关于神经网络的论文读后感
关于神经网络的论文读后感
近期近代数学方法课上老师讲授了一种新的方法叫做神经网络。
神经网络(NNs)全称为人工神经网络(Artificial Neural Networks,简写为ANNs),简称神经网络,也称作连接模型(Connection Model),它是一种模范动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。它是一种大规模并行的非线性动力学系统。
19xx年,心理学家W·Mcculloch和数理逻辑学家W·Pitts在分析、总结神经元基本特性的基础上首先提出神经元的数学模型。此模型沿用至今,并且直接影响着这一领域研究的进展。因而,他们两人可称为人工神经网络研究的先驱。
19xx年冯·诺依曼领导的设计小组试制成功存储程序式电子计算机,标志着电子计算机时代的开始。19xx年,他在研究工作中比较了人脑结构与存储程序式计算机的根本区别,提出了以简单神经元构成的再生自动机网络结构。但是,由于指令存储式计算机技术的发展非常迅速,迫使他放弃了神经网络研究的新途径,继续投身于指令存储式计算机技术的研究,并在此领域作出了巨大贡献。虽然,冯·诺依曼的名字是与普通计算机联系在一起的,但他也是人工神经网络研究的先驱之一。
50年代末,F·Rosenblatt设计制作了“感知机”,它是一种多层的神经网络。这项工作首次把人工神经网络的研究从理论探讨付诸工程实践。当时,世界上许多实验室仿效制作感知机,分别应用于文字识别、声音识别、声纳信号识别以及学习记忆问题的研究。然而,这次人工神经网络的研究高潮未能持续很久,许多人陆续放弃了这方面的研究工作,这是因为当时数字计算机的发展处于全盛时期,许多人误以为数字计算机可以解决人工智能、模式识别、专家系统等方面的一切问题,使感知机的工作得不到重视;其次,当时的电子技术工艺水平比较落后,主要的元件是电子管或晶体管,利用它们制作的神经网络体积庞大,价格昂贵,要制作在规模上与真实的神经网络相似是完全不可能的;另外,在19xx年一本名为《感知机》的著作中指出线性感知机功能是有限的,它不能解决如异感这样的基本问题,而且多层网络还不能找到有效的计算方法,这些论点促使大批研究人员对于人工神经网络的前景失去信心。60年代末期,人工神经网络的研究进入了低潮。
另外,在60年代初期,Widrow提出了自适应线性元件网络,这是一种连续取值的线性加权求和阈值网络。后来,在此基础上发展了非线性多层自适应网络。当时,这些工作虽未标出神经网络的名称,而实际上就是一种人工神经网络模型。
随着人们对感知机兴趣的衰退,神经网络的研究沉寂了相当长的时间。80年代初期,模拟与数字混合的超大规模集成电路制作技术提高到新的水平,完全付诸实用化,此外,数字计算机的发展在若干应用领域遇到困难。这一背景预示,向人工神经网络寻求出路的时机已经成熟。美国的物理学家Hopfield于19xx年和19xx年在美国科学院院刊上发表了两篇关于人工神经网络研究的论文,引起了巨大的反响。人们重新认识到神经网络的威力以及付诸应用的现实性。随即,
一大批学者和研究人员围绕着 Hopfield提出的方法展开了进一步的工作,形成了80年代中期以来人工神经网络的研究热潮。
神经网络的连接形式
1 前向网络. 前向网络通常包括许多层, 常见为三层网络. 这种网络特点是只有前后相邻两层之间神经元相互连接, 各神经元之间没有反馈. 每个神经元可以从前一层接收多个输入, 并只有一个输出送给下一个神经元. 三层前向网络分为输入层、隐层和输出层. 在前向网络中计算功能的节点, 称为计算单元, 而输入节点无计算功能. 常见的是网络BP
2 反馈网络. 从输出层到输入层有反馈, 即每一个节点同时接收外来输入和来自其它节点的反馈输入, 其中也包括神经元输出信号引回到本身输入构成的自环反馈. 这种反馈网络每一个节点都是一个计算单元. 典型是网络Hopfield
3 相互结合型网络. 它属于网状结构. 构成网络中各个神经元都可能相互双向联接, 所有的神经元既作输入, 同时也用于输出. 这种网络对信息处理与前向网络不一样. 在前向网络中, 信息处理是从输入层依次通过中间层 隐层 到输出层, 处理结束. 而在这种网络中, 如果在某一时刻从神经网络外部施加一个输入, 各个神经元相互作用, 直到使网络所有神经元的活性度或输出值, 收敛于某个平均值为止作为信息处理的结束.
