数据分析实验报告
数据分析课程实验报告
学 院:理学院
专 业:信息与计算科学
班 级:
姓 名:
学 号:
一、实验题目
所做实验属于哪一部分的内容。例如:一元线形回归及其在SPSS中的实现。
二、实验目的
1、加深对聚类分析原理的理解;
2、理解聚类分析中变量聚类的原理;
3、运用SPASS软件解决关于聚类分析方面具体的问题;
三、实验原理
聚类分析也称群分析、点群分析,他是研究分类的一种多元统计方法。 例如,我们可以根据学校的师资、设备、学生的情况,将大学分成一流大学,二流大学等;国家之间根据其发展水平可以划分为发达国家、发展中国家;自然界生物可以分为动物和植物等等。这些就是一些分类。
那么分类根据什么分呢?
聚类分析的基本思想是在样品之间定义距离,在样品之间定义相似系数,距离或相似系数代表样品或者变量之间的相似程度。按相似程度的大小,将样品(或变量)逐一归类,关系密切的类聚集到一个小的分类单位,然后逐步扩大,使得关系疏远的聚合到一个大的分类单位,直到所有的样品(或变量)都聚集完毕,形成一个表示亲疏关系的谱系图,依次按照某些要求对样品(或变量)进行分类。根据分类对象不同分为样品聚类和变量聚类,样品聚类在统计学中又称为  型聚类,它是根据被观测的对象的各种特征即反映被观测对象的特征的各变量值进行分类;变量聚类在统计学中有称为
型聚类,它是根据被观测的对象的各种特征即反映被观测对象的特征的各变量值进行分类;变量聚类在统计学中有称为 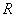 型聚类,它反映事物特点的变量有很多,我们往往根据所研究的问题选择部分变量对事物的某一方面进行研究。依据聚类方式的不同我们可以有很多种聚类如:快速聚类法,谱系聚类法等等。
型聚类,它反映事物特点的变量有很多,我们往往根据所研究的问题选择部分变量对事物的某一方面进行研究。依据聚类方式的不同我们可以有很多种聚类如:快速聚类法,谱系聚类法等等。
型聚类分析的主要作用是:
1、不但可以了解个别变量之间的关系的亲疏程度,而且可以了解各个变量组合之间的亲疏程度。
2、根据变量的分类结果以及它们之间的关系,可以选择主要变量进行回归分析或型聚类分析。
型聚类分析的优点是:
1、可以综合利用多个变量的信息对样本进行分类;
2、分类结果是直观的,聚类谱系图非常清楚地表现其数值分类结果;
3、聚类分析所得到的结果比传统分类方法更细致、全面、合理。
变量聚类的基本原理
变量聚类在实际中也是广泛应用,一方面,通过变量聚类可以发现某些变量之间的一些共性,以有利于分析问题和解决问题;另一方面,变量聚类也可作为某些数据分析的中间过程,例如,在回归分析中,若涉及的自编来那个很多,则可以先考虑用变量聚类,再在每一类变量中进行主成分分析,选取各类中的某些主成分作为新的自变量,这样不但可以消除变量间的复共线性,而且也可以达到降低自变量维数的目的。
设对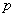 个变量
个变量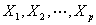 个观测了
个观测了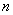 次,得到的观测数据向量为变量的观测向量
次,得到的观测数据向量为变量的观测向量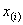 与
与 间的相似性可以用相似系数度量。设
间的相似性可以用相似系数度量。设

 则与的相似系数是
则与的相似系数是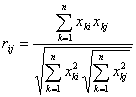 显见,
显见, 若将与看作维空间向量,则
若将与看作维空间向量,则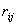 是它们的夹角余弦。变量观测向量
是它们的夹角余弦。变量观测向量 两两间的相似系数构成相似系数矩阵
两两间的相似系数构成相似系数矩阵 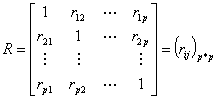
显然,对于标准化数据,即原观察数据的相关系数矩阵,这时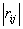 的大小反应了两个变量
的大小反应了两个变量 与
与 线性关系的强弱。
线性关系的强弱。
从出发,关于变量的谱系聚类过程与从距离矩阵出发,关于样品的谱系聚类过程类似,只是由于越大,表明与越相似,因此,每次应选取相似矩阵或更新的相似矩阵中主对角线以外的最大元素所对应的两个变量或两个类合并。类与类之间的相似性度量可类似于前述的定义。需要指出的是,在 系统的
系统的
 过程中,总是从不相似度量的距离矩阵出发进行巨雷,因此看,若利用此过程对变量聚类,应先将相似矩阵变化为不相似度量的距离矩阵
过程中,总是从不相似度量的距离矩阵出发进行巨雷,因此看,若利用此过程对变量聚类,应先将相似矩阵变化为不相似度量的距离矩阵 ,再从出
,再从出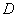 发,按照样品的谱系聚类法对变量角力。通常的变换有
发,按照样品的谱系聚类法对变量角力。通常的变换有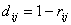 或
或 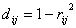 ,
, 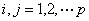 若为相关系数矩阵,且我们一变量的线性关系强弱作为相似性的度量,这时可令
若为相关系数矩阵,且我们一变量的线性关系强弱作为相似性的度量,这时可令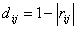 .
