20xx_B_数模美赛读书报告_(河流露营分配)
2012 B 读书报告
--Camping along the Big Long River.
一、自己对问题的理解(初步)
该问题是一种分配最优化的问题,在于如何将旅行时间、持续时间、露营地点、每时刻河流上旅行人次和旅行工具选择进行最合理的安排,合理的标准之一就是能使游客更充分的欣赏风景,即最大化经历,不与其他的旅行队伍碰面;之二就是充分利用 Y 个 campsites。 题目初步读起来难度有一些,不容易分析清楚变量对问题的限制关系以及我们要通过哪些量的输出来达到优化的指标。待我们将题目所给出的条件逐一列出,思路便变得相对清晰,接下来我们要寻找恰当的算法刻画该动态分配过程。
Schedule 要安排到什么程度?是每一条船选择和类型,哪一天发船,每天航行多久,先快还是先慢。。。等,这些度还得把握商榷。
不过我对题目中的 X、Y 两个未定量的参量仍不能很明确,是否我们最终的优化输出中会带有这两个参量,来适应不同的情况?哦,好像 X 是不用考虑的,因为我们还要求解河流的最大承载量。而对于 Y,我估计需要分情况讨论,因为从极限原则来考虑,Y 的大小直接影响了一些限制航行时间的航行类型的停留。
不过我又注意到“In other words, how many more boat trips could be added to the Big Long River’s rafting season?”,这个意思,好像是说要我们在 X 的基础上考虑优化时间安排后能够在加入多少组旅行。
解决该问题,我们最好充分利用控制变量法,将个待分配的变量依次考虑(其他的先做出适合的定量),从而发现个变量对全局的影响。
可能用到“模拟退火算法”,和对于依据概率合理分配资源的算法等,需要我们将个待分配的变量合理的对应上去。
二、论文的思路理解、分析
关于 13074-B-Peking University 的读书报告
关于后两个模型,实用性强,与实际游客的喜好不确定性相符,不过游客的喜好应该能够根据数据库进行提取,猜测会符合一个正态分布,而不一定是左右待选择项的等概率分配的模拟。
该论文优势在于,考虑了游客的自由选择(露营地点,旅行动力)的情况下河流的最大承载量和最优时间表,与实际相符,因为设想如果 agency 设计出了承载量最大的最优的旅行时间表,却因为时间安排让大部分游客觉得不符合自己的意愿而不愿意去旅行,结果只能导致安排是一纸空文,门票一张也卖不出去。这也是我们初步审题所没有想到的。估计我们得到最大承载量结果后,发现旅行类型过于集中或者单一,就能知道这一问题了。当然平均也不一定是适应实际情况的。走了点弯路。
文章算法描述很是周折,在学习过程中,我重点想去抠一下作者算法层面上是怎么实现时间表安排的,尤其是关于所谓的 campsite set 的概念,是否准确,是否符合实际。
1. Introduction
论文在该部分重述了问题的重点,分配 propulsion(动力)和 duration(持续时间)是关键,作者根据这两大关键,将可以航行的类型分为了 26 类。提出了解决大方向:。根据实例研究了旅行者的习惯:白天航行,晚上休息,假设游客在所有可选择的旅行类型中是随即选择,即选每一个的概率相同。根据实际可能的情况,提出或者按照以前每年航 6 个月中的各航行类型比例安排航行时间表,或者根据旅行者随即选择的航行类型的结果安排航行时间表,使减少互相碰面机会并最大程度的提高河流 6 个月中的总体承载量。并且还提出了可以再知道 X 的基础上对模型进行建立。