4 混合型网络. 上述的前向网络和相互结合型网络分别是典型的层状结构网络和网络结构网络. 介于这两种网络中间的一种联接方式, 在前向网络的同一层间神经元有互联的结构, 称为混合型网络. 这种在同一层内的互联, 目的是为了限制同层内神经元同时兴奋或抑制的神经元数目, 以完成特定的功能。
在网络上,我查阅了相关的文献,一篇关于关于神经网络用于机器人控制的的论文说道:神经网络特别适合于机器人控制, 是由于它具有下述显著特点 :1 由于神经网络可以通过若干实例进行学习, 所以把它用作控制器的时候, 既不需要被控对象的数学模型, 也不需要人们事先为它设计好控制算法.2 因为神经网络具有并行处理信息的能力, 所以它同时能将输入的m 维向量变成输出的n 维向量. 这样, 神经网络可有效地处理视觉、听觉这一类需要复杂计算的感知信息, 从而可能完成实时控制的任务.3 神经网络对外界环境或系统参数的意想不到的变化, 具有很强的自适应性, 因此神经网络控制系统具有大范围的适应能力, 是一般的自适应控制系统所无法比拟的.如:“婴儿”机器人,它安装两只摄像机并具有五个自由度. 众所周知, 婴儿的特点就是爱动, 大一点的婴儿则是看见什么都好奇, 觉得新鲜, 都想把看到的东西抓到手. 起初, 他们看见的东西不一定能够抓得着, 但经过不断地实践, 一旦有一次或几次成功了, 这就是所谓的“无导师学习”. 能不能使现在的机器人也有这种技能呢?现在的工业机器人很难做到, 因为现在的工业机器人要作什么都是由人事先计划好并作一遍才行. 即所谓的“示教——再现”,“示教——再现”是一种有导师的学习.如机器人的支臂、手和各关节的尺寸都准确知道, 即如果运动模型已知的话, 也可以把要作的事情 即任务 按时间顺序写成程序, 计算机根据已知的模型将任务翻译成各个关节的
角度变化加以实现. 这种控制方式的前提是模型必须已知. 可是, 上述的婴儿机器人不需要知道自己的模型, 这样好像与人的本能更接近一些. 人们虽然说不出自己手臂上的每根骨头的尺寸, 但是人们的眼睛和手可以配合得非常默契. 这种机能是靠学习得来的并以某种隐含的形式记在脑皮层的某个区域. 在学习过程中, 这个隐含的内容也不断地更新自己. 人由婴儿长成大人, 骨骼和肌肉的力量一直在发生变化, 脑中那个隐含的内容 知识和经验也不断调整自己. 用自动控制的术语说, 这就是控制系统的自适应性; 应该指出, 现代工业机器人的自适应性还极其有限.“婴儿”机器人的工作过程分为两个阶段: 学习阶段和工作阶段.在学习阶段, 婴儿手里握着一个圆柱体, 在随机位置发生器的作用下, 随机地摆成这个姿势或那个姿势. 在这个过程中, 摄像机将看到的一幅情景信息通过输入变换并进入神经网络, 接着产生目标变换的输出. 这个输出与随机位置产生器产生的实际输出的差值用来调整权变换, 以使看到的和实际做到的不断地趋于一致. 例如, 经过1200 次姿势训练后,“婴儿”机器人就学得很好了. 在工作阶段, 它可以把圆柱体摆在“婴儿”工作空间的任何一个位置和角度上,“婴儿”机器人可以迅速地移动手臂, 并用它的手准确地将圆柱体擒住. 如果改变一下工作环境, 例如将“婴儿”机器人的底坐上垫上点东西,“婴儿”机器人第一次擒获会失败, 但它有能力适应这种工作环境的变化, 不需要重新返回学习阶段就可以调整自己控制网络的权, 并在相继的抓获中取得成功.