.
样品间的距离
1、距离定义:设满足下面的三个条件
(1)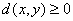 且
且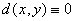 当且仅当
当且仅当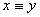 时;
时;
(2)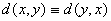 ;
;
(3)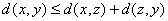 ;
;
距离定义有很多种,常见的有:
(1)欧氏距离(Euclidean distance)
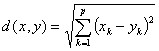
(2)绝对距离(Block距离)
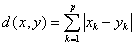
(3)切比雪夫距离(Chebychev)
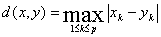
2、我们主要用到快速聚类,因此我们讲述一下快速聚类的步骤:
(1)选择聚点,得到初始聚点的集合,可以假定聚类中采用距离是欧氏距离,即上面的式子。
(2)按照如果某一个点到该聚点的距离比到其他聚点的距离小,就把该点分为该聚点的类的原则,实现对所有点的初始划分,得到初始类:
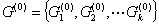
(3)从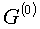 出发,计算新的聚点集合
出发,计算新的聚点集合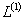 以
以 的重心为新的聚点
的重心为新的聚点

其中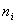 是类中的样品数,这样得到新的聚点集合:
是类中的样品数,这样得到新的聚点集合:
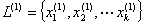
从出发,将样品进行新的分类。记
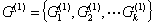
这样依次计算下去
(4)设在第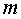 步得到分类
步得到分类
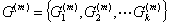
在以上的递推过程中,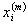 是类
是类 的重心,但是其不一定是样品,又一般不是下一聚类的重心,但是当逐渐增大时,分类趋于稳定此时有就会近似为
的重心,但是其不一定是样品,又一般不是下一聚类的重心,但是当逐渐增大时,分类趋于稳定此时有就会近似为 的重心,从而
的重心,从而 ,
,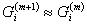 ,算法即可结束,实际计算时候若相邻的两次迭代使得分类相同,则计算即告结束。
,算法即可结束,实际计算时候若相邻的两次迭代使得分类相同,则计算即告结束。
一般情况下,我们也可以设置收敛准则为当聚点改变的最大距离小于或等于初始聚点之间的最小距离乘以给定的某个数值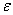 时,计算过程结束。
时,计算过程结束。
四、实验内容
例题.
