数据挖掘实验报告
机器学习与数据挖掘
学生姓名:
学 号:6008
专 业:计算机科学与技术
班 级:计算机2084班
1实验内容
(1)在C4.5算法中数据集大小与精度之间的关系
(2)属性个数对该关系的影响
2实验思路
实验要求探究数据集大小与C4.5精度的关系以及数据属性个数对这个关系的影响。对于第一个问题来说,影响算法精度的因素很多,数据集大小只是其中的一个。在研究训练集对算法精度影响实验中要求固定其他影响因素,即在实验中分析训练集大小与C4.5精度的关系时,对训练集进行多次不同随机采样,采用同样的测试集测试模型精度并记录每次测试的结果,最后分析比较得出结论。在研究测试集对算法精度影响时,采用同样的训练集对测试集进行不同的抽样得到不同的测试集,然后进行测试并记录结果,对结果进行归纳总结得出结论。对于第二个问题,使用同一个数据集,采用带筛选器的分类器,对处理后的数据进行10重交叉验证,记录所得精度,修改筛选器的抽样比率,得到不同的数据集,重复实验,比较得最后的结论。
此次试验要求采用多组数据进行相同的测试,最后分析归纳得出结论。
3实验过程
对实验数据进行预处理,将数据中的数值型数据转变为离散型数据。使用weka.filters.unsupervised.attribute.Discretize将数据集中的数据离散化。选中Choose中的Discretize得到图2的界面进行参数设置attributeIndices设置的是想要离散化属性的标号,bins设置将属性离散为几个离散值。这里设置的是将第1,5,10个属性分别离散到三个数据段内。点击确定返回主页面并点击Apply完成离散化。
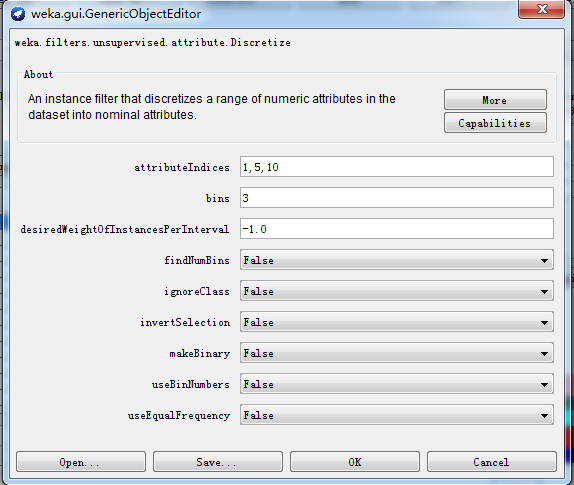
图1
3.1数据集大小与精度之间的关系
3.1.1训练集大小与C4.5算法精度之间的关系
以训练集au7_train.arff,实例个数1100,属性个数13为例进行实验过程:
(1)打开训练集au7_train.arff选择ReservoirSample筛选器,筛选器路径为weka.filters.unsupervised.instance.ReservoirSample对原训练集进行处理,对原训练数据集进行无监督的随机抽样,选中ReservoirSample进行参数设置得到图2,将sampleSize属性设置为100,点击确定返回主页面并点击Apply即抽取100个数据作为新的训练数据集。

图2
(2)切换到分类界面选择weka.classifiers.trees.J48分类器并选中Supplied test set选项,点击set打开测试集进行测试如图3

图3
(3)测试完成后得到图4的结果我们可以看到当训练集为100时得到的精度为27.4%。这个结果相对来说比较低。
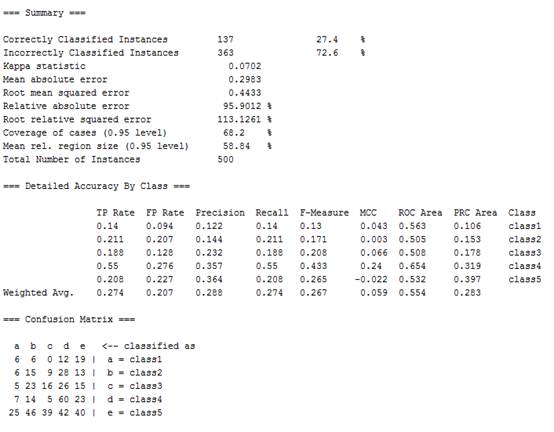
图4
(4)重新加载au7_train.arff训练集,修改抽样个数,重复试验得到如下数据:

(5)对其他数据进行同样的实验得到下列数据:
数据集bank_train.arff,实例个数452111,属性个数17

数据集userprofole_train.arff,实例个数138,属性个数16

数据集column_2C_weka1_train.arff,实例个数310,属性个数7

由以上数据可以得出结论:
算法精度随着数据集的增加而增大,当训练数据集规模增大到一定程度时,建立模型的精度不会再持续增大,且最大分类精度不会超过模型对训练数据的拟合度。
3.1.2测试集与C4.5算法精度之间的关系
按照3.1.1实验中的方法把测试集进行随机抽样,并保存为新的测试集。修改随机抽样的数量得到不同的测试集,对不同的测试集选用相同的训练集进行J48分类,得到如下数据:
训练集au7_train.arff,实例个数1100,属性13
测试集au7_test.arff,实例个数500,属性13

训练集bank_train.arff,实例个数452111,属性个数17
测试集bank_train.arff,实例个数4521,属性个数17

训练集column_2C_weka1_train.arff,实例个数310,属性个数7
测试集column_2C_weka1_train.arff,实例个数100,属性个数7

由以上数据我们可以得出结论:
当数据集过小时精度的变化幅度较大因此没有代表性,当测试集的规模达到一定数量时,算法的精度趋于稳定并在一个很小的范围内上下浮动。
3.2属性个数对数据集大小与精度关系的影响
以数据集au4.arrf为例讲解实验过程:
(1)对数据不做预处理直接打开数据集au4,并进入分类器界面。
(2)选择weka.classifiers.meta.FilteredClassifier分类器如图5所示:

图5
(3)单击choose右边的白框,并选择filter的choose选项选出下面选项weka.filters.unsupervised.attribute.RandomSubset如图6所示:

图6
(4)单击filter边上的白框设置参数,将numAttributes的值设置为0.1即筛选器的抽样比率为10%点击OK确定。

图7
(5)返回分类器界面点击Start按钮开始对数据集进行处理,并得到图8的结果:
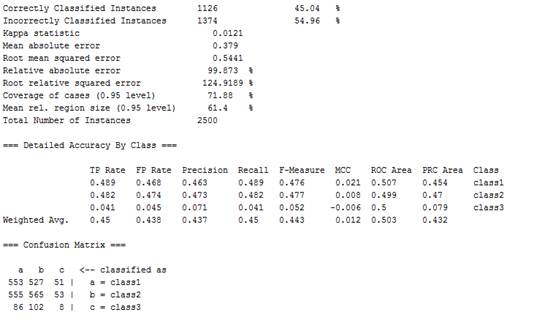
图8
我们从上图可以看出这个模型的精度为45.04%
(6)设置不同的抽样比率对数据进行处理得到如下的数据:

(7)以同样的方法得到如下数据:
数据集au5.arff,实例个数2500,属性个数42

数据集au6.arff,实例个数1000,属性个数41

数据集batch10.arff,实例个数3600,属性个数129

由以上数据可以得出结论:
当时实力的属性个数过少时,模型的精度会比较低。随着属性个数的增多模型的精度也会增加。
第二篇:股票信息数据挖掘实验报告
广东外语外贸大学信息科学技术学院
股票信息数据挖掘实验报告
日期:20##-1-7
一、摘要
数据挖掘是数据库应用和研究的一个新领域,其目标是通过对历史数据的分析统计得出用户感兴趣的结果。在股票交易事务处理中,每天有以交易信息为主的大量数据汇入数据仓库,这些数据无疑对股民了解股市的走势,做出正确的投资决策;经济学家分析不同层次用户的投资行为和各种股票之间的关系,以及及时发现股市中的非正常行为;各上市公司和政府部门出台新的方案等诸多方面具有重要的参考价值。
作为市场经济重要特征的股票市场,从诞生的那天起就牵挂着数以千万投资者的心。高风险高回报是股票市场的特征,因此投资者们时刻在关心股市、分析股市、试图预测股市的发展趋势。一百多年来,一些分析方法随着股市的产生和发展逐步完善起来,如:道氏分析法、K线图分析法、柱状图分析法、点数图分析法、移动平均法,还有形态分析法、趋势分析法、角度分析法、神秘级数与黄金分割比螺旋历法、四度空间法等,随着计算机技术在证券分析领域的普及与应用,不断推出新的指标分析法。然而,严格讲这些方法仅仅是分析手段,还不能直接预测股市的动态。此外,人们也试图用回归分析等统计手段建立模型来预测股市。然而,利用传统的预测技术进行股市预测有一个最根本的困难,那就是待处理的数据量非常巨大。由于股市的行情受到政治、经济等多方面因素的影响,其内部规律非常复杂,某些变化规律的周期可能是一年甚至是几年,因此需要通过对大量数据的分析才能得到,而传统的预测技术预测效果并不理想。
近十年间,数据挖掘技术的研究工作取得了很大的进展,各种数据挖掘技术的应用极大地推动了人们分析、处理大量数据信息的能力,并为人们带来了很好的经济效益,因此可以预见数据挖掘技术在股市预测中将会有很大的潜力。
二、研究内容
本实验以数据挖掘技术为基础,对股票的走势进行分析预测。目标为使用数据挖掘中的几种常用方法建立预测模型,通过对预测过程及预测结果的分析,来寻求数据挖掘算法与股票预测的结合点。通过对近四年的股票全景与个股的分析,经过预处理后用weka对数据进行分类与关联的进一步挖掘,实地体验数据挖掘在股票预测领域起的作用。
三、数据挖掘过程
数据挖掘是一个反复的过程,包含多个相互联系的步骤,如定义和分析主题、数据预处理、选取算法、提取规则、评价和解释结果、将模式构成知识,最后是应用。
1.问题定义
进行数据挖掘前,首先要分析股票领域,了解股票领域的有关情况,熟悉背景知识。在确定需求后,对现有资源如已有的历史数据进行评估,确定是否能够通过数据挖掘技术来满足需求,然后将进一步确定数据挖掘的目标和制定数据挖掘计划。
2.数据准备
数据挖掘所处理的数据集通常不仅具有海量数据,而且可能存在大量的噪声数据、冗余数据、稀疏数据或不完全数据等。数据准备包括数据抽取、清洗、转换、和加载,具体包括数据的清洗、集成、选择、变换、规约,以及数据的质量分析等步骤。
3.建立模型
数据挖掘中的建模实际上就是利用己知的数据和知识建立一种模型,这种模型可以有效地描述已知的数据和知识,希望该模型能有效地应用到未知的数据或相似情况中。在数据挖掘中,可以使用许多不同的模型:关联规则模型、决策树模型、神经网络模型、粗糙集模型、数理统计模型、时间序列分析模型。
4.评价模型
数据挖掘得到的模式有可能是没有实际意义或没有实用价值的,也有可能不能准确反映数据真实意义,甚至在某些情况下是与事实相反的,因此对于数据挖掘的结果需要进行评估。确定数据挖掘是否存在偏差,挖掘结果是否正确,确定哪些是有效的、有用的模式,是否能满足需求。
5.评估
评估的方法一种是直接使用原先建立的挖掘数据库中的数据来进行检验,也可以另找新的测试数据并对其进行检验,另一种办法是使用实际运行环境中的当前数据进行检验。
四、挖掘成果
1.用分类C4.5算法挖掘股票全景数据集(2010.12.28-2011.01.04)
(1)原始数据集
日期 代码 名称 涨幅%% 现价 日涨跌 买入价 卖出价 ……
20101227 000001 深发展A -2.25 16.07 -0.37 16.07 16.08
20101227 000002 万 科A -2.89 8.75 -0.26 8.74 8.75
20101227 000004 ST国农 -2.99 11.7 -0.36 11.7 11.72
20101227 000005 世纪星源 -3.58 3.77 -0.14 3.77 3.78
20101227 000006 深振业A -4.71 7.28 -0.36 7.27 7.28
20101227 000007 ST零七 -1.83 8.58 -0.16 8.58 8.59
20101227 000008 ST宝利来 -2 11.78 -0.24 11.77 11.79
20101227 000009 中国宝安 -4.44 16.15 -0.75 16.14 16.15
……
共12047条记录,20维属性。经过多次数据预处理,得到数据集如下:
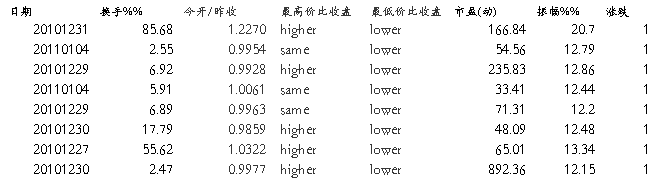
……
共11632条记录,8维属性。挖掘结果如下:
置信因数取0.1
Number of Leaves : 26
Size of the tree : 47