实际神经网络的应用研究可以分为以下两大类:
1、神经网络的软件模拟和硬件实现的研究。
2、神经网络在各个领域中应用的研究。这些领域主要包括:模式识别、信号处理、知识工程、专家系统、优化组合、机器人控制等。随着神经网络理论本身以及相关理论、相关技术的不断发展,神经网络的应用定将更加深入。
在看了那些资料以后,我明白了神经网络在应用上是非常广泛的,而以后我应该更加努力地学好它,学会在以后的生活实践中去应用它。
第二篇:神经网络论文定稿
感知机的学习规则
朱婷平
(江西理工大学信息工程学院,江西 赣州 341000)
指导老师:沈慧芳老师
摘 要:每个人是由很多神经元的高度互连的集合帮助完成阅读、呼吸、运动和思考。人的每个神经元都是生物组织和化学物质的有机结合。若不考虑其速度的话,可以说每个神经元都是一个复杂的微处理器。人工神经网络模拟人脑生物神经网络系统处理信息的方式,是通过经验而不是通过设计好的程序进行感知和学习的,这些构成了人工神经网络具有模式识别、预测、评价和优化决策等能力的基础。本文就第一个应用神经网络:感知机及其规则进行了综合论述。
关键词:人工神经网络;感知机;规则
Turbo Code and its Application in 3G Mobile Communication
ZHU Ting-ping
(Information engineering college of Jiangxi University of Science and Technology,Ganzhou,
341000,China) Tutor Shen hui-fang
Abstract:Turbo code has been an important pm-t of the transmit technology of digital baseband, This paper introduces the basic principles and structure of Turbo code and its key technology.Compared the performance of different decode algorithms and stopping criterion of iterative decoding algorithms,Then discussed its application in 3G mobile communication systems.
Key words:The 3G mobile communication;Channel coding;Turbo code;Decode Algorithms
1概述
一般认为,包括记忆在内的所有生物神经功能,都存储在神经元和及其之间的连接上。学习被看做是在神经元之间建立新的连接或对已有的连接进行改造的过程。这便将引出下面一个问题:既然我们已经对生物神经网络有一个基本的认识,那么能否利用一些简单的人工“神经元”构造一个人小系统,然而对其进行训练,从而使他们具有一定有用功能呢?回答是肯定的。我们在这里考虑的神经元不是生物神经元。他们是对生物神经
元极其简单的抽象,可以用程序或硅电路实现。虽然由这些神经元组成的网络能力远远不及人脑的那么强大,但是可对其进行训练,以实现一有用的功能。。20世纪50年代末,人们提出了一种称为感知机的神经网络,他证明了只要求解问题的权值存在,那么其学习规则通常会收敛到正确的网络权值上。整个学习过程简单,而且是自动的。只要把反映网络行为的实例提交给网络,网络就能根据实例从随机初始化的权值和偏置值开始自动地进行学习。然而感知机网络本身却
具有其内在的局限性。对于某些应用问题而言,这种神经网络仍不失为一种快速可靠的求解方法。另外,对感知机网路行为的理解将会理解为更加复杂的神经网络奠定良好基础。因此,这里讨论感知机网络及其联想学习规则是十分必要的。下面首先将对学习规则的概念给出明确的定义,然后解释感知机网络及其学习规则,并讨论感知机网络的局限性。