我们以20##年31个省,市,自治区的城镇居民月平均消费支出数据为例,在spss中利用K-均值法对31个省市自治区的城镇居民消费水平进行聚类分析。
城镇居民消费水平通常用表9.13中的八项指标来描述,八项指标间存在一定的线性相关。为研究城镇居民的消费结构,需将相关性强的指标归并到一起,这实际就是对指标聚类。原始数据列于表9.13。
表9.13 2005年31个省、市、自治区城镇居民月平均消费数据
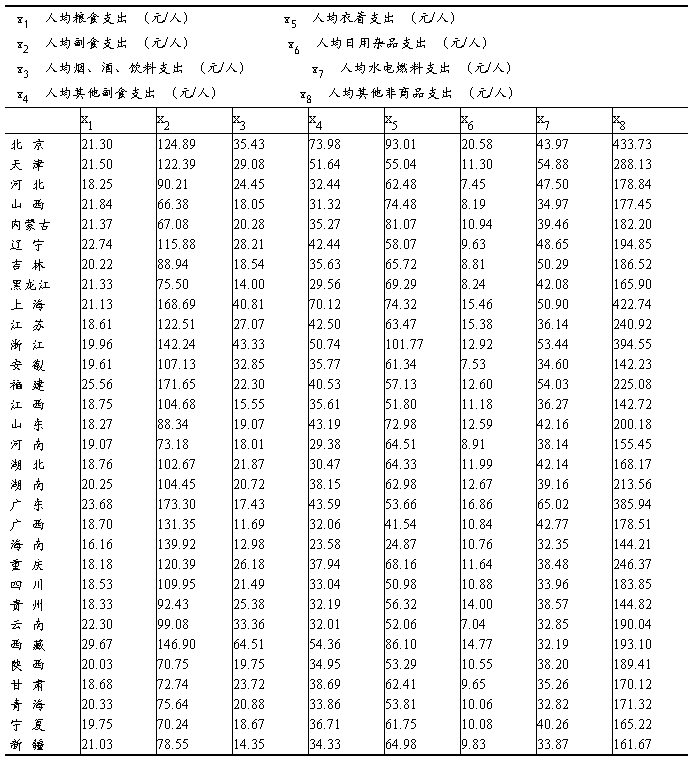
五、实验步骤
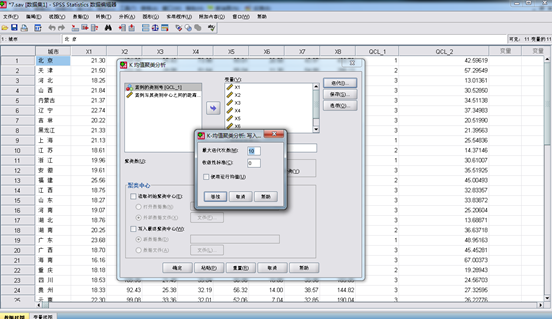
在spss中依次点击“analyze,classify,k-means cluster”,打开k-means cluster analysis对话框,将8个变量选入variable框中,将表示地区的变量选入label cases by 栏中,将分类数定为3.另外,点击iterate按钮可以在其中输入最大迭代次数和收敛标准;在save中按钮中可以选择保存样本的聚类结果和各样本距各自中心点的距离。过程如下:
1.打开k-means cluster analysis对话框。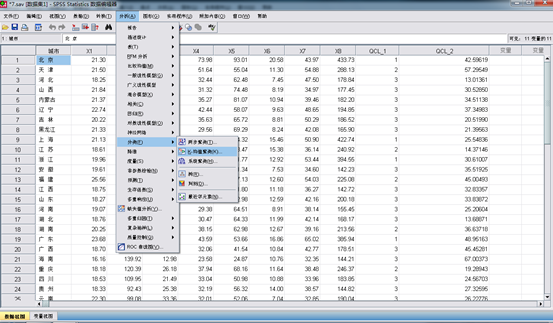
2. 将8个变量选入variable框中
3.选择最大迭代次数
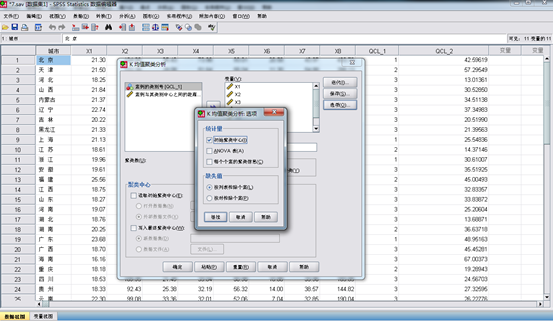
4.输出结果
六、实验结果与分析
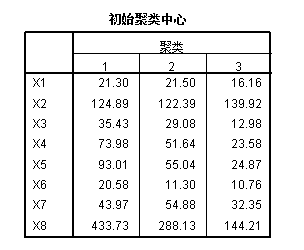
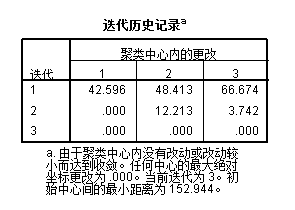
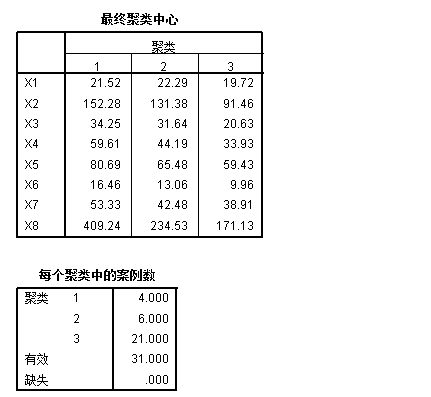
其中第一个表显示了3个类的初始类中心情况,可以看出,第一类的各指标值总体上是最优的,往下依次为第二类和第三类。第二个表展示了3个类中心点每次迭代的偏移情况,可知第一次迭代3个类中心点分别偏移了42.593,416,66.676,直到第三一迭代3个类的中心点偏移才达到指定判定标准(0)。第三个表展示了3个类的最终类中心情况,总体来看,第一类各指标值仍是最优的。最后一个表给出了各类中的样品数目,第一类包括4个地区,第二类包括6个地区,第三类包括21个地区。
第二篇:数据分析实验报告8 主成分分析
实验八 主成分分析
一、实验目的和要求
能利用原始数据与相关矩阵、协主差矩阵作主成分分析,并能理解标准化变量主成分与原始数据主成分的联系与区别;
能根据SAS输出结果选出满足要求的几个主成分.