准确率85%
取置信因数1.0E-4
Number of Leaves : 13
Size of the tree : 21

准确率约85%,并且当置信因数继续往小取时,分支数不再改变。
2.用聚类Apriori算法挖掘个股000005世纪星源(2006.01.12-2010.12.24)
(1)原始数据集
日期 开盘 最高 最低 收盘 成交量 成交额
20##-1-11 1.03 1.04 1.02 1.03 3372554 5725193.5
20##-1-12 1.02 1.04 1.01 1.04 4091492 6919504
20##-1-13 1.04 1.05 1.02 1.03 3262149 5545958.5
20##-1-16 1.04 1.04 1.01 1.02 3196712 5400217
20##-1-17 1.01 1.05 1 1.04 4720177 8044688
20##-1-18 1.04 1.05 1.03 1.04 5126617 8774786
……
共1106条记录,7维属性。经过多次数据预处理,得到数据集如下:
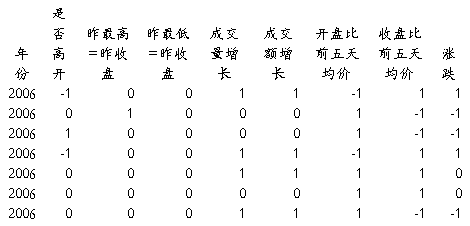
……
共1105条记录,9维属性。挖掘结果如下:

最小支持度取0.48,最小置信度取0.8。
.
五、结论
用分类C4.5算法挖掘股票全景数据集,经过多次数据预处理后,20维属性缩小到8维,但是对于一万多条数据的庞大且混乱的数据集来说,依然没什么特别的结果。这与我们的知识相吻合,股票的涨跌并不能用简单的规律挖掘就能得出结果。
用聚类Apriori算法挖掘个股000005世纪星源,个股对全领域的代表性有限,但是我们依然有一些小小的发现。成交额与成交量基本上是共同升降(98%、98%)的;大部分股票的收盘价都不是当天的最高价或最低价(92%、87%);成交量下降的股票,前一天不会在最低价收盘(92%),对成交额亦然(91%);开盘价创近五天均价新高,则前一天不会在最低价收盘(96%),对收盘价亦然(95%)。这些数据对股票预测也许没有决定性的影响,但也算是我们实验的一个小发现。
六、课程体会
数据挖掘是一门很有前景的学科,其预测、分类等功能广泛应用在各个领域。通过这一学期的学习,我们基本掌握了数据挖掘的基础技术,了解了数据挖掘的基本原理,并学会用weka进行简单的数据挖掘实验。但是实际操作并不如想象中那么简单,一个原始数据集,要从数据预处理开始一点一点地添加删减,拼造出可供挖掘的数据集,需要比较漫长的过程以及细心地调试。有时候一个很混乱或者高维的数据集不见得会挖出可观的结论。对于数据挖掘领域,我们需要学习的东西还有很多。感谢李霞老师一个学期以来的指导。
七、分工及自评
实验基本上合作完成,分工略有侧重。
:主要负责数据处理与实验,评分:95。
:主要负责前期资料收集整理,评分:95。
:主要负责后期文档编纂,评分:95。
-
数据挖掘实验报告
数据挖掘实验报告K最临近分类算法学号311062202姓名汪文娟一数据源说明1数据理解选择第二包数据IrisDataSet共有15…
- 数据挖掘实验报告
-
数据挖掘实验报告4
甘肃政法学院本科生实验报告四姓名贾燚学院计算机科学学院专业信息管理与信息系统班级10级信管班实验课程名称数据仓库与数据挖掘实验日期…
-
数据挖掘实验报告
数据挖掘实验报告药物研究专业学号姓名时间20xx1208数据挖掘实验报告药物分析一实验目的1学习数据挖掘的理论知识理解数据挖掘的目…
-
数据挖掘实验报告
计算机科学与技术系数据挖掘实验报告姓名学号授课教师完成时间1数据挖掘实验报告评分2目录1数据挖掘综述411什么是数据挖掘412数据…
-
《数据挖掘实训》weka实验报告
论文报告案例分析院系信息学院专业统计班级10级统计3班学生姓名李健学号20xx210453任课教师刘洪伟20xx年01月17日课程…
-
数据挖掘WEKA实验报告
数据挖掘WAKA实验报告数据挖掘WAKA实验报告1数据挖掘WAKA实验报告一WEKA软件简介在我所从事的证券行业中存在着海量的信息…
-
数据挖掘实验报告 Weka的数据聚类分析
甘肃政法学院本科生实验报告2姓名学院计算机科学学院专业信息管理与信息系统班级实验课程名称数据挖掘实验日期指导教师及职称实验成绩开课…
-
weka实验报告
数据挖掘实验报告基于weka的数据分类分析实验报告姓名学号1实验基本内容本实验的基本内容是通过使用weka中的三种常见分类方法朴素…
-
数据挖掘weka数据分类实验报告
一实验目的使用数据挖掘中的分类算法对数据集进行分类训练并测试应用不同的分类算法比较他们之间的不同与此同时了解Weka平台的基本功能…
-
数据挖掘实验报告
数据挖掘实验报告一实验名称有线电视服务销售CampR树二实验目的1学习和了解数据挖掘的基础知识学会使用SPSSClementine…