2 学习规则
所谓学习规则就是修改神经网络的权值和偏置值的方法和过程(也称这种过程是训练算法)。学习规则的目的是为了训练网络来完成某些工作。现在有很多类型的神经网络学习规则。大致可分为有监督学习、无监督学习和增强学习。增强学习与有监督的学习类似,只是它不像有监督的学习一样为每一个输入提供相应的目标输出,而是仅仅给出一个级别。这个级别是对网络在某些输入序列上的性能测度。当前这种类型的学习要比有监督的学习少见。看起来它最为适合控制系统应用领域。无监督学习:在无监督的学习中,仅仅根据网络的输入调整网络的权值和偏置值,它没有目标输出。
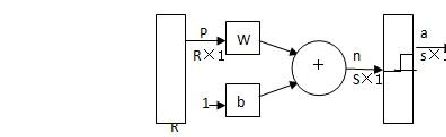
2.1感知机的结构
感知机如下图所示主要由输入部分和硬极限层部分组成。
图1 感知机的结构
感知机网络的输出由下式给出: a = hardlim(Wp + b)
该式在开发感知机的学习规则中十分有用,利用该公式可以方便地引用感知机网络输出中的单个元素。感知机的基本功能是将输入矢量转化为0或1的输出。这一功能可以通过在输入矢量空间里的作图来加以解释。以输入矢量r=2为例,对选定的权值w1、w2和b,可以在以p1和p2分别作为横、纵坐标的输入平面内画出W*P+b=w1 p1+w2 p2+b=0的轨迹。轨迹是一条直线,此直线上及其线以上的所有p1、p2值均使w1 p1+w2 p2+b>0这些点通过由w1、w2和b构成的感知器的输出为1;该直线以下部分的点通过感知器的输出为0.
2.2应用实例
请用感知机学习规则求解如下分类问题。按顺序重复使用各个输入向量,直至最终求得问题的解,并在求出最后一个解后画出问题的图形。
{p1= 2 ,t1=0}{p2=1
3= ?22 ?2 ,t2=1}{p
2 ,t3=0}{p4= ?1
1
,t4=1}请使用
如下的初始权值和偏置值:W(0)=[0 0],b(0)=0 解:
首先利用初始的权值和偏置值计算与第一个输入向量P1相应的感知机输出a:
a = hardlim(W(0)p1 + b(0))
= hardlim([0 0] 2
2 + 0) =
hardlim(0)
和两个校在此处键入公式。验序列进行译码时,应该相互利用校验序列
信道模型子程序、交织子程序、RSC编码子程序、使用不同的算法进行译码的译码子程序等。
影响Turbo码性能的参数很多,本文分别就迭代次数、交织长度、译码算法对Turbo码性能的影响进行分
所含的信息,采用迭代译码,通过分量译码器之间软信息的交换来提高译码性能。结构图如图2所析,给出仿真结果。
(1) 迭代次数
图3给出了不同迭代次数下,Turbo码的误比特率与信噪比的关系曲线,采用MAX-Log-MAP算法,码率为3。
图3 迭代次数对Turbo码的影响
从图3所示的仿真结果可以看出,随着迭代次数的增加,Turbo码的误比特率曲线不断降低并趋于收敛;而且随着信噪比的增加,迭代对误比特率性能的影响越来越明显。这是Turbo码通过迭代译码充分利用冗余信息来提高编译码性能这一特点的反映。最初,迭代译码的增益较高,但随着迭代次数的增加,译码增益增长相对缓
慢,虽然继续增加迭代次数可以提高Turbo码的性能,但权衡迭代所需要的时间、性能改善的幅度,通常都选取合适的迭代次数。
(2) 交织长度
图4给出了不同交织长度下,Turbo码的误比特率与信噪比的关系曲线。

图4 交织长度对Turbo码的影响
从图4中可以看出,交织长度越大,性能就越好,而且交织长度对性能的影响是很大的,这是由于交织器的存在所产生的所谓交织增益,使得Turbo码的性能随交织长度的增长而改善且在交织长度足够长时接近信道容量。交织长度是决定Turbo码性能的一个重要因素。
同时,还应该注意到交织深度和编译码时延之间还存在着一个兼顾的问题。交织长度越长,时延也越大。通信系统中,时延是个很重要的因素,
