数据挖掘实验报告模板
湖南工程学院数据挖掘 实验报告

第二篇:数据挖掘实验报告
机器学习与数据挖掘
学生姓名:
学 号:6008
专 业:计算机科学与技术
班 级:计算机2084班
1实验内容
(1)在C4.5算法中数据集大小与精度之间的关系
(2)属性个数对该关系的影响
2实验思路
实验要求探究数据集大小与C4.5精度的关系以及数据属性个数对这个关系的影响。对于第一个问题来说,影响算法精度的因素很多,数据集大小只是其中的一个。在研究训练集对算法精度影响实验中要求固定其他影响因素,即在实验中分析训练集大小与C4.5精度的关系时,对训练集进行多次不同随机采样,采用同样的测试集测试模型精度并记录每次测试的结果,最后分析比较得出结论。在研究测试集对算法精度影响时,采用同样的训练集对测试集进行不同的抽样得到不同的测试集,然后进行测试并记录结果,对结果进行归纳总结得出结论。对于第二个问题,使用同一个数据集,采用带筛选器的分类器,对处理后的数据进行10重交叉验证,记录所得精度,修改筛选器的抽样比率,得到不同的数据集,重复实验,比较得最后的结论。
此次试验要求采用多组数据进行相同的测试,最后分析归纳得出结论。
3实验过程
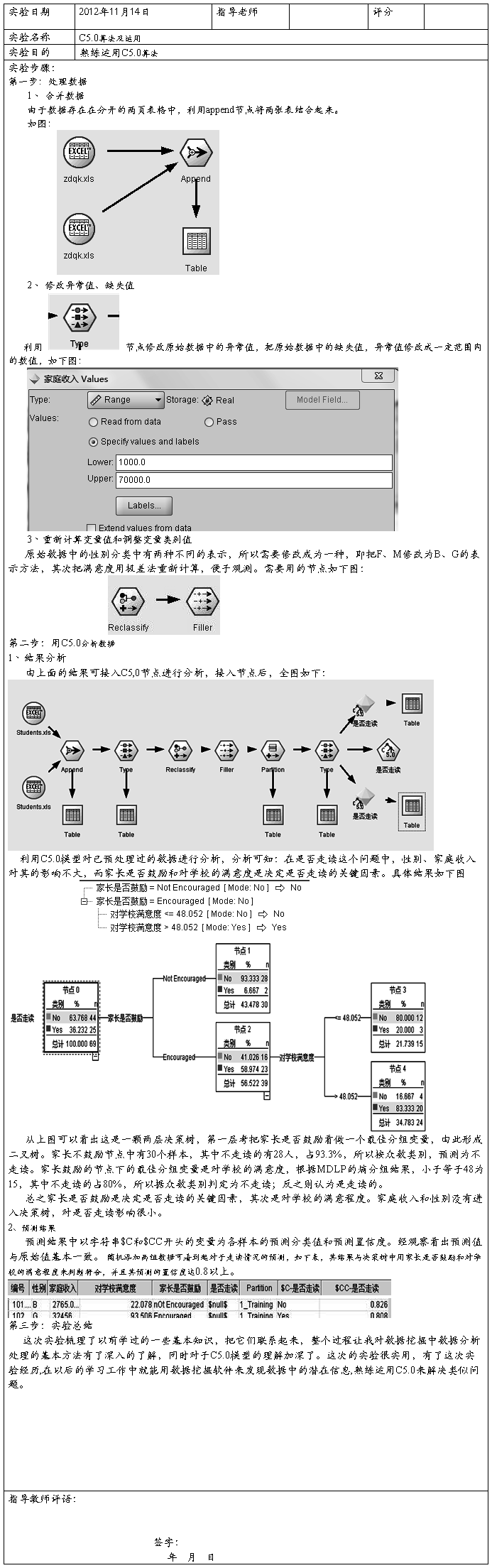
对实验数据进行预处理,将数据中的数值型数据转变为离散型数据。使用weka.filters.unsupervised.attribute.Discretize将数据集中的数据离散化。选中Choose中的Discretize得到图2的界面进行参数设置attributeIndices设置的是想要离散化属性的标号,bins设置将属性离散为几个离散值。这里设置的是将第1,5,10个属性分别离散到三个数据段内。点击确定返回主页面并点击Apply完成离散化。
图1
3.1数据集大小与精度之间的关系
3.1.1训练集大小与C4.5算法精度之间的关系
以训练集au7_train.arff,实例个数1100,属性个数13为例进行实验过程:
(1)打开训练集au7_train.arff选择ReservoirSample筛选器,筛选器路径为weka.filters.unsupervised.instance.ReservoirSample对原训练集进行处理,对原训练数据集进行无监督的随机抽样,选中ReservoirSample进行参数设置得到图2,将sampleSize属性设置为100,点击确定返回主页面并点击Apply即抽取100个数据作为新的训练数据集。

图2
(2)切换到分类界面选择weka.classifiers.trees.J48分类器并选中Supplied test set选项,点击set打开测试集进行测试如图3

图3
(3)测试完成后得到图4的结果我们可以看到当训练集为100时得到的精度为27.4%。这个结果相对来说比较低。
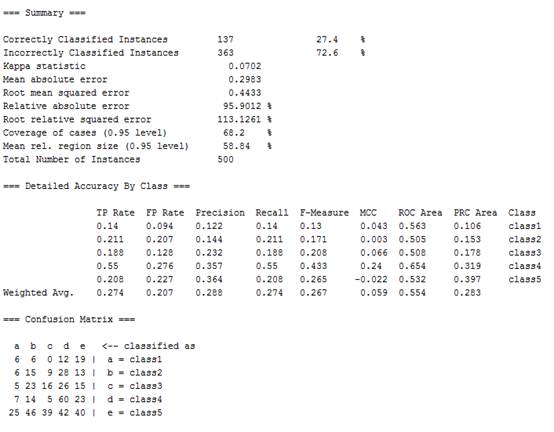
图4
(4)重新加载au7_train.arff训练集,修改抽样个数,重复试验得到如下数据:

(5)对其他数据进行同样的实验得到下列数据:
数据集bank_train.arff,实例个数452111,属性个数17

数据集userprofole_train.arff,实例个数138,属性个数16

数据集column_2C_weka1_train.arff,实例个数310,属性个数7

由以上数据可以得出结论:
算法精度随着数据集的增加而增大,当训练数据集规模增大到一定程度时,建立模型的精度不会再持续增大,且最大分类精度不会超过模型对训练数据的拟合度。
3.1.2测试集与C4.5算法精度之间的关系
按照3.1.1实验中的方法把测试集进行随机抽样,并保存为新的测试集。修改随机抽样的数量得到不同的测试集,对不同的测试集选用相同的训练集进行J48分类,得到如下数据:
训练集au7_train.arff,实例个数1100,属性13
测试集au7_test.arff,实例个数500,属性13

训练集bank_train.arff,实例个数452111,属性个数17
测试集bank_train.arff,实例个数4521,属性个数17

训练集column_2C_weka1_train.arff,实例个数310,属性个数7
测试集column_2C_weka1_train.arff,实例个数100,属性个数7

由以上数据我们可以得出结论:
当数据集过小时精度的变化幅度较大因此没有代表性,当测试集的规模达到一定数量时,算法的精度趋于稳定并在一个很小的范围内上下浮动。
3.2属性个数对数据集大小与精度关系的影响
以数据集au4.arrf为例讲解实验过程:
(1)对数据不做预处理直接打开数据集au4,并进入分类器界面。
(2)选择weka.classifiers.meta.FilteredClassifier分类器如图5所示:

图5
(3)单击choose右边的白框,并选择filter的choose选项选出下面选项weka.filters.unsupervised.attribute.RandomSubset如图6所示:

图6
(4)单击filter边上的白框设置参数,将numAttributes的值设置为0.1即筛选器的抽样比率为10%点击OK确定。

图7
(5)返回分类器界面点击Start按钮开始对数据集进行处理,并得到图8的结果:
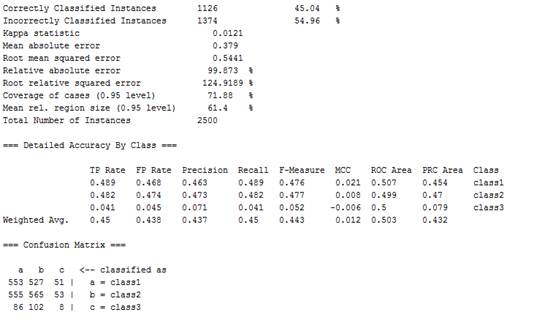
图8
我们从上图可以看出这个模型的精度为45.04%
(6)设置不同的抽样比率对数据进行处理得到如下的数据:

(7)以同样的方法得到如下数据:
数据集au5.arff,实例个数2500,属性个数42

数据集au6.arff,实例个数1000,属性个数41

数据集batch10.arff,实例个数3600,属性个数129

由以上数据可以得出结论:
当时实力的属性个数过少时,模型的精度会比较低。随着属性个数的增多模型的精度也会增加。
-
数据挖掘实验报告
数据挖掘实验报告K最临近分类算法学号311062202姓名汪文娟一数据源说明1数据理解选择第二包数据IrisDataSet共有15…
- 数据挖掘实验报告
-
数据挖掘实验报告4
甘肃政法学院本科生实验报告四姓名贾燚学院计算机科学学院专业信息管理与信息系统班级10级信管班实验课程名称数据仓库与数据挖掘实验日期…
-
数据挖掘实验报告
数据挖掘实验报告药物研究专业学号姓名时间20xx1208数据挖掘实验报告药物分析一实验目的1学习数据挖掘的理论知识理解数据挖掘的目…
-
数据挖掘实验报告
计算机科学与技术系数据挖掘实验报告姓名学号授课教师完成时间1数据挖掘实验报告评分2目录1数据挖掘综述411什么是数据挖掘412数据…
-
数据挖掘实验报告
数据挖掘实验报告一实验名称有线电视服务销售CampR树二实验目的1学习和了解数据挖掘的基础知识学会使用SPSSClementine…
-
《数据挖掘实训》weka实验报告
论文报告案例分析院系信息学院专业统计班级10级统计3班学生姓名李健学号20xx210453任课教师刘洪伟20xx年01月17日课程…
-
数据挖掘 报告正文
河南科技大学课程设计说明书课程名称软件项目综合实践题目图书借阅数据挖掘系统院系电子信息工程学院班级计科083学生姓名陈亚杰指导教师…
-
数据挖掘课程设计报告正文
目录第1章数据挖掘基本理论211数据挖掘的产生212数据挖掘的概念313数据挖掘的步骤3第2章系统分析421系统用户分析422系统…
-
数据挖掘课程设计报告
ID3算法的改进摘要本文基于ID3算法的原有思路再把属性的重要性程度值纳入了属性选择的度量标准中以期获得更适合实际应用的分类划分结…
-
数据挖掘读书报告
读书报告数据挖掘可以看成是信息技术自然化的结果。数据挖掘(Datamining),又译为资料探勘、数据采矿。它是数据库知识发现(K…