感觉 introduction 部分写的有条有理,有规范化的模型解法,也有灵活性、应用性较强的模型方法,可供商家参考比较,让人耳目一新。
作者思路清晰,明确问题的限制点和发挥点,把握了安排的时间表要与实际相符(这一点很重要,要不然徒有巨大的河流承载量,确实充分利用了,但安排不合理,游客也不会选择在这里河流旅行)。
对于作者说的,充分利用 campsites 就是不让它闲着,我基本同意,而要尽量增加河流的 6 个月总的承载量,我认为还要确定各个类型的比例到底是多少,因为航行速度快的船增加了流动性,对总承载量起到的权重显然大。如果人们都喜欢航行快的就好了。作者给出的是解决方法,即如模型一,可以改动各个航行类型的分配,我认为这一点较好,可根据实际航行类型受欢迎程度进行改动。
2. Definition
关于一些变量的定义,理解起来尤为重要,要不然我都读不懂作者在干什么,尤其是关于“orbit”的定义,和“campsite sets”的概念,真是在第一个“固定”模型中着实让读者费解一番。
(1) “optimal”:最佳地利用营地,六个月中最大化旅行总数;
(2) “route”:在给定的旅行中,游客选择停留的露营地点;
(3) “orbit”: 允许某一些旅行类型游历的一系列特殊的露营地点;
(4) 给营地自然数编号,从 0 到 Y+1;
(5)给旅行类型自然数编号;
(6) ?? :某旅行类型每天平均航行时间;
(7) ??:每一类型相应的 orbit 中的露营地点数;
(8) ??:六个月中(i 旅行类型)的旅行次数;
3. Specific formulation of problems 做出了营地均匀分布、总开放时间 180
天的基本说明。然后将文章模型大致分为了三部分考虑:第一部分,游客严格按照 river agency 的安排行动;第二部分,我们建立一个随机模型让游客自己随即等概率地挑选露营地点,将小概率事件作为不可能处理,虽然此时他们是可能产生见面冲突的,从而我们优化他们的旅行类型,使见面概率下降;第三部分,游客自己随机选择旅行
动力和露营地点,同样用随机等概率分配进行模拟该过程,优化航行持续时间(duration),选出满足小概率事件的进行排列,得到优化表。
我感觉 model2、3 中随机等概率分配和 model1 中做等比例安排得出的结果貌似没有什么大的区别。应该是算法层面的区别吧,model1 中做出的是简单的规律排列,而 model2、 3 中用到的概率判断和贪婪算法加入引子的方式会显得更加无规律,从算法层次上感觉贴近实际一些。
4. Assumptions
1、 不能返程;
2、 每个露营地只能留一天;
3、 每次持续航行在24h内,每晚要休息,以天为单位度量时间;(每天露营一次吧)
4、 根据查阅,设定游客平均每天旅行8小时;
5、 假设每一种路线安排都是随机等位的。
6、 根据统计学原理,主观设定小概率事件的边界值;
7、 设定Y=150(Y的设定影响模型的修正)经查阅亚马逊相关的河流数据。假设基本合理,恰当的限定了无关的因素,又方便了定量研究河道分配。
5. Part1 Fixed dates, types and routes
充分利用露营地已达到河流的承载量,尽量让露营地处于有人状态。这样就认为我们的承载量能达到最大,充分利用了河流能力,且尽量让船都较快航行,增加动态流动量,文章假设的是不管什么船,在相应的航行天数内,每天最多不超过平均的 8 个小时,即最大跨越度。
该模型对于每一次航行的方式,包括具体细节都安排,也就是省去了游客的主管随机的选择,是一个具体到细节的比较模试化的时间安排model.