实验要求:编写程序,结果分析.
实验内容:书上4.5 4.6
4.5 data examp4_5;
input id x1-x8;
cards;
1 8.35 23.53 7.51 8.62 17.42 10.00 1.04 11.21
2 9.25 23.75 6.61 9.19 17.77 10.48 1.72 10.51
3 8.19 30.50 4.72 9.78 16.28 7.60 2.52 10.32
4 7.73 29.20 5.42 9.43 19.29 8.49 2.52 10.00
5 9.42 27.93 8.20 8.14 16.17 9.42 1.55 9.76
6 9.16 27.98 9.01 9.32 15.99 9.10 1.82 11.35
7 10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.81
8 9.09 28.12 7.40 9.62 17.26 11.12 2.49 12.65
9 9.41 28.20 5.77 10.80 16.36 11.56 1.53 12.17
10 8.70 28.12 7.21 10.53 19.45 13.30 1.66 11.96
11 6.93 29.85 4.54 9.49 16.62 10.65 1.88 13.61
12 8.67 36.05 7.31 7.75 16.67 11.68 2.38 12.88
13 9.98 37.69 7.01 8.94 16.15 11.08 0.83 11.67
14 6.77 38.69 6.01 8.82 14.79 11.44 1.74 13.23
15 8.14 37.75 9.61 8.49 13.15 9.76 1.28 11.28
16 7.67 35.71 8.04 8.31 15.13 7.76 1.41 13.25
17 7.90 39.77 8.49 12.94 19.27 11.05 2.04 13.29
18 7.18 40.91 7.32 8.94 17.60 12.75 1.14 14.80
19 8.82 33.70 7.59 10.98 18.82 14.73 1.78 10.10
20 6.25 35.02 4.72 6.28 10.03 7.15 1.93 10.39
21 10.60 52.41 7.70 9.98 12.53 11.70 2.31 14.69
22 7.27 52.65 3.84 9.16 13.03 15.26 1.98 14.57
23 13.45 55.85 5.50 7.45 9.55 9.52 2.21 16.30
24 10.85 44.68 7.32 14.51 17.13 12.08 1.26 11.57
25 7.21 45.79 7.66 10.36 16.56 12.86 2.25 11.69
26 7.68 50.37 11.35 13.30 19.25 14.59 2.75 14.87
27 7.78 48.44 8.00 20.51 22.12 15.73 1.15 16.61
28 7.94 39.65 20.97 20.82 22.52 12.41 1.75 7.90
29 8.28 64.34 8.00 22.22 20.06 15.12 0.72 22.89
30 12.47 76.39 5.52 11.24 14.52 22.00 5.46 25.50
;
run;
proccorr cov nosimple data=examp4_5;
var x1-x8;
run;
procprincomp data=examp4_5 prefix=y out=bb;
var x1-x8;
run;
procplot data=bb;
plot y2*y1 $ id='*';
procsort data=bb;
by descending y1;
run;
procprint data=bb;
var id y1 y2 x1-x8;
run;
输出结果:
1、样本相关系数矩阵
Correlation Matrix
x1 x2 x3 x4 x5 x6 x7 x8
x1 1.0000 0.3336 -.0545 -.0613 -.2894 0.1988 0.3487 0.3187
x2 0.3336 1.0000 -.0229 0.3989 -.1563 0.7111 0.4136 0.8350
x3 -.0545 -.0229 1.0000 0.5333 0.4968 0.0328 -.1391 -.2584
x4 -.0613 0.3989 0.5333 1.0000 0.6984 0.4679 -.1713 0.3128
x5 -.2894 -.1563 0.4968 0.6984 1.0000 0.2801 -.2083 -.0812
x6 0.1988 0.7111 0.0328 0.4679 0.2801 1.0000 0.4168 0.7016
x7 0.3487 0.4136 -.1391 -.1713 -.2083 0.4168 1.0000 0.3989
