理、分析、查询与展示。
整个系统具备完整的查询、定位工具,用户可以根据DEM数据形成的仿真地理信息,结合卫星图片,进行遥感分析,完成森林资源类型判读,给森林资源分类区划经营提供直观的区划依据。
三维分析中,无论是点、线、面和透视表查询,均可多点、多线、多面进行查询统计,及时地报出规划信息。如水库规划,可以提供水域淹没面积。从而可以计算出水域森林资源消耗等信息。
五、 系统实现方式:
本系统数据处理主要分为几个步骤:
第一、 数据收集、采集阶段,包括人工数据采集以及遥感数据采集。人工数据采集包括人工对于所圈划的样地进行每木检尺,测树高,量胸径等一系列的测量调查活动。遥感数据资源包括遥感的数据图像等。
第二、 数据的处理、分析阶段。包括对属性数据的编辑,输入,空间数据的矢量化等等,并建立数据库,赋予字段,进行相应的存储。
第三、 数据运用阶段,依据数据建立的数据库可以进行林业资源的更新调查。
系统主要的实现方式:主要使用C#、运用数据库,集合ArcGIS软件,设计成一个系统,以便于对于数据进行更新、调查、查询、存储。
六、系统配置设计:
1.CPU为Pentium 133Mhz以上档次的个人计算机
2.操作系统为中文 Win 9x / 2000 / nt / xp 或者更高的版本
3.32MB以上的内存
5. 显示色彩为增强型16位,显示分比率为800 X 600以上(建议1024X768)
6. 鼠标或者其他定点设备
7. EXCEL软件、ArcGIS软件、C#软件
8.多媒体设备(仅供演示程序时使用)
七、数据库设计原则
数据分为空间数据和属性数据:
1.空间数据是用来描述来自于现实的目标,将数据统一化,借以表明空间实体的形状大小以及位置和分布特征。
定位是指在已知的坐标系里空间目标都具有唯一的空间位置;定性是指有关空间目标的自然属性,它伴随着目标的地理位置;
时间是指空间目标是随时间的变化而变化;
空间关系通常一般用拓扑关系表示。空间数据是一种用点、线、面以及实体等基本空间数据结构来表示人们赖以生存的自然世界的数据。 空间数据是数字地球的基础信息,数字地球功能的绝大部分将以空间数据为基础。
2.本系统的空间数据是:地形图矢量等高线、、河流、道路、地物、标注等图层
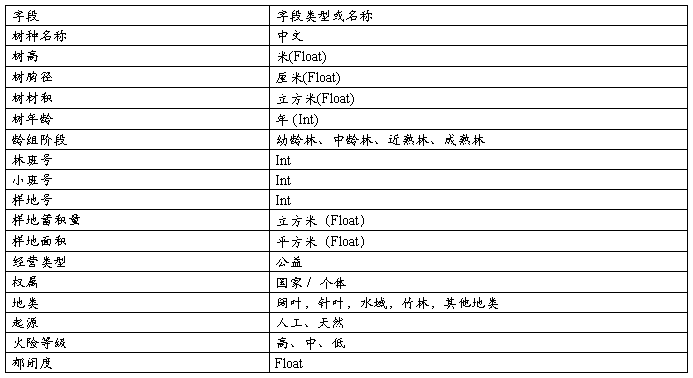
3.本系统的属性数据包括了:森林的林种树名、树高、树胸径、树材积、样地蓄积量、树年龄、道路的名称等(具体的属性字段见下图)
八、系统安全设定

九、系统优势
林业GIS信息管理系统不仅可以是给用户的对林业资源管理的工具,同时也可以为用户创建良好的经济效益和管理效益。总之有如下三个优点:
1、节省经费:首先,节省调查经费:制作一张林相图或林业规划图,过去利用人工制作,大约要7天,而利用GIS,不到1小时。整理内业工作,从勾绘草图、小班求积、清样、标注、描色、数据分析、统计等都可以实现计算机化,与人力相比GIS在总体上可节省5倍的经费。同时,统计各类报表相应的也需要一段过程,从数据整理到统计,也需要十天半月,本系统在用户对属性数据录入完成后,即可进行图表交互式统计。
2、利用已有的林相图、基本图和数据,GIS可以随时制作任何林业专题图,如造林规划图、土地分布图、经营抚育实施图、森林资源分布图等,节省专题图制作费。再次,节省林业规划设计的的内业经费;节省外业调查经费,利用GIS更新后的林相图、制作立体林相图,更有利于外业调查。
3、提高工作效率:提高了内业制图速度、缩短了林业资源数据更新周期;提高各类林业专题调查如天保工程区划、森林资源分类区划、森林资源分类经营的工作效率;提高制作经营决策方案的效率。如此高效的提供林业数据,从而达到了林业决策的适时性。
使林业经营管理更趋科学化:将空间数据作为不可缺少的因素与属性数据进行综合分析,改变单一属性数据分析的缺陷。使制作的决策方案更加合理;对林业森林资源的空间属性数据进行动态管理,一旦资源发生变更,即刻对资源数据进行更新,从而准确掌握资源的状况,做出有效的决策;制作与生长模型、决策模型等有关的专题地图提供形象化的决策分析方案,为经营方案准确有效的实施奠定基础。
-
系统总体设计报告
系统总体设计报告一引言11编写目的本系统为地震灾害预警系统主要用户为政府部门工作人员在地震来临前有效地预测地震在地震发生后尽快高效…
- 软件工程总体设计报告模板
-
系统总体设计报告
项目名称总体概要设计报告机构公开信息项目名称模块设计报告版本历史机构名称20xxPage2of14项目名称模块设计报告目录0文档介…
-
MiniSQL总体设计报告
MiniSQL总体设计报告MiniSQL总体设计报告作者20xx级计算机科学与技术专业XXXZZZTTTTTTTCCC1引言11编…
-
总体设计报告
总体设计说明书项目名称企业标准一级库库存管理系统项目负责人徐文正编写校对审核单位0920xx班第9小组20xx年10月12日系统设…
-
毕业设计开题报告总体安排和进度
总体安排和进度二工作进度安排如下:1.开题论证阶段(3月x日-3月x日)查阅和收集与柔性相关的资料,归纳总结前人在柔性软件研究领域…
-
软件工程设计报告
20xx20xx学年度第2学期赣南师范学院物理与电子信息学院课程设计报告册课程设计名称精品课程网站设计专班级10级01班学号100…
-
系统总体设计报告
系统总体设计报告一引言11编写目的本系统为地震灾害预警系统主要用户为政府部门工作人员在地震来临前有效地预测地震在地震发生后尽快高效…
- 软件工程总体设计报告模板
-
C#学生成绩管理系统课程设计报告
C程序设计课程设计报告2020学年第学期题目学生成绩信息管理系统专业班级姓名学号指导教师成绩年月日目录摘要1第一章绪论211设计目…