首先为每一类型旅行类型安排一特殊系列营地,系列之间没有交集,应用于Y>306的时候;
然后,Y很小时给每组旅行类型们安排一系列特殊营地,一个组包含两个和三个旅行类型的组的情况分别列出;Y很很小,仅仅将所有营地分为两个系列,按照两种航行动力进行分类。总之就是Y小时不足够每一种航行类型都有自己的一个单独的campsite set。
作者通过平均分配的政策进行了列表验证,然后让各种旅行类型占满自己的 campsite set。
并且对于不同参数的 Y 都有相应的策略。
具体来看作者的设计:
对于 a specific campsite set , 变化 trip types,从一个类型到多个类型,对应着对 Y 的减少的适应。 综合各个 campsite sets,就能得出河流的承载量。
文章论述较长,难以一次性通读后还记得作者的概念,文章在 Keywords 部分也做了大概的设计结构的说明。我姑且先把作者的几个逐次递进的小标题列出来:
5.2.1Every campsite set for every single trip type
5.2.2 Every campsiteset for every multiple trip types
5.2.3One campsite set for all trip types 那个图比较重要:
先是对于较大的 Y 值,暂时不考虑各个旅行类型的比例,按照平均分配的原则(在露营地很大的情况下,认为所有船都有充分的露营地可以停留),Y=425,ni=17(但实际上各个 ni 是不相同的,由我们要设定的各个类型的船的比例 mi 来决定,即作者在 divide the campsite sets 部分没有叙述清楚),按照首尾相接的方式,(a campsite set 中的点是固定间隔的排列在河道上的),该类型的船在相应的 campsite set 中以规定天数
按部就班的紧密连续的航行,保证占满这相应的一系列露营地点。直观理解如下:
然后,如果 Y 小于 306 的话,就不能像上面那么简单的考虑了,就不可能同时每一类型的船都在河流上在自己露营地系列(a specific campsite set)里面首尾相连的航行了,要么共用露营地系列
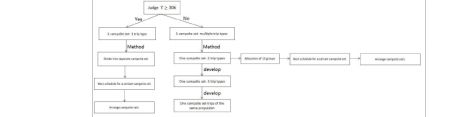
(对于提升承载量没有太大帮助,不过考虑时间表排列
的首和尾,直观的是优先排列航行天数短的)。另一个角度说,Y 过小的话,显然河流的承载能力就要小很多,因为没有船一天能走完,假设每一天是一定要在露营地休息的。因此,保守考虑,要有船可以航行,至少也要 5 个露营地。此时我们的航行方案也就不同了。然后作者就 Y=150 的情况在他的假设上作出了分析,并列出了包含所有旅行类型的航行情况。
模型最终达到的结果,是公司可以利用各种航行动力方式的比例(mi 的比例得到 ni 的比例),从而利用模型得到最优化的航行时间表安排和相应的最大河流承载量。
整理作者的思路和我的看法:
段密度先假设相同(即每一类型都有自己独自相应的 campsite set),然后提出可以受 mi 的改变,列举段密度相同的计算结果求出了河流的最大承载量。
不足之处,我认为作者既然提出可以通过 mi 改变 ni 的可能,来适应实际的情况,那就应该做出这样的结果和验证,而不是一直用段密度平均的政策将 campsites 分为 17 个,貌似所有的分配结果都是以 ni=17 为划分,让读者半天摸不到头脑。另外作者在论述的过程中有不少毛病,例如:我认为的一些错误: ①Qzii ni 中 i 的重复定义; i1
② For every day we let Q trips come into the river to occupy all of the campsites in front
of the leader’s campsiteand they just copy the leader’s route and get to Final Exit the same day with “leader”.;其中个人认为 in front of 用错了,而且当航行类型数较大的时候如果 Y 依旧为 425,则不能一次性让 Q trips 进行最远航行,会与该例子中的环路造成较大偏差;
③ 后来才说 mi 决定 ni,让人产生 ni 恒等于 17 的矛盾?;
④ 关于“Ij-k”,如 “3 M-6s”的说明放错位置了,应该是在model2中的贪婪算法求得
的结果的说明,有些混乱。
⑤ 第四页的“As we can see from the chart below, the distance between two adjacent
campsites in a specific orbit is less than the length of what we call an interval
=(25??225)miles.”没看懂,不应该是相等么?
在实际安排过程中,关于皮划艇的 7 天航行的旅行类型,其中有几天的航行时
间一定超过了 8 个小时,甚至有一天航行 16 个小时以上的,远超出了作者的基本假设,这是一点不足,作者没有说明它是可以适当灵活变动的。而且在开始的 one campsite set for every trip type , 当 Y=425 时,Q 值为[2.41],不会是三,也超出了 8 小时航行。作者列出的以 campsite set 为基础的航行表格,有相当的误差,又不具有可调整能力的代表性。ni 比例真的可以任意调整么?