x8 0.3187 0.8350 -.2584 0.3128 -.0812 0.7016 0.3989 1.0000
2、调用主成分分析的princomp过程,从相关系数矩阵出发进行主成分分析,输出集bb
The PRINCOMP Procedure
Observations 30
Variables 8
Simple Statistics
x1 x2 x3 x4
Mean 8.706666667 39.05600000 7.629000000 10.86566667
StD 1.614728190 12.43875828 3.052716540 3.89495579
Simple Statistics
x5 x6 x7 x8
Mean 16.58900000 11.62600000 1.902000000 13.06100000
StD 2.99785481 3.05810805 0.851576226 3.64707096
1)样本相关系数矩阵R的特征值、各主成分贡献率及累计贡献率
Eigenvalues of the Correlation Matrix
特征值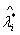 Difference 贡献率% 累计贡献率%
Difference 贡献率% 累计贡献率%
1 3.09628829 0.72906522 0.3870 0.3870
2 2.36722307 1.44723572 0.2959 0.6829已达68.29%
3 0.91998735 0.21406199 0.1150 0.7979
4 0.70592536 0.20748303 0.0882 0.8862
5 0.49844233 0.26855403 0.0623 0.9485
6 0.22988831 0.09911254 0.0287 0.9772
7 0.13077577 0.07930623 0.0163 0.9936
8 0.05146954 0.0064 1.0000
SAS 系统 14:09 Monday, October 22, 2001 22
The PRINCOMP Procedure
2)样本相关系数矩阵R特征值的正交化特征向量
The SAS System 17:30 Tuesday, October 26, 2012 4
The PRINCOMP Procedure
Eigenvectors
y1 y2 y3 y4 y5 y6 y7 y8
x1 0.249607 -.241238 0.693918 -.376770 0.502313 -.018418 -.036543 0.045052
x2 0.519234 -.037607 -.071261 -.224871 -.424453 0.001760 -.282467 0.642950
x3 -.018480 0.475439 0.577819 0.032379 -.510472 -.173344 0.381416 -.050854
x4 0.254092 0.538081 -.021777 -.231066 0.010358 0.399113 -.471680 -.458432
x5 0.021695 0.575449 -.048087 0.285368 0.516270 0.146109 0.159192 0.520977
x6 0.492663 0.134676 -.145348 0.224222 0.177156 -.754966 -.081452 -.244442
x7 0.317147 -.260682 0.286391 0.768116 -.090759 0.355165 -.130720 -.089297
x8 0.509332 -.087081 -.271279 -.176990 0.026015 0.304720 0.708416 -.180821
3)按第一主成分对各省份进行排序
The SAS System 17:30 Tuesday, October 26, 2012 6
Obs id y1 y2 x1 x2 x3 x4 x5 x6 x7 x8
1 30 6.89591 -2.27833 12.47 76.39 5.52 11.24 14.52 22.00 5.46 25.50
2 29 3.24842 2.56095 8.28 64.34 8.00 22.22 20.06 15.12 0.72 22.89
3 27 1.79214 2.88809 7.78 48.44 8.00 20.51 22.12 15.73 1.15 16.61
4 26 1.51507 1.37353 7.68 50.37 11.35 13.30 19.25 14.59 2.75 14.87
5 23 1.40116 -3.17840 13.45 55.85 5.50 7.45 9.55 9.52 2.21 16.30
6 21 1.15390 -1.37420 10.60 52.41 7.70 9.98 12.53 11.70 2.31 14.69
7 22 1.05651 -1.23524 7.27 52.65 3.84 9.16 13.03 15.26 1.98 14.57