实时的通信系统中总是对时延提出了较高的要求。在实际的应用中,需要根据时延的要求来确定最佳的码长。
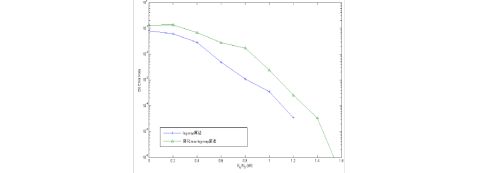
(3) 不同译码算法的性能比较 Turbo码译码算法主要有MAP算法、log-MAP算法和Max-Log-MAP算法和SOVA算法。
从图5中可以看出,Log-MAP算法要优于MAX-Log-MAP算法,所以在应用过程中,要兼顾复杂性与性能,选用合理的算法。
图5 不同译码算法对Turbo码的影响

3小结
Turbo理论的出现是信道编码史上的一个里程碑,它可以相当接近信道容量极限,在高速率数据传递中有着传统信道编码无可比拟的优势,在[2] 刘泉,高路,杨广昕.Turbo码在第三代
移动通信中的应用研究[J].武汉理工大学学报,2002,7:16~19
[3] 于秀兰.Turbo码及其在第三代移动通信
系统中的应用[J].四川通信技术,2000,4:4~8
第三代移动通信系统中具有重要地位,[4] 王晓利,张洪顺.Turbo码技术及其在第
如何简化Turbo码的编码及译码算法以及如何设计商性能的随机交织器,将是今后研究的新热点。
参考文献
[1] 吴伟陵,牛凯.移动通信原理(第二版)
[M].北京:电子工业出版社,2009
三代移动通信中的应用[J].重庆通信学院学报,2005,6:49~51
[5] 汪汉新,尹超.一种改进的LDPC码译码
算法[J].中南民族大学学报(自然科学版),2011,30(4):74~76
[6] 石红.Turbo码在移动通信中的应用[D].
哈尔滨工程大学,2009
-
Sons and Lovers 英文读书报告 读后感 论文(500字以上)
SonsandloversThisnoveliswrittenbyD.H.Lawrence,amansufferedmanysor…
-
读后感论文
读《小学语文教师》有感刘桥乡陈楼中心小学焦方友古人云:“腹有诗书气自华”。书是人一生中不可或缺的一种财富,它不仅给我们提供了精神上…
-
读后感(论文)格式要求
读后感论文格式要求如下1封面页中国古代商业文化结课论文论文题目系院部班级学号姓名日期2正文页题目宋体小4加黑摘要200字以内宋体小…
-
各类读后感的范文
一读可爱的中国有感一路走来我们可爱的母亲中国历经了多少风雨和坎坷走在大街小巷断壁颓垣触目皆是日本帝国主义妄想吞掉中国的一切中国人本…
-
毕业论文写作读后感
我们都知道写一篇好的毕业论文对一个即将毕业的本科毕业生非常重要因为毕业论文写作意味着大学的尾声在读完howtowriteyouru…
-
电子信息工程毕业论文读后感
读后感在读这篇毕业论文之前,我对毕业论文了解的不太多,只知道论文的格式比较严格,内容不能抄袭之类,也听说过写毕业论文是一个比较复杂…
-
Sons and Lovers 英文读书报告 读后感 论文(500字以上)
SonsandloversThisnoveliswrittenbyD.H.Lawrence,amansufferedmanysor…
-
20xx-09-19 议论文,读后感范文(1)
Towriteanargumentativeessayusethefollowingstepstohelpyou1Beginbyintroducing…
-
读后感(论文)格式要求
读后感论文格式要求如下1封面页中国古代商业文化结课论文论文题目系院部班级学号姓名日期2正文页题目宋体小4加黑摘要200字以内宋体小…
-
案例论文的读后感
案例论文的读后感通过对会计研究审计研究管理世界等期刊上一些案例论文的阅读与研读我得到了些许对案例论文写作的启发与思考受益匪浅故从以…
-
科技英语论文写作学习感想
科技英语论文写作学习感想班级:姓名:layhot学号:指导老师:《科技英语论文写作》感想今年是我第一次踏入西安交通大学,以前对她有…