关于共用露营地系列(即 a campsite set group 包含很多 trip types),作者还应
该提出,是航行天数较为接近的共用效果会更好,因为如果航行天数相差较大,势必航行天数多的相对航行天数少的成为了 leader,会压制航行天数少的向前走,除非两中航行类型时间上聚集并且区别开,而这样又出现了分配时间段过于集中的现象。
而且,这样排列的方案,为了最大承载量,规划好了哪一天你游客要航行多少,必须在一些地点停靠,确实限制了游客的自主选择性,作者也清楚分析了该 part1 的弱点。该模型适用性不是很强,不过对于很抢手的情况,抢手到游客甘愿任何安排只要能买到票,那么就会盈利很大了。优先排列那些航行天数少的旅行方式,会有更大的承载量,体现为河流上的船只更新速度快。
6. Part2 fixed dates and types, but unrestrained routes
考虑让游客自由选择旅行停靠休息的露营地。用随机分配的方法进行游客选择的模拟,认为左右停靠点等概率。当两游客在同一地点重复停靠的概率小于 0.05 当做小概率事件处理,忽略。运用经典的概率学公式,设计 f(T,x,t), P(T,x,t), trip(n), q(x,day.)。
贪心算法的思想我理解的就是:每一步都是最优的,结果也就是最优的。
本模型运用贪婪算法和迭代的方式,逐个加入 trip,每加入的都是对于当前环境最好的选择,即让加入的游客所停靠的露营地不与已经存在的游客航行停靠的露营地重合,是否重合通过以上的 q(x,day)来具体到对应的露营地点和绝对时间(天数)来判断(这样得到的结果一定就是最好的么?哦,是加到不能加为止,贪婪的算法寻找所有可能的,为了最大承载量)。
这其中运用到了 minimum 的原理,即通过调整搜索到的点之间的相互影响,来调整出满足条件的子集最大的调整方案。
最后作者又联系了 X,只要给出了具体的 X 的值和这些 trip 相应的航行类型和情况,就能作为贪婪算法的初始条件,从而在 model 之上继续加 trips 即可达到要优化的结果。我觉得该模型能实现较好的拟合,至于开始选择哪一种航行类型先航行是否会影响整体的分配结果,作者在模型敏感性部分做了验证,说明了 the first trip 对整体承载量的影响是微小的。而贪婪算法的搜索,结合概率公式的计算和 minimum 的调整原理,使得几乎每一天的安排都是满负荷的,这样应该可以说是每天都尽量做到了在随即分配 routes 的情况下的较为充分利用 campsite 的安排,总体也应该是最优化的安排。
继续发挥作者的思路,如果某一天安排不是最优化,那么会不会接下来几天能够最优化的比原方案更好呢?比如作者安排的 180 天中有那么一段时间是连续一周几乎每天都只加入一次航行,如果我在这一周的前两天不安排航行,第三天开始在安排,是不是剩下的五天得到更多的航行的安排呢?因为航行的船是不断往前走的,会留下更多空间,这需要通过算法进行具体的数据验证。因为我考虑到,在 180 天中的中间的部分,每一天地位应该差别不大,那么按照逐天优化,不一定是整体的最优解吧。或许我们可以再对 180 天的安排顺序做调整,该 part6 中只是模拟游客自由选择 route。或者说,贪心算法用在此处,它的优化可信度值得考虑。
运用 Jordan Formula 来进行两游客见面概率 q(x,day.)的求解,是个不错的选择。Jordan Formula 简单来说是 n 个人帽子混合重拍,至少有一组配对正确的概率。不过感觉作者的概率求解公式有一定问题:f (T,Y+1?x,duration)存在么?到了相应类型 T 的持续时间 duration 却还没有到终点 Y+1??