8 24 0.43543 0.47409 10.85 44.68 7.32 14.51 17.13 12.08 1.26 11.57
9 25 0.15329 0.11320 7.21 45.79 7.66 10.36 16.56 12.86 2.25 11.69
10 17 0.04520 0.98056 7.90 39.77 8.49 12.94 19.27 11.05 2.04 13.29
11 28 -0.13324 4.90844 7.94 39.65 20.97 20.82 22.52 12.41 1.75 7.90
12 18 -0.13489 0.34363 7.18 40.91 7.32 8.94 17.60 12.75 1.14 14.80
13 19 -0.14112 0.68197 8.82 33.70 7.59 10.98 18.82 14.73 1.78 10.10
14 12 -0.17044 -0.58962 8.67 36.05 7.31 7.75 16.67 11.68 2.38 12.88
15 8 -0.39220 -0.29562 9.09 28.12 7.40 9.62 17.26 11.12 2.49 12.65
16 10 -0.43040 0.64570 8.70 28.12 7.21 10.53 19.45 13.30 1.66 11.96
17 14 -0.51802 -0.55227 6.77 38.69 6.01 8.82 14.79 11.44 1.74 13.23
18 9 -0.61274 -0.28257 9.41 28.20 5.77 10.80 16.36 11.56 1.53 12.17
19 13 -0.66670 -0.29548 9.98 37.69 7.01 8.94 16.15 11.08 0.83 11.67
20 11 -0.81850 -0.42128 6.93 29.85 4.54 9.49 16.62 10.65 1.88 13.61
21 7 -1.11335 -0.01815 10.06 28.64 10.52 10.05 16.18 8.39 1.96 10.81
22 15 -1.11496 -0.44043 8.14 37.75 9.61 8.49 13.15 9.76 1.28 11.28
23 6 -1.18223 -0.19296 9.16 27.98 9.01 9.32 15.99 9.10 1.82 11.35
24 2 -1.25819 -0.13224 9.25 23.75 6.61 9.19 17.77 10.48 1.72 10.51
25 16 -1.25934 -0.42827 7.67 35.71 8.04 8.31 15.13 7.76 1.41 13.25
26 3 -1.29370 -0.86033 8.19 30.50 4.72 9.78 16.28 7.60 2.52 10.32
27 4 -1.32567 -0.10239 7.73 29.20 5.42 9.43 19.29 8.49 2.52 10.00
28 5 -1.48595 -0.35156 9.42 27.93 8.20 8.14 16.17 9.42 1.55 9.76
29 1 -1.68448 0.16743 8.35 23.53 7.51 8.62 17.42 10.00 1.04 11.21
30 20 -1.96091 -2.10827 6.25 35.02 4.72 6.28 10.03 7.15 1.93 10.3
由输出结果可以看出:前两个主成分的累计贡献率已达68.29%,因此,取前两个主成分做进一步分析即可.给出了对应于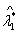 和
和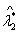 的正交单位化特征向量
的正交单位化特征向量 和
和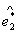 ,由此得到标准化指标的前两个样本主成分为
,由此得到标准化指标的前两个样本主成分为
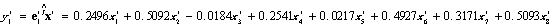
为8个指标加权平均,反映各省份在生活基本消费的消费水平能力的综合指标.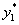 值大,则各省份的生活水平越低,
值大,则各省份的生活水平越低,

反映各省份在生活消费品德消费能力综合指标, 值大,则各省份的消费水平越高。第一主成分样本得分降序排列依次为:广东 上海 北京 浙江 海南 福建 广西 天津 江苏 辽宁 西藏 四川 山东 湖北 河北 宁夏 湖南 陕西 云南 新疆 青海 安徽 甘肃 内蒙古 贵州 吉林 黑龙江 河南 山西 江西 。
值大,则各省份的消费水平越高。第一主成分样本得分降序排列依次为:广东 上海 北京 浙江 海南 福建 广西 天津 江苏 辽宁 西藏 四川 山东 湖北 河北 宁夏 湖南 陕西 云南 新疆 青海 安徽 甘肃 内蒙古 贵州 吉林 黑龙江 河南 山西 江西 。
4.6
data examp4_6;