在此 model 的公式说明中说还要用到对应的 campsite set 的概念,那么是如何分的 set 的呢?是不是仍旧受到 Y 的影响,作者也没有明确说明,算法细节之处让人费解,道不明具体实现。
7. Part3 fixed dates, but unrestrained types and routes
同上一个模型,模拟露营地点的自由选择,多考虑的一项是自由选择航行动力,同理将航行动力做等概率随即分布来模拟游客的自由选择。优化保证是同一露营地点相与的概率小于 0.05 视为可忽略的小概率事件。
仍用贪婪算法进行循环处理,Day 每加一,随机挑选可以加入的一个类型加入,进行 Jordan formula 概率计算,随机分配满足条件的露营地,直到该天没有什么类型的船可以加入,则 Day+1,继续上述步骤。
看法和 part6 相同。
8. Sensitivity analysis
通过改变首发船,即贪婪算法的初值,验证 model 的结果----河流承载量无较大变化。实际上在 180 天当中,这些变化本身我认为就是微小的。
改变每天航行最长时间,有一定的代表性。不过作者是否也有很多近似化整计算呢?那样的化貌似与微小的最长时间变化不协调。
改变认定的小概率事件的概率值显然是影响全局的,这是我们优化的主要指标,即是否不同的游客在同一地点见面。
敏感性分析行之有效,因为对于有不确定因素的解决实际问题的 model,我们几乎都要做敏感性分析,看 model 适应环境的稳定性和应对环境变化的反应速度。
9.Strengths and weaknesses
优点:
1、 基本所有营地6个月中每天都被占
2、 限制经过露营地量和为每一种航行方式分配营地的方法有简化作用。
3、 适应不同的Y
4、 允许对所有航行方式不均等分配,与实际相符。
1、 概率模型随即描述游客挑选,
2、 模拟游客兴趣所向的选择露营。 1、游客自由选择营地和交通方式。
缺点:
2、 概率模型模拟游客兴趣所向有失真;
3、 所有提供的旅行不一定等概率的被选择;(也就可能和实际验证结果不很相符)
4、 不同类型旅行数量区别太大在part2和part3里面。
作者很清楚自己 models 的优缺点,思路清晰,缺点在根本上就有,不过这也不失为一种叫可以执行的假设。假设过于严谨,也可能造成我们 model 无法建立,难以权衡各个要设定的变量。
读后小结:
作者给出的模型也没有实质性的时间安排表啊,只有 part6 中给出了一个每天发船的表。因为 X,Y 的不确定,我们似乎也只能这样,方案最重要。
重要的是,我们要控制什么变量,怎样控制的与实际接近,怎样顺序安排的合理达到承载量最大。而且作者还充分考虑了应对不同的 Y 和 X,很全面。
算法层面,我们考虑“模拟退火算法”,和贪心算法结果作比较,不管两者谁得到结果更好,都会使模型总体更加完善。
总体感觉,文章算法层面上描述的比较磕磕绊绊,或许因为我是 Chinese reader,但文章中确实有很多叙述矛盾或者错误,让人难以理解。总体构架比较清晰,摘要和结论写的较好,明确的提出了面对该优化时间表问题,要从几个方面下手,如何与实际更接近,如何考虑 Y 和 X 这两个参量,估计这也是让评委印象深刻的地方。值得我们学习,当模型具体执行出现难度时,我们要保证解题思路准确,对问题的认识和自己要优化哪些东西必须很明确。文章利用到的方法比较多,考虑的关于分配的方式也很多,都值得我一个建模者学习,当我以后遇到类似的分配问题时,估计思路会清晰很多。
关于 13955-B-Western Washington University 的读书报告 文章的叙述让人容易理解,几乎没有废话,目录也几乎将行为思路展现的很完整,让人感觉总体 model 效果很好,这是我们应该学习的论文格式,要在以后注重加强思维轮廓的概括和抽象。
文章的核心算法就是实现“uses priority values to move groups downstream in anorderly manner”,而priority是关于“理论平均位置”(即按照规定航行天数每天应该航行多少的理论位置而又不无休止航行的地点)的滞后还是超前,从而判断接下来是加速前进还是原地停留。每天整体都是前移的,因此每天都连续不断的加入新的航行,逐个占领每一个
campsite。也就充分利用了campsites,文章也是认为尽量占领满campsites能达到最大化的承载量。而且最后还得出了关于安排船类型的比例和持续时间对最大承载量的影响,对实际应用有很大的实用价值。
Abstract
加入限制条件,输出最优时间表,由以上算法过程的分析,结合实际航船的行为特征, 可以得出相应的最大承载量;并应用实际的一个旅行河段的案例来进行了模型输出的实用性。最后通过改变 propulsion、duration 和 Y 来验证模型的敏感性。
我认为摘要基本描述了自己对问题的认识,但为说明限制条件就是减少游客在同一露营地点的碰面,信息量不是很大,也比较含糊,都是一些一语带过的描述。不过也算是循序渐进,不至于让读者产生思维的矛盾。
1 Introduction
1.1 Defining the Problem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Model Overview . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.3 Constraints . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.4 Assumptions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
1.5 Variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
单从 introduction 列表来看,已经将解题准备工作明确,分别列出,层次鲜明,容易让 读者掌握,我们应该学习。
“our model is easily adaptable to find optimal trip schedules for rivers of varying length,
numbers of campsites, trip durations, and boat propulsions.”作者很清楚模型要分析什么变量, 在该部分体现的很好,正确理解了题目的意义,并且找到了合理的解决方向,体现了论文赢在了开头。
问题解释,进一步接近model要处理的因素。说明了model解决的问题:河流承载量关
于营地分布、动力选择、每一天发出多少组航行和如何安排航行时间的关系,从而最优化了河流承载量。列出了已知条件。基本假设重要的有:
? 由我们决定两种航行动力的比例,“为了承载量最大,不能设置过多的oar-power 且航行距离短的”;
? 充分考虑输入的变量,为了让结果更有意义,令oar-power航行12至18天,令 motorized-power航行6至12天;
? 每天必须往前走,只能停留一次,不能返程;
? 只能白天航行,最多10个小时;
? 忽略天气因素;
? Campsite均匀等间隔分布;
? 必须在规定的最后一天到达end。
2 Methods
我理解的算法设置了四个有效概念:Open Campsite; Moving to an open campsite; Waitlist; Off the River. 特别是优先级的概念,即通过与理论的平均航行位置比较,得到当前该船只的相应的优先等级,较落后的(behind schedule)优先等级就比较高,较超前的(ahead schedule)优先等级就比较低,从而进行航行快慢的调整补充。具体做法是从最后(C_final)往起点(C_0)算起,有开放的营地就判断有能力到达它(每天航行不超过 10h)的优先级高的航行到此处,在一次往下考虑“开放营地”,直到起点(C_0),(等待的 C_0 处的船也加以考虑)从而完成一天的航行。
总体原则就是向着理论平均航行位置进行靠近,一个挨一个的排列,充分利用每一个 campsite。
疑问是该模型初始条件是如何设置的呢?没有明确说明。我理解应该可以认为设定候选梯队的 groups 数量,然后按照优先级排列即可。
3 Scheduling Simulation
设定起始点等待 groups 的数量,设定 Y 值,得到四条船的时间安排表。不过我觉得应该给出连续的 campsites 的占领情况,而不只是开始的四条船的航行情况,因为我们要知晓连续的数据。
而且,貌似作者没有给出解决如每天发送如 k 跳船和这 k 跳船在左右可能的 26 中航行类型的根据优先级挑选的情况。
4 Case Study
很精彩该部分,因为作者给出了最大承载量和 Y 和 R(露营地数和航行动力比率)、D 和 R(持续天数比率和航行动力比率),能使 agency 充分了解到该紧密安排模型对于以上参量组合的敏感性,也就是说,我们能够知道根据客观条件(如 Y 数和我们的时间安排算法)计