input id x1-x3 y1-y3;
cards;
1 60 69 62 97 69 98
2 56 53 84 103 78 107
3 80 69 76 66 99 130
4 55 80 90 80 85 114
5 62 75 68 116 130 91
6 74 64 70 109 101 103
7 64 71 66 77 102 130
8 73 70 64 115 110 109
9 68 67 75 76 85 119
10 69 82 74 72 133 127
11 60 67 61 130 134 121
12 70 74 78 150 158 100
13 66 74 78 150 131 142
14 83 70 74 99 98 105
15 68 66 90 119 85 109
16 78 63 75 164 98 138
17 103 77 77 160 117 121
18 77 68 74 144 71 153
19 66 77 68 77 82 89
20 70 70 72 114 93 122
21 75 65 71 77 70 109
22 91 74 93 118 115 150
23 66 75 73 170 147 121
24 75 82 76 153 132 115
25 74 71 66 143 105 100
26 76 70 64 114 113 129
27 74 90 86 73 106 116
28 74 77 80 116 81 77
29 67 71 69 63 87 70
30 78 75 80 105 132 80
31 64 66 71 83 94 133
32 71 80 76 81 87 86
33 63 75 73 120 89 59
34 90 103 74 107 109 101
35 60 76 61 99 111 98
36 48 77 75 113 124 97
37 66 93 97 136 112 122
38 74 70 76 109 88 105
39 60 74 71 72 90 71
40 63 75 66 130 101 90
41 66 80 86 130 117 144
42 77 67 74 83 92 107
43 70 67 100 150 142 146
44 73 76 81 119 120 119
45 78 90 77 122 155 149
46 73 68 80 102 90 122
47 72 83 68 104 69 96
48 65 60 70 119 94 89
49 52 70 76 92 94 100
;
run;
proccorr cov nosimple data=examp4_6;
var x1-x3 y1-y3;
run;
procprincomp data=examp4_6 prefix=y out=bb;
var x1-x3 y1-y3;
run;
procprincomp cov data=examp4_6;
var x1-x3 y1-y3;
run;
procsort data=bb;
by descending y1;
run;
输出结果:
1、调用主成分分析的princomp过程,从相关系数矩阵出发进行主成分分析,输出集bb
1)样本相关系数矩阵R的特征值、各主成分贡献率及累计贡献率
Eigenvalues of the Correlation Matrix
Eigenvalue Difference Proportion Cumulative
1 2.12157166 1.03736370 0.3536 0.3536
2 1.08420796 0.08624620 0.1807 0.5343
3 0.99796176 0.12628298 0.1663 0.7006
4 0.87167877 0.29225146 0.1453 0.8459
5 0.57942731 0.23427477 0.0966 0.9425
6 0.34515254 0.0575 1.0000
2)样本相关系数矩阵R特征值的正交化特征向量
Eigenvectors
y1 y2 y3 y4 y5 y6
x1 0.344625 0.148721 0.454179 0.739380 0.146362 -.291088
x2 0.261813 0.843332 -.066937 -.051728 -.115485 0.446936
x3 0.368141 0.050250 0.487105 -.643235 0.410527 -.205892
y1 0.469630 -.325477 -.395013 0.153628 0.548470 0.439382
y2 0.491950 0.085830 -.552875 -.096822 -.253064 -.609535
y3 0.463241 -.388389 0.300440 -.062561 -.657151 0.329446
2、调用主成分分析的princomp过程,从协方差阵出发进行主成分分析
1)样本协方差矩阵R的特征值、各主成分贡献率及累计贡献率
Eigenvalues of the Covariance Matrix
Eigenvalue Difference Proportion Cumulative
1 1097.39817 699.40213 0.5423 0.5423
2 397.99604 84.89703 0.1967 0.7390
3 313.09901 213.35419 0.1547 0.8938
4 99.74482 29.62682 0.0493 0.9431
5 70.11800 25.02504 0.0347 0.9777
6 45.09295 0.0223 1.0000
2)样本协方差矩阵S按特征值排序的正交化特征向量
Eigenvectors
Prin1 Prin2 Prin3 Prin4 Prin5 Prin6
x1 0.081187 0.094302 -.080439 0.802063 -.459078 -.352119
x2 0.034375 -.009438 0.205320 0.521972 0.284379 0.776690
x3 0.073061 0.123097 -.018842 0.248178 0.835060 -.469294
y1 0.758211 -.450482 -.462969 -.013878 0.038012 0.078765
y2 0.513429 -.025888 0.834850 -.082970 -.085629 -.156621
y3 0.385221 0.878784 -.199257 -.124786 -.047691 0.147627
3、结果分析
由输出结果可以看出:从协方差阵出发进行主成分分析,前三个主成分的累计贡献率已达89.38%,因此,取前三个主成分做进一步分析即可.给出了正交单位化特征向量,由此得到标准化指标的前三个样本主成分为
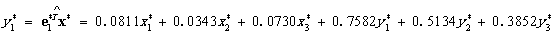
反映各位女生在三个不同时刻下空腹与摄入等量食糖后血糖化,在空腹时,不同时刻由于身体内的调节,血糖变化不大,在摄入糖以后,第一个时刻血糖浓度增大。即大,摄入糖以后,血糖增大。
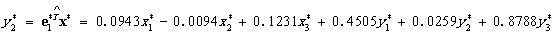
反映各位女生在三个不同时刻下空腹与摄入等量食糖后血糖化,在空腹时,不同时刻由于身体内的调节,血糖变化不大,在摄入糖以后,第三个时刻血糖浓度增大。即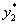 大,摄入糖以后,血糖最大。
大,摄入糖以后,血糖最大。
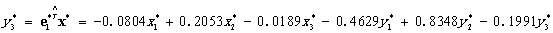
反映各位女生在三个不同时刻下空腹与摄入等量食糖后血糖化,在空腹时,不同时刻由于身体内的调节,血糖变化不大,在摄入糖以后,第三个时刻血糖浓度由于身体调节血糖减少。即 大,摄入糖以后随着时间的增加,血糖减少。
大,摄入糖以后随着时间的增加,血糖减少。
由输出结果可以看出:从相关系数矩阵出发进行主成分分析,前四个主成分的累计贡献率已达84.59%,因此,取前四个主成分做进一步分析即可.给出了正交单位化特征向量,由此得到标准化指标的前四个样本主成分为
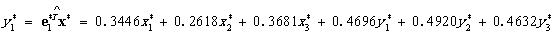



由相关系数矩阵看出,各变量之间差距很大,而且提取的主成分可以看出,实验效果有差距。所以基于S的分析结果更为合理。
-
现代实验分析报告
水泥中MgOCaOAl2O3Fe2O3含量的测定一实验目的1学习复杂物质分析的方法2掌握尿素均匀沉淀法二实验原理本实验采用硅酸盐水…
-
实验结果分析报告
1亚硝酸钠测定结果标准液质量与吸光度表亚硝酸钠标准液质量000123457510125吸光度0002600430068005701…
-
实验报告 范本
研究生实验报告范本实验课程实验名称实验地点学生姓名学号指导教师范本实验时间年月日一实验目的熟悉电阻型气体传感器结构及工作原理进行基…
-
程序分析实验报告
程序分析第二次实验报告13091372代树理开发环境语言java编译器myeclipse操作系统windowsXP另外使用的ANT…
-
实验报告(相关分析)
经济分析方法与手段实验分析报告附件一1陶瓷产量与城镇住宅建筑面积的相关分析散点图2与新增医疗卫生机构面积的关系3与新增办公楼面积的…
-
分析化学实验 氢氧化钠溶液浓度的标定 实验报告
实验报告姓名班级同组人项目氢氧化钠标准溶液浓度的标定课程分析化学学号一实验目的1学会称量瓶电子天平滴定管等常用滴定仪器的准备和使用…
-
哈工大数值分析上机实验报告 20xx年
实验报告一题目Gauss列主元消去法摘要求解线性方程组的方法很多主要分为直接法和间接法本实验运用直接法的Guass消去法并采用选主…
- 数值分析实验报告1
-
西安交大编译原理语法分析器实验报告
编译原理课内实验报告学生姓名石磊专业班级计算机26学号2120xx5140所在学院电信学院提交日期20xx122一实验目的1强化对…
-
实验15 光亮镀锌及化学镀镍实验报告
光亮镀锌及化学镀镍1实验目的11学习和实践氯化钾光亮镀锌的实验室基本操作流程了解电镀的基本原理和工艺12学习并掌握化学镀镍的原理及…
- 因子分析实验报告范本