算得到最优化的 R 和 D 的值的分布情况,从而安排船的种类(以 duration 和 propulsion 分类)的比例。
不过这样时间表安排得到的最优化结果有最大的承载量,相应的 R 和 D 是不是实际当中游客所能接受的,还有待明确,优化满足游客的兴趣所向也是以一种适应实际的适应性。或者得到实际的 R 和 D,agency 能够得到时间安排表的最大承载量与理想的差距,从而在作 出适当调整。
5 Discussion & Conclusion
结论简明扼要,说出了再给定 X(已存在 trips 数的情况下),我们可以加入 3000-X(我理解这 X 次航行是可以改变当前他们的航行时间表的,加入到总体中重新考虑)。这只是一个简单概念的问题。而且模型关于第 4 部分的发挥,即 M 和 R、D 和 Y 的关系,也是 agency 可以灵活利用 model 分析实际问题的一个行之有效的手段。
6 Limitations and Error Analysis
关于第一点,说我们的算法可能超负荷安排,理由是可能导致拥挤和环境破坏,这一点我不认同。这是现象,不是阻碍 model 建立的因素,我们只是从增加游客旅行数量的角度考虑如何安排航行时间表,而那些角度是目的的阻力,在模型建立中不应考虑。
还有考虑河流流速?这样的话貌似因素就多了,或者说我们应该把河流流速考虑到两种动力的船的航行速度里边吧直接。
而作者应该考虑的缺点(我认为的)却忽略了一点,就是我在第 4 部分中提到的,如果为了单纯的承载量最大化而造成了动力和持续时间安排过于极端化,也是不适用的。不过作者给出的研究例子还好,都是比较中等的分配。
论文小结:
这篇论文我感觉是不错的文章,模型简答明了,叙述清晰,结构严谨全面,有考虑 agency 应用时权衡各个变量的过程。
对问题理解准确,利用实例进行验证,并且每一部分都有图例说明,让读者容易理解。三、总结与感受
总体感觉,该题目说复杂也不复杂,说简单要综合的变量和因素还比较多,而且恰当的算法应用至关重要。
每一篇优秀文章开始,首先都赢在了对论文的准确理解上,要解决什么问题,处理哪些变量,如何处理体现优化的特性,要得到什么结果,结果如何验证以及在实际当中如何应用该 model。
每读一篇论文,加上之间的相互比较,就又有更清晰的对问题的认识和更深的对算法的理解,感触很深。
这是一类分配要素的题目,或者说是在排列多变量的题目。设计了排列的思想,逐步加入因子的思想,动态流程的思想,以及很多相关的算法。很多值得借鉴的内容。接下来我们打算研究相关的一些算法,和动态规划的模型。
-
数学建模课程读书报告
NANCHANGUNIVERSITY数学建模课程读书报告题目:浅数学建模读书收获学院:理学院专业:信息与计算科学111班姓名、学号…
-
数学建模课程读书报告
NANCHANGUNIVERSITY数学建模课程读书报告题目学院专业姓名学号任课教师时间1格式要求一摘要1中文摘要标题小二号宋体加…
-
数学建模文化_读书报告论文
数学与文化之读书报告安徽理工大学大10级英才班电气工程学院摘要全书分三章写了数学的发展对人类文化产生的持续影响用诸多的事例说明了数…
-
数学建模课程读书报告
论数学建模中创造性思维的心理机制和培养摘要创造性思维是一切创新活动的基础和核心是各种思维中最为积极也最有价值的思维形式在数学建模中…
-
数学建模课程读书报告
NANCHANGUNIVERSITY数学建模课程读书报告题目数学的奥妙读书报告学院理学院专业姓名学号任课教师时间120xx年5月1…
-
数学建模读书笔记
数学建模是通过对实际问题进行抽象、简化,反复探索,构件一个能够刻划客观原形的本质特征的数学模型,并用来分析、研究和解决实际问题的一…
-
大学生社会实践报告模板__数学建模培训心得体会
暑假社会实践论文题目数学建模培训心得体会姓名所在学院专业班级学号日期20年月日摘要社会实践是大学生将所学知识运用到生活实际的重要环…
-
数学建模报告论文(1)
20##届校内数学建模报告论文题目名称:低碳环境下城市经济发展的评估及考量论文作者:xxx所属学院:财会金融学院浙江经济职业技术学…
-
数学建模报告
数学建模实验班级:计算机24姓名:XXX学号:XXX儿童受教育水平问题一、问题描述社会学的某些调查结果表明儿童受教育的水平依赖于他…
-
暑假数学建模社会实践报告
20xx年暑假数学建模社会实践报告学校云南师范大学学院物电姓名许旭冉学号114090048一眨眼功夫我们的大学生活就过去了三分之一…